Data Analysis & Preprocessing
As we’ve seen, ML algorithms solve input-output tasks. And to solve an ML problem, we first need to collect data, understand it, and then transform (“preprocess”) it in such a way that ML algorithms can be applied:
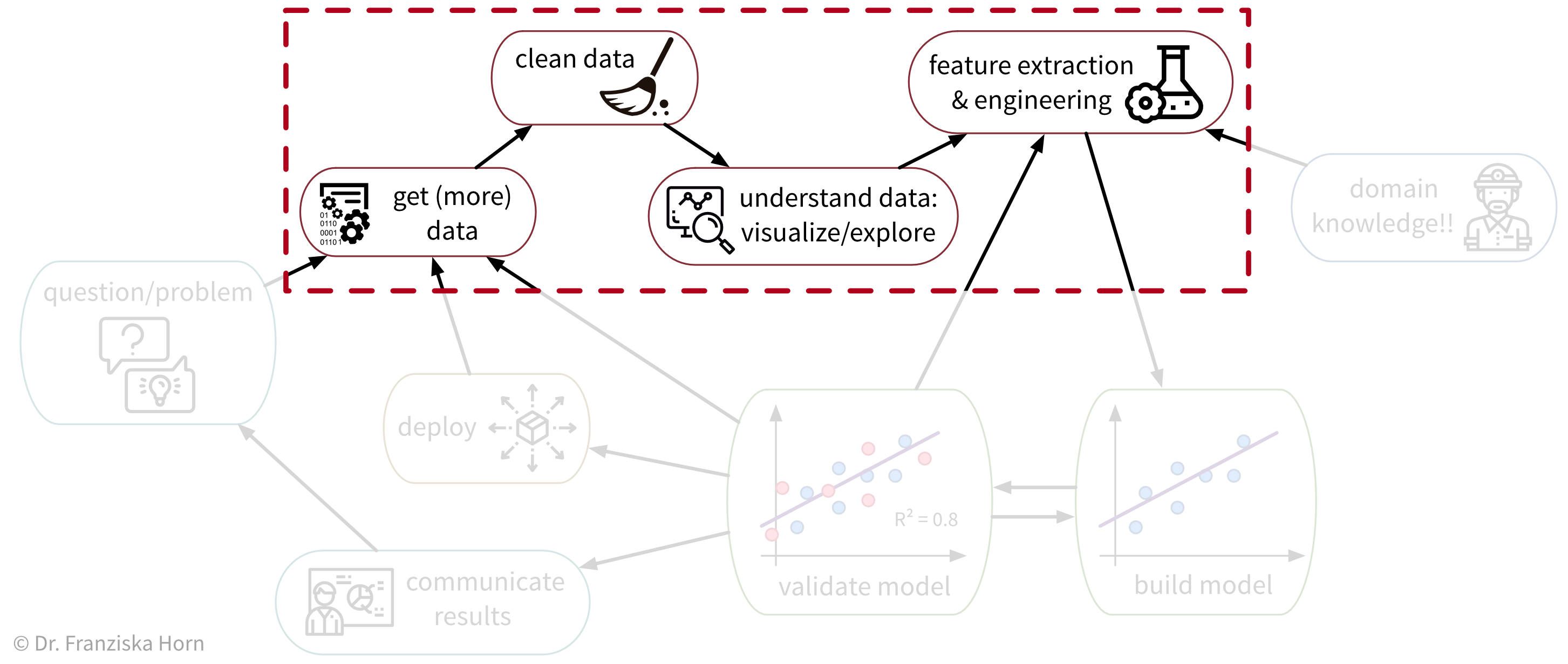
Data Analysis
Analyzing data is not only an important step before using this data for a machine learning project, but can also generate valuable insights that result in better (data-driven) decisions. We usually analyze data for one of two reasons:
- We need some specific information to make a (better) decision (reactive analysis, e.g., when something went wrong and we don’t know why).
- We’re curious about the data and don’t know yet what the analysis will bring (proactive analysis, e.g., to better understand the data at the beginning of an ML project).
Data analysis results can be obtained and communicated in different formats
- A custom analysis with results presented, e.g., in a power point presentation
- A standardized report, e.g., in form of a PDF document, showing static data visualizations of historical data
- A dashboard, i.e., a web app showing (near) real-time data, usually with some interactive elements (e.g., options to filter the data)

While the data story that is told in a presentation is usually fixed, users have more opportunities to interpret the data and analyze it for themselves in an interactive dashboard.
What all forms of data analyses have in common is that we’re after “(actionable) insights”.
What is an insight?
Psychologist Gary Klein defines an insight as “an unexpected shift in the way we understand things”.
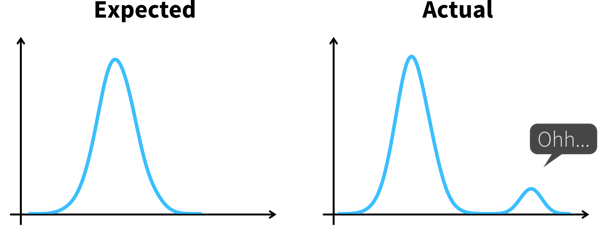
Arriving at an insight requires two steps:
- Notice something unexpected, e.g., a sudden drop or increase in some metric.
- Understand why this happened, i.e., dig deeper into the data to identify the root cause.
When we understand why something happened, we can often also identify a potential action that could get us back on track, thereby making this an actionable insight.
Knowing which values are unexpected and where it might pay off to dig deeper often requires some domain knowledge, so you might want to examine the results together with a subject matter expert.
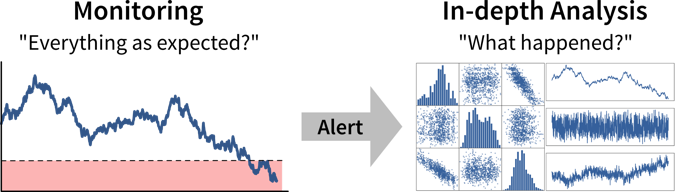
Ideally, we should continuously monitor important metrics in dashboards or reports to spot deviations from the norm as quickly as possible, while identifying the root cause often requires a custom analysis.
As a data analyst you are sometimes approached with more specific questions or requests such as “We’re deciding where to launch a new marketing campaign. Can you show me the number of users for all European countries?”. In these cases it can be helpful to ask “why?” to understand where the person noticed something unexpected that prompted this analysis request. If the answer is “Oh, we just have some marketing budget left over and need to spend the money somewhere” then just give them the results. But if the answer is “Our revenue for this quarter was lower than expected” it might be worth exploring other possible root causes for this, as maybe the problem is not the number of users that visit the website, but that many users drop out before they reach the checkout page and the money might be better invested in a usability study to understand why users don’t complete the sale.
Data-driven Decisions
While learning something about the data and its context is often interesting and can feel rewarding by itself, it is not yet valuable. Insights become valuable when they influence a decision and inspire a different course of action, better than the default that would have been taken without the analysis.
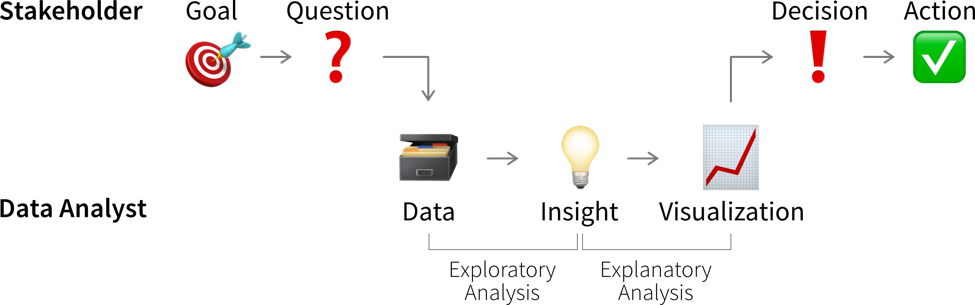
This means we need to understand which decision(s) the insights from our data analysis should influence.
Not all decisions need to be made in a data-driven way. But decision makers should be transparent and upfront about whether a decision can be influenced by analysis results, i.e., what data would make them change their mind and choose a different course of action. If data is only requested to support a decision that in reality has already been made, save the analysts the time and effort!
Before we conduct a data analysis we need to be clear on:
- Who are the relevant stakeholders, i.e., who will consume the data analysis results (= our audience / dashboard users)?
- What is their goal?
In business contexts, the users’ goals are usually in some way related to making a profit for the company, i.e., increasing revenue (e.g., by solving a customer problem more effectively than the competition) or reducing costs.
The progress towards these goals is tracked with so called Key Performance Indicators (KPIs), i.e., custom metrics that tell us how well things are going. For example, if we’re working on a web application, one KPI we might want to track could be “user happiness”. Unfortunately, true user happiness is difficult to measure, but we can instead check the number of users returning to our site and how long they stay and then somehow combine these and other measurements into a proxy variable that we then call “user happiness”.
A KPI is only a reliable measure, if it is not simultaneously used to control people’s behavior, as they will otherwise try to game the system (Goodhart’s Law). For example, if our goal is high quality software, counting the number of bugs in our software is not a reliable measure for quality, if we simultaneously reward programmers for every bug they find and fix.
Lagging vs. Leading KPIs
Unfortunately, the things we really care about can often only be measured after the fact, i.e., when it is too late to take corrective action. For example, in sales we care about “realized revenue”, i.e., money in the bank, but if the revenue at the end of the quarter is less than what we hoped for, we can only try to do better next quarter. These metrics are called lagging KPIs.
Leading KPIs instead tell us when we should act before it’s too late. For example, in sales this could be the volume of deals in the sales pipeline, i.e., while not all of these deals might eventually go through and result in realized revenue, if the pipeline is empty we know for certain that we wont reach our revenue goals.
If the causal relationships between variables are too complex to identify leading KPIs directly, we can instead try to use a machine learning model to predict lagging KPIs. For example, in a polymer production process, an important quality metric may be the tensile strength measured 24 hours after the polymer hardens. Waiting for these results could lead to discarding the last 24 hours of production if the quality is subpar. If the relationships between the process parameters (such as production temperature) and the resulting quality are too complex to identify a leading KPI, we could instead train an ML model on the past process parameters (inputs) and corresponding quality measurements (outputs) to then continuously predict the quality during production. When the model predicts that the quality is off-target, the operators can intervene and fix issues before significant production time is wasted.
However, relying on an ML model introduces the need to monitor its predictions for trustworthiness. In our example, the prediction accuracy on new data serves as a lagging KPI, as we only know whether the predictions are correct after real measurements arrive 24 hours later. As a leading KPI, we can measure the discrepancy between process parameter values used in model training and those received in production to identify dataset drifts. These drifts, such as changes in values due to sensor malfunctions, can lead to inaccurate predictions for affected samples.
The first step when making a data-driven decision is to realize that we should act by monitoring our KPIs to see whether we’re on track to achieve our goals.
Ideally, this is achieved by combining these metrics with thresholds for alerts to automatically notify us if things go south and a corrective action becomes necessary. For example, we could establish some alert on the health of a system or machine to notify a technician when maintenance is necessary. To avoid alert fatigue, it is important to reduce false alarms, i.e., configure the alert such that the responsible person tells you “when this threshold is reached, I will drop everything else and go fix the problem” (not “at this point we should probably keep an eye on it”).
Depending on how frequently the value of the KPI changes and how quickly corrective actions show effects, we want to check for the alert condition either every few minutes to alert someone in real time or, for example, every morning, every Monday, or once per month if the values change more slowly.
Is this significant?
Small variations in KPIs are normal and we should not overreact to noise. Statistics can tell us whether the observed deviation from what we expected is significant.
Statistical inference enables us to draw conclusions that reach beyond the data at hand. Often we would like to make a statement about a whole population (e.g., all humans currently living on this earth), but we only have access to a few (hopefully representative) observations to draw our conclusion from. Statistical inference is about changing our mind under uncertainty: We start with a null hypothesis (i.e., what we expected before looking at the data) and then check if what we see in the sample dataset makes this null hypothesis look ridiculous, at which point we reject it and go with our alternative hypothesis instead.
Example: Your company has an online store and wants to roll out a new recommendation system, but you are unsure whether customers will find these recommendations helpful and buy more. Therefore, before going live with the new system, you perform an A/B test, where a percentage of randomly selected users see the new recommendations, while the others are routed to the original version of the online store. The null hypothesis is that the new version is no better than the original. But it turns out that the average sales volume of customers seeing the new recommendations is a lot higher than that of the customers browsing the original site. This difference is so large that in a world where the null hypothesis was true, it would be extremely unlikely that a random sample would give us these results. We therefore reject the null hypothesis and go with the alternative hypothesis, that the new recommendations generate higher sales.
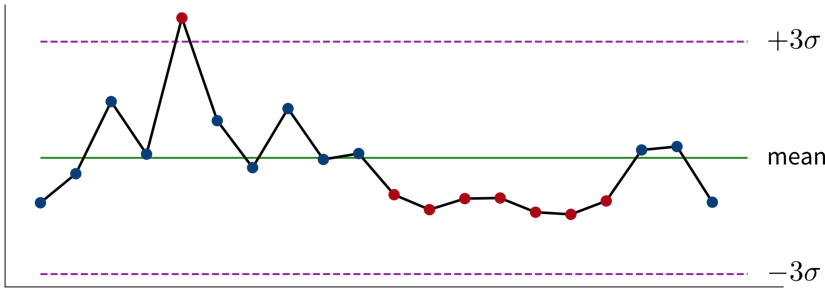
In addition to rigorous statistical tests, there are also some rules of thumb to determine whether changes in the data warrant our attention: If a single sample lies three standard deviations (\(\sigma\)) above or below the mean or seven consecutive points fall above or below the average value, this is cause for further investigation.
Read this article to learn more about the difference between analysts and statisticians and why they should work on distinct splits of your dataset.
For every alert that is created, i.e., every time it is clear that a corrective action is needed, it is worth considering whether this action can be automated and to directly trigger this automated action together with the alert (e.g., if the performance of an ML model drops below a certain threshold, instead of just notifying the data scientist we could automatically trigger a retraining with the most recent data). If this is not possible, e.g., because it is not clear what exactly happened and therefore which action should be taken, we need a deeper analysis.
Digging deeper into the data can help us answer questions such as “Why did we not reach this goal and how can we do better?” (or, in rarer cases, “Why did we exceeded this goal and how can we do it again?”) to decide on the specific action to take.
Don’t just look for data that confirms the story you want to tell and supports the action you wanted to take from the start (i.e., beware of confirmation bias)! Instead be open and actively try to disprove your hypothesis.
Such an exploratory analysis is often a quick and dirty process where we generate lots of plots to better understand the data and where the difference between what we expected and what we saw in the data is coming from, e.g., by examining other correlated variables. However, arriving at satisfactory answers is often more art than science.
When using an ML model to predict a KPI, we can interpret this model and its predictions to better understand which variables might influence the KPI. Focusing on the features deemed important by the ML model can be helpful if our dataset contains hundreds of variables and we don’t have time to look at all of them in detail. But use with caution – the model only learned from correlations in the data; these do not necessarily represent true causal relationships between the variables.
Analysis questions to answer before an ML project
Examine the raw data:
- Is the dataset complete, i.e., does it contain all the variables and samples we expected to get?
Examine summary statistics (e.g., mean, standard deviation (std), min/max values, missing value count, etc.), for example, by calling
df.describe()on a pandas data frame:- What does each variable mean? Given our understanding of the variable, are its values in a reasonable range?
- Are missing values encoded as NaN (Not a Number) or as ‘unrealistic’ numeric values (e.g., -1 while normal values are between 0 and 100)?
- Are missing values random or systematic (e.g., in a survey rich people are less likely to answer questions about their income or specific measurements are only collected under certain conditions)? → This can influence how missing values should be handled during preprocessing, e.g., whether it makes sense to impute them with the mean or some other specific value (e.g., zero).
Examine the distributions of individual variables (e.g., using histograms):
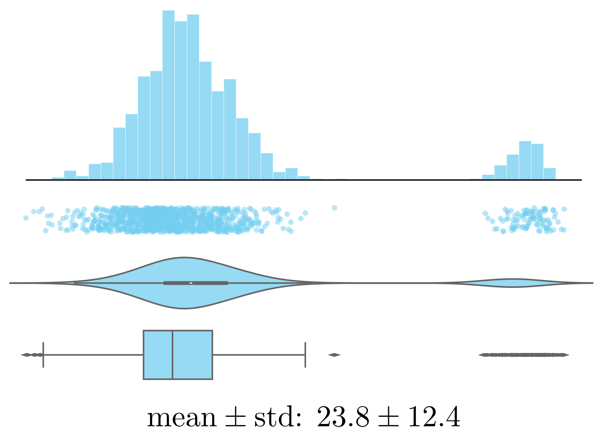
Histogram, strip plot, violin plot, box plot, and summary statistics of the same data. - Are there any outliers? Are these genuine edge cases or can they be ignored (e.g., due to measurement errors or wrongly encoded data)?
- Is the data normally distributed or does the plot show multiple peaks? Is this expected?
Examine trends over time (by plotting variables over time):
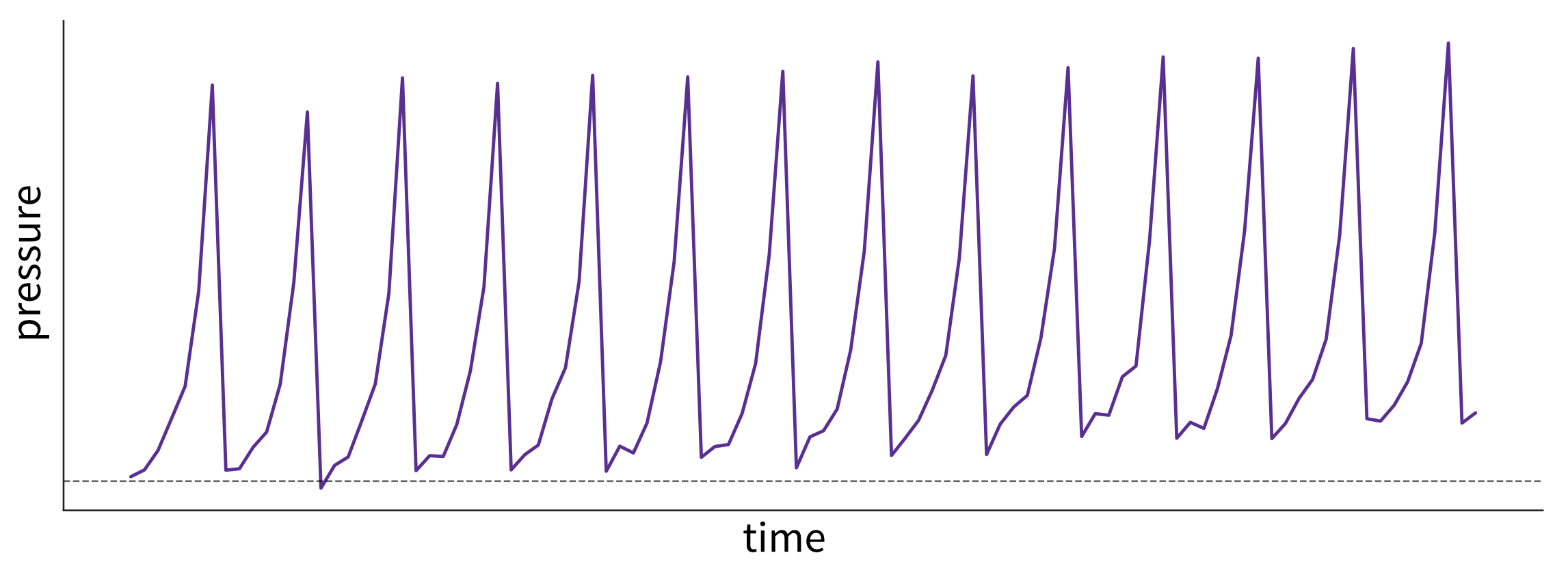
What caused these trends and what are their implications for the future? This plot shows fictitious data of the pressure in a pipe affected by fouling—that is, a buildup of unwanted material on the pipe’s surface, leading to increased pressure. The pipe is cleaned at regular intervals, causing a drop in pressure. However, because the cleaning process is imperfect, the baseline pressure gradually shifts upward over time. - Are there time periods where the data was sampled irregularly or samples are missing? Why?
- Are there any (gradual or sudden) data drifts over time? Are these genuine changes (e.g., due to changes in the raw materials used for production) or artifacts (e.g., due to a malfunctioning sensor recording wrong values)?
Examine relationships between variables:
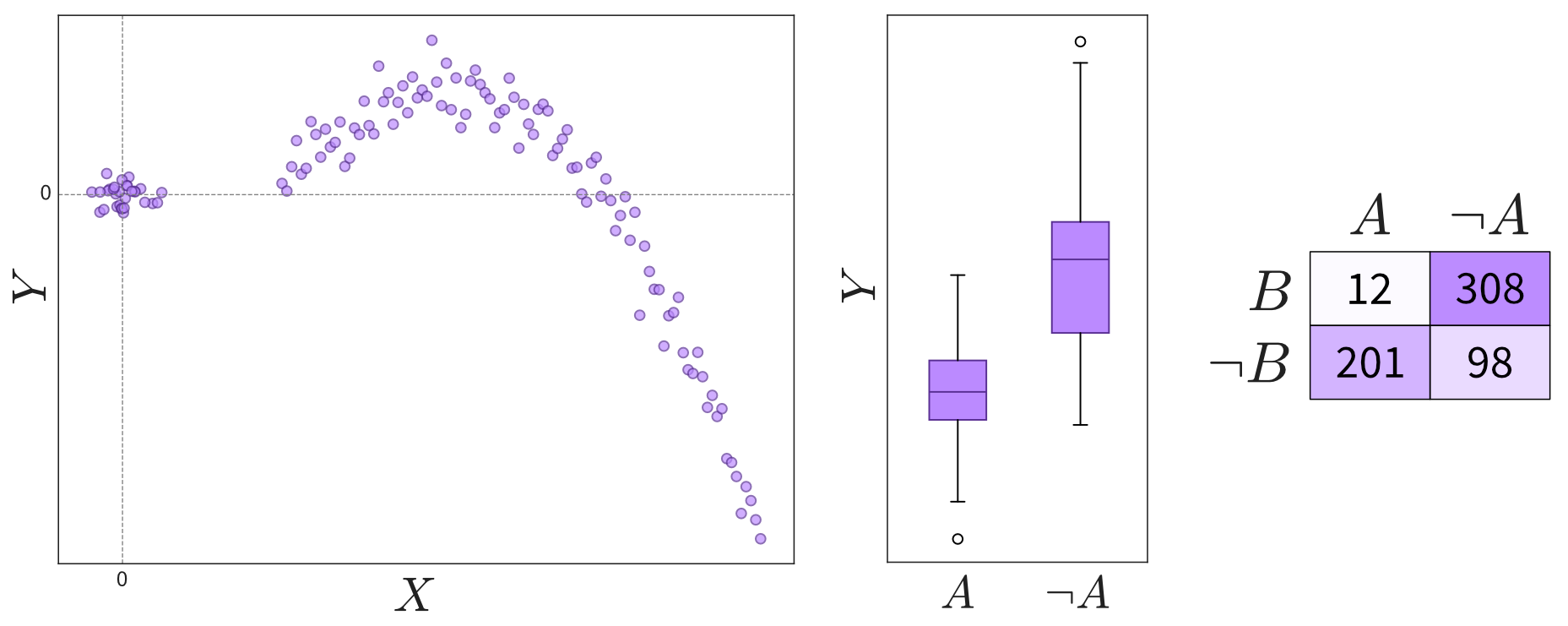
Depending on the variables’ types (continuous or discrete), relationships can be shown in scatter plots, box plots, or a table. Please note that not all interesting relations between two variables can be detected through a high correlation coefficient. Always check the scatter plot for details. - Are the observed correlations between variables expected?
Examine patterns in multidimensional data (using parallel coordinate plots):
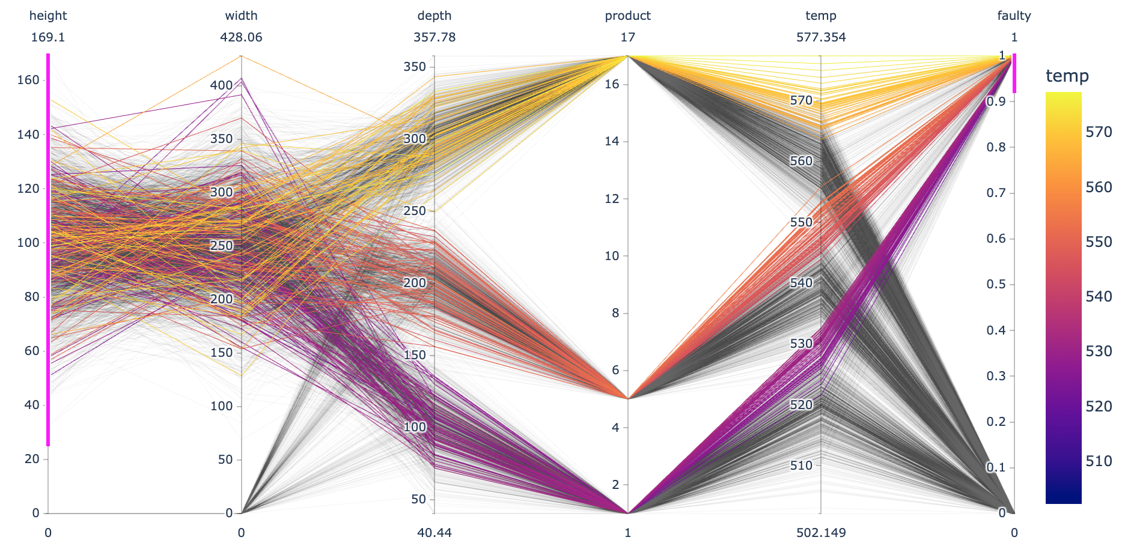
Each line in a parallel coordinate plot represents one data point, with the corresponding values for the different variables marked at the respective y-axis. The screenshot here shows an interactive plot created using the plotlylibrary. By selecting value ranges for the different dimensions (indicated by the pink stripes), it is possible to spot interesting patterns resulting from a combination of values across multiple variables.- Do the observed patterns in the data match our understanding of the problem and dataset?
The data should not only be examined at the outset of an ML project, but also monitored continuously throughout the lifetime of the application, e.g., by regularly checking how many samples we received per hour, that the values for each variable are in the expected range, and that there are no unexpected missing values.
Communicating Insights
The plots that were created during an exploratory analysis should not be the plots we show our audience when we’re trying to communicate our findings. Since our audience is far less familiar with the data than us and probably also not interested / doesn’t have the time to dive deeper into the data, we need to make the results more accessible, a process often called explanatory analysis.
Don’t “just show all the data” and hope that your audience will make something of it – this is the downfall of many dashboards. It is essential, that you understand what goal your audience is trying to achieve and what questions they need answers to.
Step 1: Choose the right plot type
- Get inspired by visualization libraries (e.g., here or here), but avoid the urge to create fancy graphics; sticking with common visualizations makes it easier for the audience to correctly decode the presented information
- Don’t use 3D effects!
- Avoid pie or donut charts (angles are hard to interpret)
- Use line plots for time series data
- Use horizontal instead of vertical bar charts for audiences that read left to right
- Start the y-axis at 0 for area & bar charts
- Consider using small multiples or sparklines instead of cramming too much into a single chart
Step 2: Cut clutter / maximize data-to-ink ratio
- Remove border
- Remove gridlines
- Remove data markers
- Clean up axis labels
- Label data directly
Step 3: Focus attention
- Start with gray, i.e., push everything in the background
- Use pre-attentive attributes like color strategically to highlight what’s most important
- Use data labels sparingly
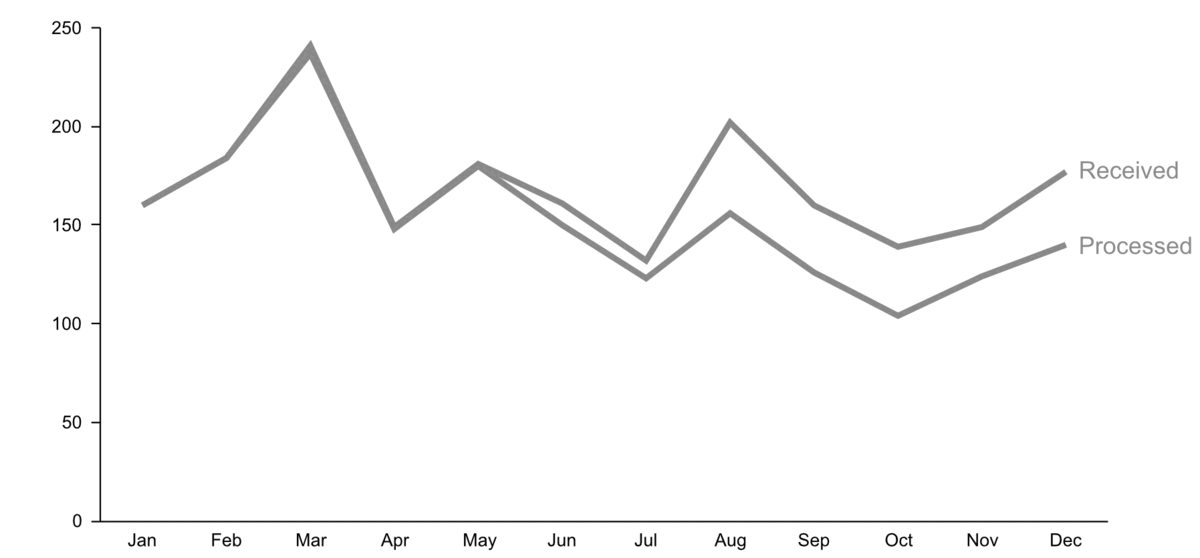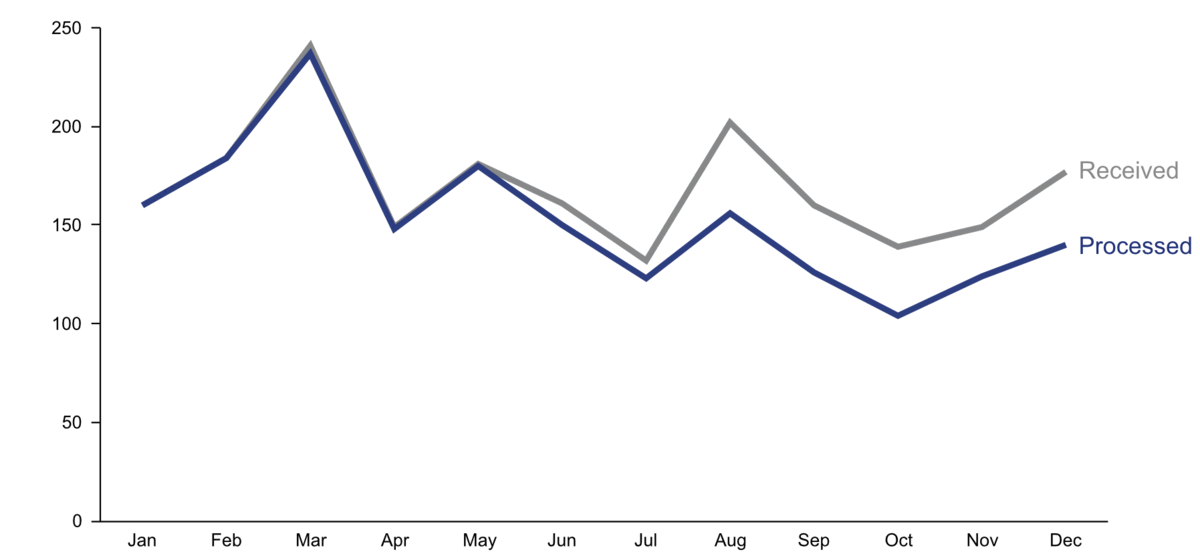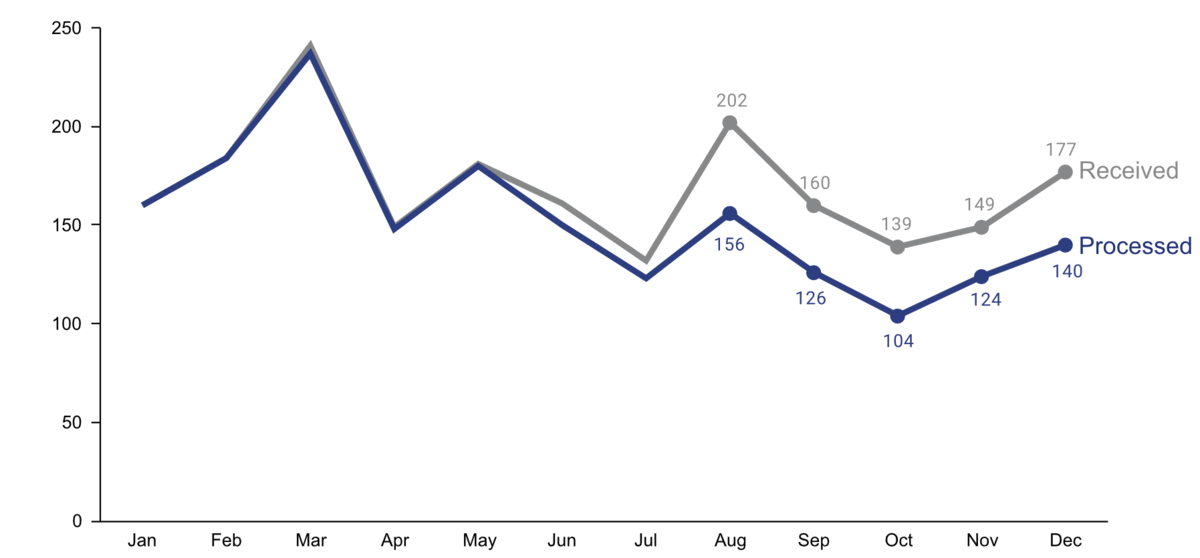
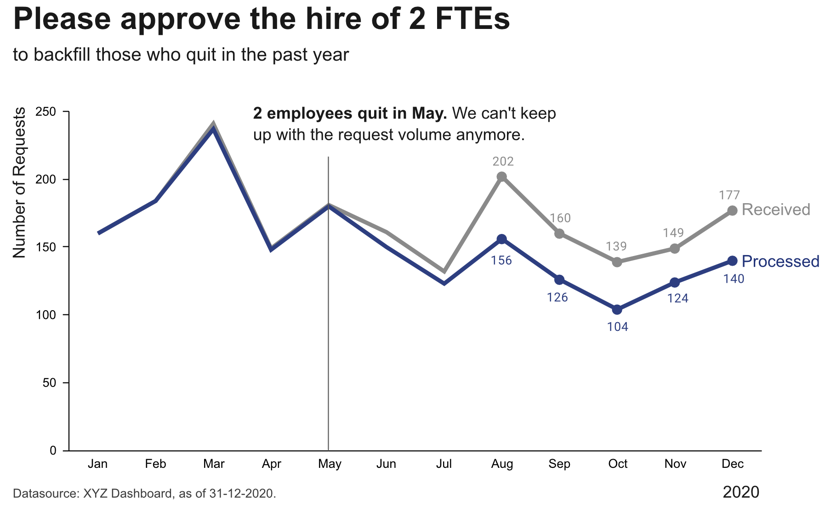
Step 4: Make data accessible
- Add context: Which values are good (goal state), which are bad (alert threshold)? Should the values be compared to another variable (e.g., actual vs. forecast)?
- Leverage consistent colors when information is spread across multiple plots (e.g., data from a certain country is always drawn in the same color)
- Annotate the plot with text explaining the main takeaways (if this is not possible, e.g., in dashboards where the data keeps changing, the title can instead include the question that the plot should answer, e.g., “Does our revenue follow the projections?”)
Further reading
- Show Me the Numbers: Designing Tables and Graphs to Enlighten by Stephen Few
- Better Data Visualizations: A Guide for Scholars, Researchers, and Wonks by Jonathan Schwabish
- Effective Data Storytelling: How to drive change with data, narrative, and visuals by Brent Dykes
- Storytelling with Data: A data visualization guide for business professionals by Cole Nussbaum Knaflic
- Data Visualization: A successful design process by Andy Kirk
- Various blog posts by Cassie Kozyrkov
Garbage in, Garbage out!
Remember: data is our raw material when producing something valuable with ML. If the quality or quantity of the data is insufficient, we are facing a “garbage in, garbage out” scenario and no matter what kind of fancy ML algorithm we try, we wont get a satisfactory result. In fact, the fancier the algorithm (e.g., deep learning), the more data we need.
Below you find a summary of some common risks associated with data that can make it complicated or even impossible to apply ML:
Raw data can be very messy:
- Relevant data is spread across multiple databases / excel sheets that need to be joined. Worst case: Data points don’t have a unique ID based on which the different entries can be linked. Instead one has to fall back on some error prone strategy like matching data based on time stamps.
- Manually entered values contains errors, e.g., misplaced decimal points.
- It is not possible to correct missing values. Worst case: Missing values are not random. For example, sensors fail only right before something goes wrong during the production process. Or in surveys, rich people more often decline to answer questions regarding their income compared to poor or middle class people. This introduces a systematic bias in the dataset.
- The dataset consists of different data types (structured and/or unstructured) with different scales.
- The process setup changes over time, e.g., due to some external conditions like replacing a sensor or some other maintenance event, which means the data collected from different time periods are incompatible. Worst case: These external changes were not recorded anywhere and we only notice at the end of the analysis that the data we were working with violated our assumptions.
→ Data preprocessing takes a very long time.
→ Resulting dataset (after cleaning) is a lot smaller than expected – possibly too small to do any meaningful analysis.
⇒ Before wanting to do ML, first think about how your data collection pipeline & infrastructure could be improved!
Not enough / not the right data to do ML:
Small dataset and/or too little variation, e.g., we produced only a few defective products or a process runs in a steady state most of the time, i.e., there is little or no variation in the inputs.
→ Effect of different input variables on the target can’t be estimated reliably from only a few observations.
⇒ Do some experiments where you systematically vary different inputs to collect a more diverse dataset.Data is inconsistent / incomplete, i.e., same inputs with different outputs, e.g., two products were produced under the same (measured) conditions, one is fine, the other is faulty.
This can have two reasons:- The labels are very noisy, for example, because the human annotators didn’t follow the same set of clear rules or some examples were ambiguous, e.g., one QA-expert deems a product with a small scratch as still OK, while another labels it as defective.
⇒ Clean up the data by relabeling, which can take some time but will pay off! See also this great MLOps / data-centric AI talk by Andrew Ng on how a small high-quality dataset can be more valuable than a larger noisy dataset. - Relevant input features are missing: While it is relatively easy for humans to assess if all the relevant information is present in unstructured data (e.g., images: either we see a cat or we don’t), structured data often has too many different variables and complex interactions to know right away whether all the relevant features were included.
⇒ Talk to a subject matter expert about which additional input features might be helpful and include these in the dataset. Worst case: Need to install a new sensor in the machine and collect this data, i.e., all the data collected in the past is basically useless. BUT: using the right sensor can simplify the problem immensely and installing it will be worth it!
- The labels are very noisy, for example, because the human annotators didn’t follow the same set of clear rules or some examples were ambiguous, e.g., one QA-expert deems a product with a small scratch as still OK, while another labels it as defective.
In many applications, our first instinct is to use a camera to generate the input data, since we humans rely primarily on our visual system to solve many tasks. However, even though image recognition algorithms have come a long way, using such a setup instead of a more specialized sensor can make the solution more error prone.
Trying to detect mushy strawberries? Use a near infrared (NIR) sensor instead of a regular camera like Amazon Fresh did. They still use machine learning to analyze the resulting data, but in the NIR images the rotting parts of fruits are more easily visible than in normal photos.
Trying to detect if a door is closed? With a simple magnet and detector, this task can be solved without any complex analysis or training data! (You probably know the saying: “When you have a hammer, everything looks like a nail”. → Don’t forget to also consider solutions outside your ML toolbox! ;-))
→ Unless the dataset is amended accordingly, any ML model has a poor performance!
If you can, observe how the data is collected. As in: actually physically stand there and watch how someone enters the values in some program or how the machine operates as the sensors measure something. You will probably notice some things that can be optimized in the data collection process directly, which will save you lots of preprocessing work in the future.
Best Practice: Data Catalog
To make datasets more accessible, especially in larger organizations, they should be documented. For example, in structured datasets, there should be information available on each variable like:
- Name of the variable
- Description
- Units
- Data type (e.g., numerical or categorical values)
- Date of first measurement (e.g., in case a sensor was installed later than the others)
- Normal/expected range of values (→ “If this variable is below this threshold, then the machine is off and the data points can be ignored.”)
- How missing values are recorded, i.e., whether they are recorded as missing values or substituted with some unrealistic value instead, which can happen since some sensors are not able to send a signal for “Not a Number” (NaN) directly or the database does not allow for the field to be empty.
- Notes on anything else you should be aware of, e.g., a sensor malfunctioning during a certain period of time or some other glitch that resulted in incorrect data. This can otherwise be difficult to spot, for example, if someone instead manually entered or copy & pasted values from somewhere, which look normal at first glance.
You can find further recommendations on what is particularly important when documenting datasets for machine learning applications in the Data Cards Playbook.
In addition to documenting datasets as a whole, it is also helpful to store metadata for individual samples. For example, for image data, this could include the time stamp of when the image was taken, the geolocation (or if the camera is built into a manufacturing machine then the ID of this machine), information about the camera settings, etc.. This can greatly help when analyzing model prediction errors, as it might turn out that, for example, images taken with a particular camera setting are especially difficult to classify, which in turn gives us some hints on how to improve the data collection process.
Data as an Asset
With the right processes (e.g., roles such as “Data Owner” and “Data Controller” that are accountable for the data quality, and a consistent data infrastructure that includes a monitoring pipeline to validate new data), it is possible for an organization to get from “garbage in, garbage out” to “data is the new oil”:
With (big) data comes great responsibility!
Some data might not seem very valuable to you, but can be a huge asset for others, i.e., with a different use case!
Data Preprocessing
Now that we better understand our data and verified that it is (hopefully) of good quality, we can get it ready for our machine learning algorithms.
Raw Data can come in many different forms, e.g., sensor measurements, pixel values, text (e.g., HTML page), SAP database, …
→ n data points, stored as rows in an excel sheet, as individual files, etc.
It’s always important to be really clear about what one data point actually is, i.e., what the inputs look like and what we want back as a result from the model for each sample / observation. Think of this in terms of how you plan to integrate the ML model with the rest of your workflow: what data is generated in the previous step and can be used as input for the ML part, and what is needed as an output for the following step?
Preprocessing
transforming and enriching the raw data before applying ML, for example:
- remove / correct missing or wrongly entered data (e.g., misplaced decimal point)
- exclude zero variance features (i.e., variables with always the same value) and nonsensical variables (e.g., IDs)
- feature extraction: transform into numerical values (e.g., unstructured data like text)
- feature engineering: compute additional/better features from the original variables
⇒ Feature matrix \(\,X \in \mathbb{R}^{n\times d}\): n data points; each represented as a d-dimensional vector (i.e., with d features)
Please note that, in general, it is important that all samples in a dataset are represented as the same kind of fixed-length vectors. E.g., if the first position (i.e., feature) in the vector of one sample represents the temperature at which a product was produced, then the first position in the feature vector of another sample can not be this product’s height. This is critical, because most ML models learn some kind of weights that act on the individual features and if these are always at different positions (or missing for some data points), then the algorithm would not be able to apply the correct weight to the respective feature.
Prediction Targets?
→ Label vector \(\,\mathbf{y}\) : n-dimensional vector with one target value per data point
What constitutes one data point?
Even given the same raw data, depending on what problem we want to solve, the definition of ‘one data point’ can be quite different. For example, when dealing with time series data, the raw data is in the form ‘n time points with measurements from d sensors’, but depending on the type of question we are trying to answer, the actual feature matrix can look quite different:
1 Data Point = 1 Time Point
e.g., anomaly detection ⇒ determine for each time point if everything is normal or if there is something strange going on:
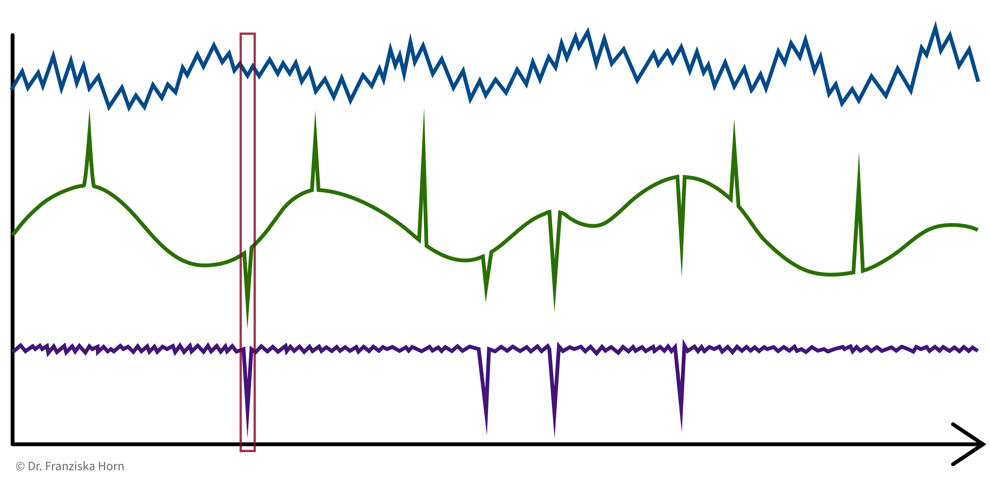
→ \(X\): n time points \(\times\) d sensors, i.e., n data points represented as d-dimensional feature vectors
1 Data Point = 1 Time Series
e.g., cluster sensors ⇒ see if some sensors measure related things:
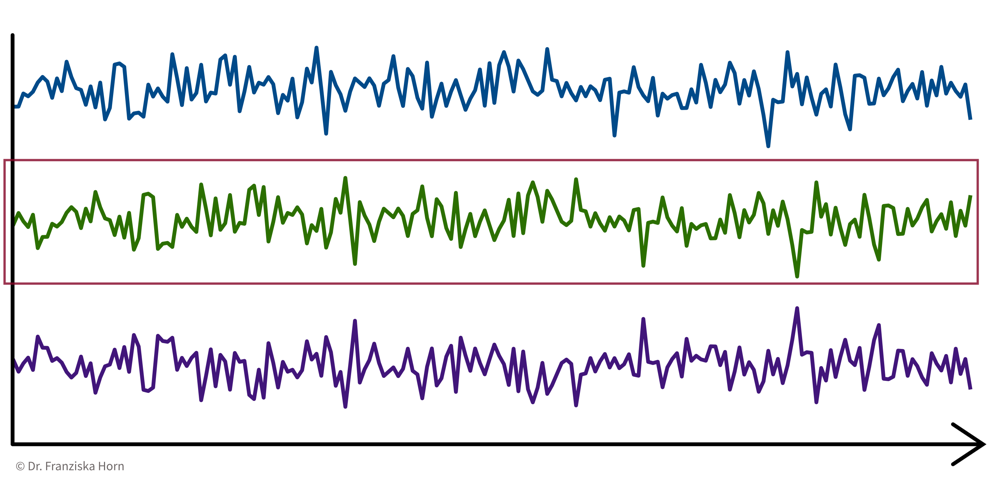
→ \(X\): d sensors \(\times\) n time points, i.e., d data points represented as n-dimensional feature vectors
1 Data Point = 1 Time Interval
e.g., classify time segments ⇒ products are being produced one after another, some take longer to produce than others, and the task is to predict whether a product produced during one time window at the end meets the quality standards, i.e., we’re not interested in the process over time per se, but instead regard each produced product (and therefore each interval) as an independent data point:
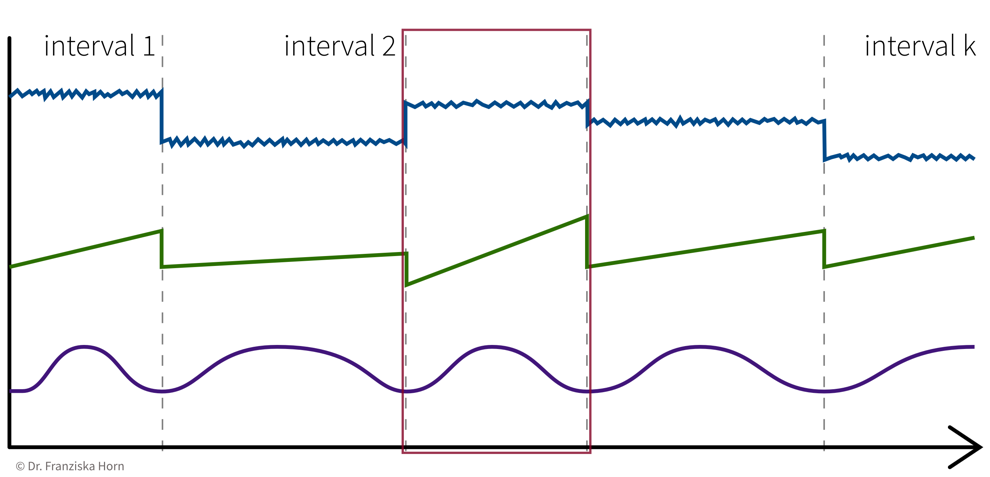
→ Data points always need to be represented as fixed-length feature vectors, where each dimension stands for a specific input variable. Since the intervals here have different lengths, we can’t just represent one product as the concatenation of all the sensor measurements collected during its production time interval, since these vectors would not be comparable for the different products. Instead, we compute features for each time segment by aggregating the sensor measurements over the interval (e.g., min, max, mean, slope, …).
→ \(X\): k intervals \(\times\) q features (derived from the d sensors), i.e., k data points represented as q-dimensional feature vectors
Feature Extraction
Machine learning algorithms only work with numbers. But some data does not consist of numerical values (e.g., text documents) or these numerical values should not be interpreted as such (e.g., sports players have numbers on their jerseys, but these numbers don’t mean anything in a numeric sense, i.e., higher numbers don’t mean the person scored more goals, they are merely IDs).
For the second case, statisticians distinguish between nominal, ordinal, interval, and ratio data, but for simplicity we lump the first two together as categorical data, while the other two are considered meaningful numerical values.
For both text and categorical data we need to extract meaningful numerical features from the original data. We’ll start with categorical data and deal with text data at the end of the section.
Categorical features can be transformed with a one-hot encoding, i.e., by creating dummy variables that enable the model to introduce a different offset for each category.
For example, our dataset could include samples from four product categories circle, triangle, square, and pentagon, where each data point (representing a product) falls into exactly one of these categories. Then we create four features, is_circle, is_triangle, is_square, and is_pentagon, and indicate a data point’s product category using a binary flag, i.e., a value of 1 at the index of the true category and 0 everywhere else:
e.g., product category: triangle ⇒ [0, 1, 0, 0]
from sklearn.preprocessing import OneHotEncoderFeature Engineering & Transformations
Often it is very helpful to not just use the original features as is, but to compute new, more informative features from them – a common practice called feature engineering. Additionally, one should also check the distributions of the individual variables (e.g., by plotting a histogram) to see if the features are approximately normally distributed (which is an assumption of most ML models).
Generate additional features (i.e., feature engineering)
- General purpose library: missing data imputation, categorical encoders, numerical transformations, and much more.
→feature-enginelibrary - Feature combinations: e.g., product/ratio of two variables. For example, compute a new feature as the ratio of the temperature inside a machine to the temperature outside in the room.
→autofeatlibrary (Disclaimer: written by yours truly.) - Relational data: e.g., aggregations across tables. For example, in a database one table contains all the customers and another table contains all transactions and we compute a feature that shows the total volume of sales for each customer, i.e., the sum of the transactions grouped by customers.
→featuretoolslibrary - Time series data: e.g., min/max/average over time intervals.
→tsfreshlibrary
⇒ Domain knowledge is invaluable here – instead of blindly computing hundreds of additional features, ask a subject matter expert which derived values she thinks might be the most helpful for the problem you’re trying to solve!
Aim for normally/uniformly distributed features
This is especially important for heterogeneous data:
For example, given a dataset with different kinds of sensors with different scales, like a temperature that varies between 100 and 500 degrees and a pressure sensor that measures values between 1.1 and 1.8 bar:
→ the ML model only sees the values and does not know about the different units
⇒ a difference of 0.1 for pressure might be more significant than a difference of 10 for the temperature.
for each feature: subtract mean & divide by standard deviation (i.e., transform an arbitrary Gaussian distribution into a normal distribution)
from sklearn.preprocessing import StandardScalerfor each feature: scale between 0 and 1
from sklearn.preprocessing import MinMaxScalermap to Gaussian distribution (e.g., take log/sqrt if the feature shows a skewed distribution with a few extremely large values)
from sklearn.preprocessing import PowerTransformer
Not using (approximately) normally distributed data is a very common mistake!
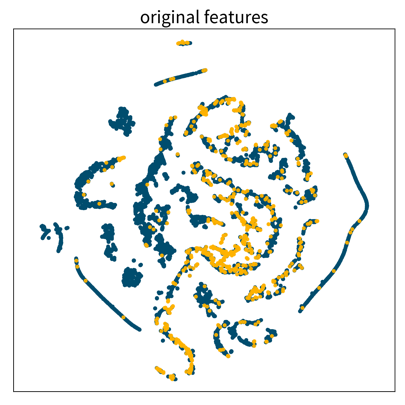
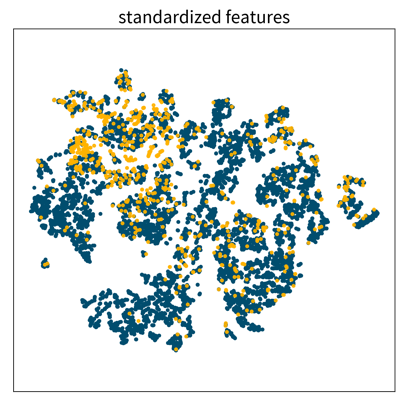
![]()
These three 2D visualizations were created with the dimensionality reduction method t-SNE on the same dataset, first using the original feature vectors, then on standardized data, and lastly after applying a power transformation. Each dot is one data point where the color denotes the point’s class. Only the last plot shows some clearly distinguishable clusters of the same class.
Computing Similarities
Many ML algorithms rely on similarities or distances between data points, computed with measures such as:
- Euclidean distance
- Cosine similarity (e.g., when working with text data)
- Similarity coefficients (e.g., Jaccard index)
- … and many more.
from sklearn.metrics.pairwise import ...Which feature should have how much influence on the similarity between points? → Domain knowledge!
⇒ Scale / normalize heterogeneous data: For example, the pressure difference between 1.1 and 1.3 bar might be more dramatic in the process than the temperature difference between 200 and 220 degrees, but if the distance between data points is computed with the unscaled values, then the difference in temperature completely overshadows the difference in pressure.
⇒ Exclude redundant / strongly correlated features, as they otherwise count twice towards the distance.
Working with Text Data
As mentioned before, machine learning algorithms can not work with text data directly, but we first need to extract meaningful numerical features from it.
Feature extraction: Bag-of-Words (BOW) TF-IDF features:
Represent a document as the weighted counts of the words occurring in the text:
- Term Frequency (TF): how often does this word occur in the current text document.
- Inverse Document Frequency (IDF): a weight to capture how significant this word is. This is computed by comparing the total number of documents in the dataset to the number of documents in which the word occurs. The IDF weight thereby reduces the overall influence of words that occur in almost all documents (e.g., so-called stopwords like ‘and’, ‘the’, ‘a’, …).
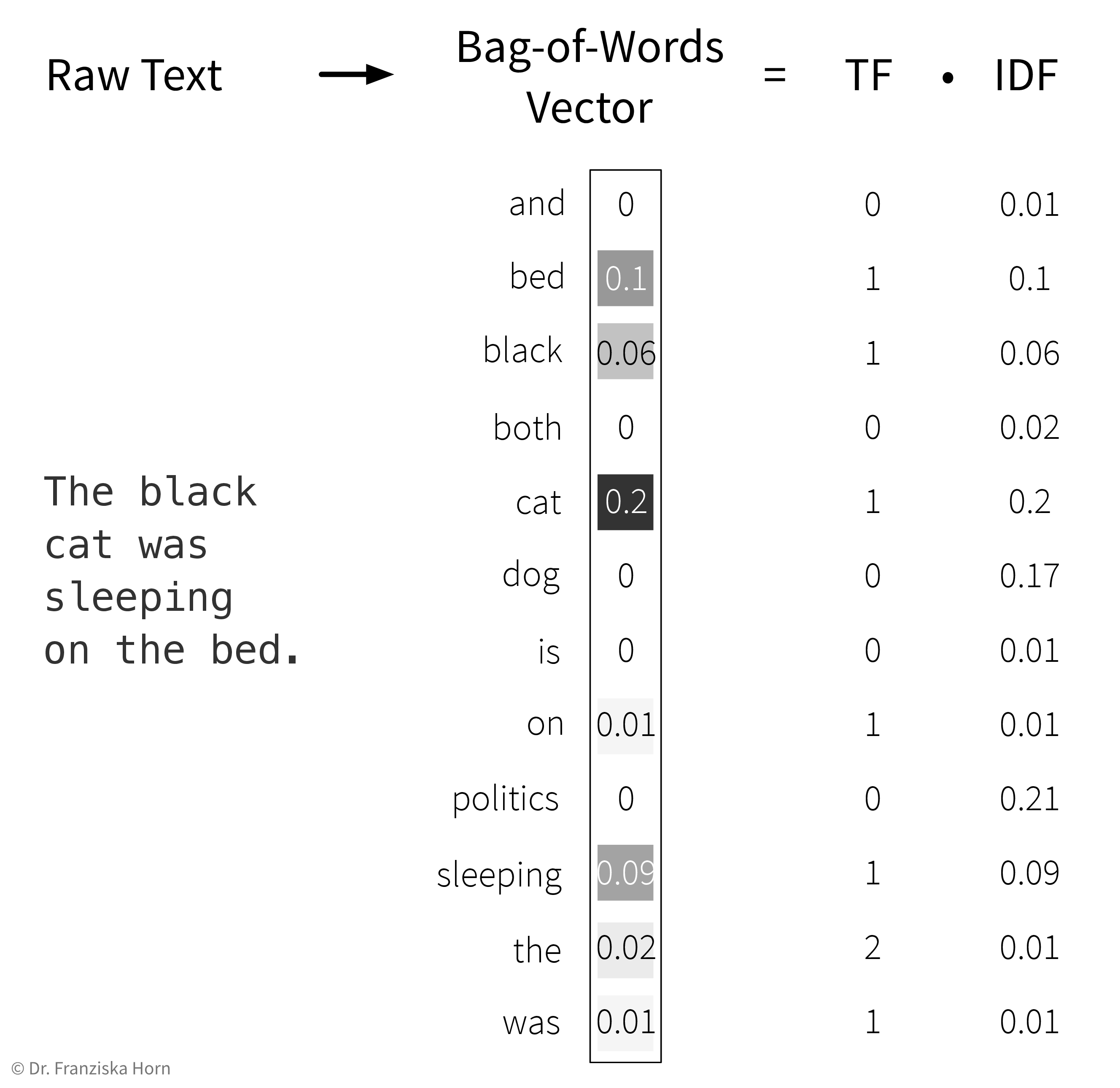
→ First, the whole corpus (= a dataset consisting of text documents) is processed once to determine the overall vocabulary (i.e., the unique words occurring in all documents that then make up the dimensionality of the BOW feature vector) and to compute the IDF weights for all words. Then each individual document is processed to compute the final TF-IDF vector by counting the words occurring in the document and multiplying these counts with the respective IDF weights.
from sklearn.feature_extraction.text import TfidfVectorizerComputing similarities between texts (represented as TF-IDF vectors) with the cosine similarity:
Scalar product (→ linear_kernel) of length normalized TF-IDF vectors:
\[ sim(\mathbf{x}_i, \mathbf{x}_j) = \frac{\mathbf{x}_i^\top \mathbf{x}_j}{\|\mathbf{x}_i\| \|\mathbf{x}_j\|} \quad \in [-1, 1] \] i.e., the cosine of the angle between the length-normalized vectors:
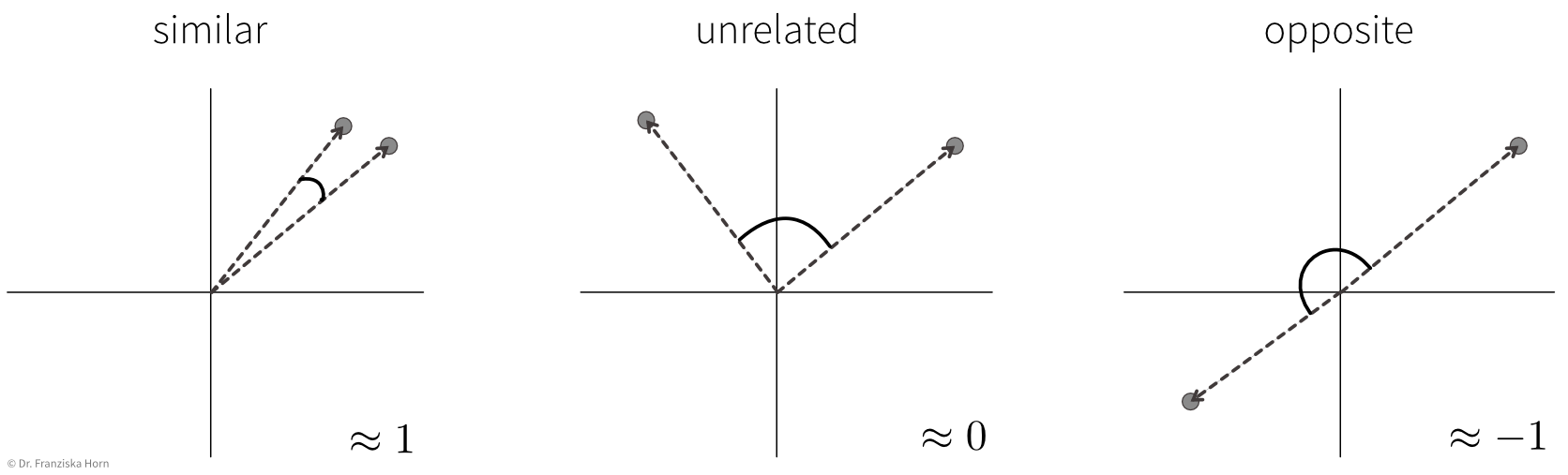
→ similarity score is between [0, 1] for TF-IDF vectors, since all entries in the vectors are positive.
Food for thought: Human vs. TF-IDF + Cosine Similarity understanding
The hotel was great, but the weather was bad.
vs.
The weather was great, but the hotel was bad.
vs.
The accommodation was wonderful, but it was raining all day.
For which of the above sentences would you say that they mean something similar?
Which sentence pairs would be assigned a high or lower similarity score when they are represented as TF-IDF vectors and the similarity is computed with the cosine similarity?
Disadvantages of TF-IDF vectors:
- Similarity between individual words (e.g., synonyms) is not captured, since each word has its own distinct dimension in the feature vector and is therefore equally far away from all other words.
- Word order is ignored → this is also where the name “bag of words” comes from, i.e., imagine all the words from a document are thrown into a bag and shook and then we just check how often each word occurred in the text.