6 From Research to Production
Your results look great, the paper is written, the conference talk is over—now you’re done, right?! Well, in academia, you might be. But let’s explore some concepts and tools that are common in industry and could take your code to the next level. Maybe they even inspire you to turn your project into a deployable app—an excellent reference when you apply for your next job!
Components of Software Products
So far, your code might consist of scripts or notebooks for analysis and a set of reusable helper functions in your personal library. The next step? Making your code accessible to others by turning it into standalone software with a graphical user interface (GUI). Furthermore, we’ll explore how to expand beyond static data sources like CSV or Excel files.
Graphical User Interface (GUI)
Software shines when users can interact with it easily. Instead of using a command-line interface (CLI), these days, users expect intuitive GUIs with buttons and visual elements.
We can broadly categorize software programs into:
- Stand-alone desktop or mobile applications, which users download and install on their devices.
- Web-based applications that run in a browser, like Google Docs. These are increasingly popular thanks to widespread internet access.
For web apps, the GUI that users interact with is also referred to as the frontend, while the backend handles behind-the-scenes tasks like data storage and processing. Even seemingly standalone desktop clients often connect to a backend server for cloud storage or to enable collaboration on shared documents. We’ll explore how this works in the section on APIs.
In research, the goal is often to make results more accessible, for example, by transforming a static report into an interactive dashboard where users can explore data. To do this, we recommend you start with a web-based app.
Many books and tutorials were written on the topic of building user-friendly software applications and a lot of it is very specific to the programming language you’re using—please consult your favorite search engine to discover more resources on this topic. 😉
streamlit framework
If you use Python, try the Streamlit framework to create web apps from your analysis scripts in minutes.
Databases
So far, we’ve assumed that your data is stored in spreadsheets (like CSV or Excel files) on your computer. While this works for smaller datasets and simple workflows, it becomes less practical as your data grows or is generated dynamically, such as through user interactions, and needs to be accessed and updated by multiple people at the same time. This is where databases come in, offering a more efficient and scalable way to store, retrieve, and manage data [5].
Databases come in many forms, each suited to different types of data and use cases. Two key considerations when choosing a database are [7]:
- the kind of data you need to store, and
- how that data will be used.
Types of Data in Databases
Different kinds of databases are ideal for different types of data (see also Chapter 2):
Structured data: This resembles spreadsheet data, with rows for records and columns for attributes. Structured data is typically stored in relational (SQL) databases, where data is organized into multiple interrelated tables. Each table has a schema—a strict definition of the fields it contains and their types, such as text or numbers. If data doesn’t match the schema, it’s rejected.
Normalization in relational databasesA process called normalization reduces redundancy by splitting data into separate tables. For example, instead of storing
material_type,material_supplier, andmaterial_qualitydirectly in a table ofsamples, you’d create amaterialstable with a unique ID for each material, then reference thematerial_idin thesamplestable. This avoids duplication and makes updates easier but requires more complex queries to combine tables and extract all the data needed for analysis.Semi-structured data: JSON or XML documents contain data in flexible key-value pairs and are often stored in NoSQL databases. Unlike SQL databases, these databases don’t enforce a strict schema, which makes them ideal for handling complex, nested data structures or dynamically changing datasets. For example, APIs often exchange data in JSON format, which can be stored as-is to avoid breaking it into tables and reconstructing it later.
Modern relational databases, such as Postgres, blur the line between structured and semi-structured data by supporting JSON columns alongside traditional tables.Unstructured data: Files like images, videos, and text documents are typically stored on disk. Data lakes (e.g., AWS S3) provide additional tools to manage these files, but fundamentally, this is similar to organizing files in folders on your computer. If your data is processed through a pipeline, it’s a good idea to save copies of the files at each stage (e.g., in
raw/andcleaned/folders).Streaming data: High-volume, real-time data (e.g., IoT sensor logs) is best managed in specialized databases optimized for streaming, such as Apache Kafka.
Use Cases for Databases
When choosing a database, you’ll also want to consider how the data will be used later:
- Transactional processing (OLTP): In this use case, individual records are frequently created and retrieved (e.g., financial transactions). These systems prioritize fast write speeds and maintaining an up-to-date view of the data.
- Batch analytics (OLAP): Data analysis is often performed in large batches to generate reports or insights, such as identifying which products users purchased last month. To avoid overloading the operational database with complex queries, data is typically copied from transactional systems to analytical systems (e.g., data warehouses) using an ETL process (Extract-Transform-Load).
- Real-time analytics: For applications requiring live data (e.g., interactive dashboards), databases and frameworks optimized for streaming or in-memory processing (e.g., Apache Flink) are ideal.
Scaling your database system is another critical factor. Consider how many users will access it simultaneously, how much data they’ll retrieve, and how often it will be updated.
CRUD Operations
Databases support four basic operations collectively called CRUD:
- Create: Add new records.
- Read: Retrieve data.
- Update: Modify existing records.
- Delete: Remove records.
These operations are performed using queries, often written in SQL (Structured Query Language). For example, SELECT * FROM table; retrieves all records from a table. If you’re new to SQL, this tutorial is a great place to start.
ORMs and Database Migrations
Writing raw database queries can be tedious, especially when working with complex schemas. Object-Relational Mappers (ORMs) simplify this by mapping database tables to objects in your code. With ORMs, you can interact with your database using familiar programming constructs and even define the schema directly in your code.
When designing a database schema and implementing the corresponding ORMs, it’s helpful to first sketch out the structure of the data (Figure 6.1). Start by identifying the key objects (which map to database tables), their fields, and their relationships.

User, Order, Product, and Category are mapped to the corresponding tables users, orders, products, and categories. Every record in a table is uniquely identified by a primary key, often named id. Fields in a table can either store data directly (e.g., text or boolean values) or reference records in another table, establishing relationships between tables. These relationships are defined using foreign keys, which store the primary key of a related record. For example, an Order references a single User ID (indicating the user who placed the order) and multiple Product IDs (the items included in the order).Relationships between tables can be bidirectional or unidirectional, depending on the use case. For instance, when querying a
Product, we want to list all the categories it belongs to, and vice versa. In contrast, the relationship between Order and Product only goes one way: when retrieving an Order, we want to know which products are included, but querying a Product doesn’t usually require listing all the orders it appears in.
Database migrations, or schema changes, often require careful coordination between code and database updates. For instance, renaming a field means you have to update your database and modify the code accessing it at the same time. Keeping migration scripts and application code (including ORMs) in the same repository helps ensure consistency during such updates.
APIs
In contrast to a user interface, through which a human interacts with a program, an Application Programming Interface (API) enables software components to communicate with one another. Think of it as a contract that defines how different systems interact. For example, an API might specify the classes and functions a library provides so developers can integrate it effectively.
APIs are often associated with Web APIs, which provide functionality over the internet. These can either be external services, like the Google Maps API for retrieving directions, or a custom-built backend that serves as an abstraction layer for a database. This abstraction is useful because it can combine data, enforce rules (e.g., verifying user permissions), and maintain a consistent interface even when the database structure changes.
Interacting with APIs
Web APIs typically use four HTTP methods that correspond to the CRUD (Create, Read, Update, Delete) operations in databases:
- GET: Retrieves data, most commonly used when accessing websites. You can include additional parameters by appending a
?to the URL. For example,https://www.google.com/search?q=web+apisearches for “web api” using the query parameterq. To pass multiple parameters, separate them with&. - POST: Sends data to create a new record, often as a JSON object, for example, when submitting a form.
- PUT: Updates an existing record.
- DELETE: Removes a record.
You typically interact with APIs through a website’s frontend, which triggers these API calls in the background. However, APIs can also be queried directly to access raw data, usually returned in JSON format.
Many APIs require an API key to access their functionality. This key serves as an identifier, allowing the API to authenticate users, track usage, and apply rate limits to prevent abuse. Always keep your API keys secure and avoid exposing them in public repositories or client-side code.
There are many free public APIs you can explore. As an example, we’ll use The Cat API to demonstrate how to interact with an API.
You can perform a GET request directly in your web browser. For instance, by visiting https://api.thecatapi.com/v1/images/search?limit=10, you’ll receive a JSON response containing a list of 10 random cat image URLs along with additional details like the image IDs.
For more advanced requests, such as POST, you’ll need specialized tools. Popular GUI clients include Postman, Insomnia, and Bruno. If you prefer command-line tools, curl is a powerful option. Alternatively, you can interact with APIs programmatically using your preferred programming language and relevant libraries.
In the examples below, we use curl and Python to interact with The Cat API to retrieve the latest votes for cat images with a GET request and submit a new vote using a POST request.
Using curl
Ensure curl is installed by running which curl in a terminal—this should return a valid path to your installation.
# GET request to view the last 10 votes for cat images
curl "https://api.thecatapi.com/v1/votes?limit=10&order=DESC" \
-H "x-api-key: DEMO-API-KEY"
# POST request to submit a new vote
# the payload after -d is the JSON object submitted to the API
curl -X POST "https://api.thecatapi.com/v1/votes" \
-H "Content-Type: application/json" \
-H "x-api-key: DEMO-API-KEY" \
-d '{
"image_id": "HT902S6ra",
"sub_id": "my-user-1234",
"value": 1
}'
# now run the GET request again to see your new voteUsing Python
Python’s requests library is great for working with APIs.
import requests
BASE_URL = "https://api.thecatapi.com/v1/votes"
API_KEY = "DEMO-API-KEY"
# GET request to fetch the last 10 votes
def get_last_votes():
response = requests.get(
BASE_URL,
headers={"x-api-key": API_KEY},
params={"limit": 10, "order": "DESC"}
)
if response.status_code == 200:
print(response.json())
else:
print(f"Error: {response.status_code}")
# POST request to submit a new vote
def submit_vote(image_id, sub_id, value):
data = {"image_id": image_id, "sub_id": sub_id, "value": value}
response = requests.post(
BASE_URL,
headers={"Content-Type": "application/json", "x-api-key": API_KEY},
json=data
)
if response.status_code == 201:
print("Vote submitted!")
else:
print(f"Error: {response.status_code}")
if __name__ == '__main__':
get_last_votes()
submit_vote("HT902S6ra", "my-user-1234", 1)Implementing APIs
When designing an API, specifically a REST (REpresentational State Transfer) API, it’s important to understand the concept of an endpoint. An endpoint is a specific URL in your API where a resource can be accessed or modified. For example, if you’re building a photo-sharing app, an endpoint like /images might allow users to view or upload images. Endpoints should be named using descriptive, plural nouns (e.g., /users, /images) to clearly represent the resources being accessed. It’s also best practice to avoid including verbs in endpoint names (e.g., /get_users), since the HTTP method (like GET or POST) already specifies the action being taken, such as retrieving or creating data.
Another key design principle is statelessness. Similar to the concept of pure functions, this means that each API request should contain all the information needed to complete the action, like user authentication tokens. This way, the server doesn’t need to remember anything about previous requests, making the API easier to scale. This is especially important in cloud-based environments where multiple requests from the same user may be routed to different servers [1].
Data that needs to be persisted can be stored either in the frontend or a central database in the backend, depending on its purpose. Temporary data, like a shopping cart, can be maintained on the user’s machine using cookies or local storage. Permanent data, such as a purchase order, is best stored in the backend database to ensure long-term accessibility. This approach supports stateless APIs, as the backend server doesn’t need to keep the session state in memory. Instead, all necessary data is either included in the request or can be fetched from the database, allowing each request to be processed independently.
FastAPI
FastAPI is a Python framework that makes building APIs straightforward. With just a few lines of code, you can turn a function into an endpoint that validates input and returns a JSON response. It’s beginner-friendly and highly performant.
Communicating with a Server: Use Cases
Code that runs on our local devices (like your laptop or smartphone) is often limited by the available hardware. For example, if you play a chess game on your phone against a bot, this bot will only have limited capabilities since the processor on your phone is not sufficient to run an advanced AI model (Figure 6.2).

A server in the cloud, on the other hand, has the necessary hardware (in this case multiple GPUs) to run an advanced AI-based chess bot (Figure 6.3). However, to play against this more challenging opponent, you need to have internet access to be able to submit your current game state to the server and receive the next bot move as a response. This also means that you can’t play the game in case your internet connection is not sufficient or the server is down.

Finally, by communicating with a server we can also play against other human players (Figure 6.4). For this, both players take turns in submitting and receiving their next moves to the server. Since the chess API may run on multiple server nodes to handle a high load of requests, it can’t be guaranteed that both players will interact with the same node, i.e., we need a stateless design. To accomplish this, the server persists and retrieves data in a central database that can be accessed by all nodes.1

Asynchronous Communication
When your script calls a library function or API and waits for it to return before continuing with the rest of the code, this is an example of synchronous communication. It’s similar to a conversation where one person speaks and then waits and listens while the other person responds.
In contrast, asynchronous (async) communication allows the program to keep running while waiting for a response. Once the response arrives, it is processed and integrated into the workflow, but until then the code just continues without it. Just like when you send an email to someone asking for some data and they send you the results a few hours later.
For example, a website might fetch data from multiple APIs, showing placeholders until the responses arrive. This approach improves the user experience because it keeps the user interface (UI) responsive and enables faster loading by processing multiple tasks in parallel.
Event-Driven Architecture
For most applications, communicating directly with external services—whether synchronously or async—is the right approach, because eventually the requested data is needed to finish the original task. But there are also use cases where it’s enough that your message was received and you don’t need to wait for a response. For example, when placing an order in an online shop, users only care that the order was submitted successfully. They don’t wait in front of the screen until it was packaged and shipped—which could take days. An email notification can inform them of progress later.
Such a scenario calls for an event-driven architecture, which takes async communication to the extreme. Here, multiple services can operate independently by exchanging information via events using a message queue (MQ), a system that temporarily stores event messages like JSON documents. These messages act as instructions, containing all relevant details about an event, such as a user’s order information. Publishers (senders) create events, and subscribers (receivers) process them based on their type, such as Order Submitted.
An event-driven architecture offers several advantages. By decoupling components, it allows publishers and subscribers to run independently, even in different programming languages or environments. This makes it easier to scale systems and assign teams to own specific components without needing to understand the full system. Additionally, one event can trigger multiple actions. For instance, when an order is packed, one system might update the user database while another generates a shipping label. This approach thereby simplifies the propagation of data to multiple services and can also facilitate replication of live data to testing and staging environments.
However, this type of architecture also brings with it some challenges. Since no single component has a full view of the system, tracking the state of a specific task, such as whether an order is still waiting or in progress, can be difficult. Furthermore, while MQs often guarantee that each message is handled at least once, the system requires careful design in case a message is processed multiple times. For example, if a subscriber crashes after processing a message but before confirming its completion, the MQ might reassign the task to another instance, potentially leading to duplicate processing. For these reasons, event-driven architectures should only be used when direct communication between services is not an option [6].
Batch Jobs
Unlike continuously running services such as web APIs, batch jobs are scripts or workflows used to process accumulated data in one go. They are particularly effective when tasks don’t require immediate processing or when grouping tasks can improve efficiency. To automate recurring tasks, batch workflows can be scheduled at specific intervals using tools like cron jobs.2
Examples of scenarios where batch jobs are useful include:
- Fetching new messages from a queue every 10 minutes to process them in bulk, reducing overhead.
- Generating a sales report for the marketing department every Monday at midnight.
- Running nightly data validation to check for data drift or anomalous patterns.
- Retraining a machine learning model every week using newly collected data to create updated recommendations, like Spotify’s “Discover Weekly” playlist [3].
For large-scale jobs, distributed systems might be necessary to ensure they complete within an acceptable timeframe.
Software Design Revisited
As your software evolves beyond a simple script, it becomes a system composed of multiple interconnected components. Each component can be viewed as a subsystem with its own defined boundaries and interface, responsible for specific functionalities while interacting with other parts of the system.
To manage this growing complexity, it’s best to think of these components—such as a GUI/frontend, API/backend, and data storage (files, databases, message queues)—as distinct layers. A clean design follows the principle of layered communication, where each layer interacts only with the layer directly below it [4]. For example, the frontend communicates with the backend, and the backend interacts with the database, avoiding “skip connections” where one layer bypasses another.
This design principle minimizes dependencies and makes the system easier to maintain: If the interface of one component changes, only the layer directly above it has to be adapted.
When you design these more complicated systems, it’s even more important to sketch the overall architecture before you start with the implementation. Visualizing how the layers interact can reveal potential bottlenecks or unnecessary complexity and gives you and your collaborators clarity on the big picture.
Instead of lumping everything into “your code” versus “the outside world” as we did in Figure 4.13, you can use swimlanes to separate the process steps performed by each component and distinguish between the different layers (Figure 6.5).
Begin by visualizing the flow from the user’s perspective, focusing on how they interact with the frontend to complete their intended task. Once the user experience is clear, continue with the backend and database layers and map out how these can support and implement each step:
- What data is needed to render the GUI?
- What data needs to be persisted in the database for later?
Finally, in accordance with the read and write (CRUD) operations on the database, you can design the ORMs used to represent and store the required data (Figure 6.1).
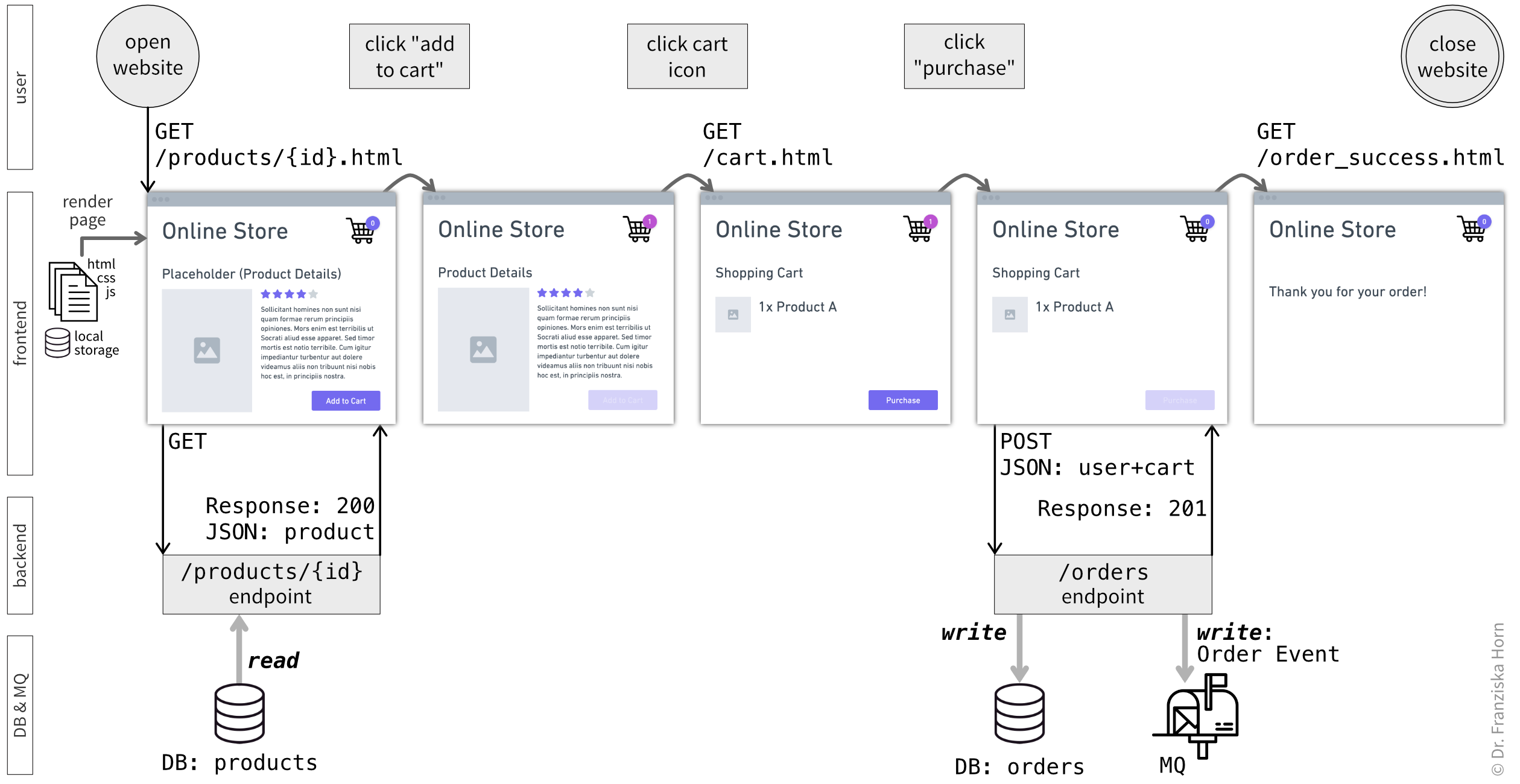
orders table to store the purchase details and submits an Order event to the message queue (MQ), thereby alerting other services that a new order needs to be packed and shipped. The endpoint returns with the status code 201 (“success”) and the frontend redirects the user to a page that tells them the purchase was successful, at which point the user closes the tab.
Delivery & Deployment
Modern software development requires reliable and efficient processes to build, test, and deploy applications [2]. Delivery and deployment strategies ensure that new features and updates are released quickly, safely, and at scale, minimizing disruptions to users while maintaining quality.
CI/CD Pipelines: Automating Development Cycles
Continuous Integration (CI) and Continuous Delivery/Deployment (CD) pipelines are the backbone of modern software practices. CI focuses on automating the process of integrating code changes into a shared repository. Every change triggers automated tests to ensure that the new code works harmoniously with the existing codebase. CD extends this by automating the preparation or deployment of changes into production, either ready for manual approval (Continuous Delivery) or fully automated (Continuous Deployment). This drastically reduces manual effort, minimizes human error, and enables faster iteration cycles.
CI/CD pipelines are either included directly into version control platforms, such as GitHub Actions and GitLab CI/CD, or can be run using external tools like Jenkins or CircleCI.
Optimizing CI/CD Pipelines
To enhance pipeline efficiency and reliability, consider the following practices:
- Dependency Caching: Cache dependencies to reduce the time spent downloading and installing them for each build.
- Selective Testing: Run only the tests affected by recent changes to speed up feedback.
- Real-Time Notifications: Notify developers immediately when a pipeline fails, enabling faster issue resolution.
Security must be a priority in any CI/CD process. For example, it is best practice to include a dependency scanning step to detect vulnerabilities in third-party libraries. Furthermore, you should never include sensitive information—such as API tokens, database credentials, or private keys—directly in your code. However, because CI jobs often require access to this information, you can securely store secrets using dedicated CI/CD variables or external secret management tools like HashiCorp Vault or AWS Secrets Manager.
A well-designed CI/CD pipeline not only saves time and resources but also ensures a consistent and high-quality delivery of software.
Containers in the Cloud
Containers, powered by tools like Docker, encapsulate applications with their dependencies, ensuring consistency across different environments. This portability simplifies deployment and reduces issues caused by environment differences.
For managing containerized applications at scale, Kubernetes (k8s) is the industry standard. Kubernetes automates the orchestration of containers, providing features like:
- Auto-scaling: Adjust resources dynamically based on workload.
- Self-healing: Automatically restart failed containers.
- Load Balancing: Distribute traffic efficiently across services.
Using Cloud Platforms
Cloud platforms like AWS, Google Cloud Platform (GCP), and Microsoft Azure offer robust infrastructures for deploying and scaling applications. For simpler workflows, managed services like Render or Heroku abstract away much of the operational complexity.
Managing costs effectively is critical in cloud deployments. Key strategies include:
- Resource Scaling: Reduce unused resources during off-peak hours.
- Serverless Computing: Use serverless models, like AWS Lambda, for infrequent workloads to save costs.
- Cost Monitoring Tools: Leverage AWS Cost Explorer or GCP Billing to track and optimize spending.
Infrastructure as Code (IaC)
Instead of configuring your cloud setup manually through the platform’s GUI, it is highly recommended to use Infrastructure as Code tools like Terraform and AWS CloudFormation to manage cloud infrastructure programmatically. The IaC configuration files can then be version-controlled, which ensures:
- Reproducible setups for consistent environments.
- Easier onboarding for new team members.
- Reduced risk of configuration drift.
Testing and Staging Environments
Deploying changes directly to production is risky. To ensure stability:
- Use staging environments that mimic production to validate changes before release.
- Maintain testing environments for early experimentation and debugging.
Techniques like A/B testing and feature toggles allow gradual rollouts or controlled exposure of new features, minimizing user disruption. This can be achieved using deployment strategies like:
- Blue-Green Deployments: Maintain two environments (blue and green) and switch traffic between them for A/B tests or to reduce downtime during updates.
- Canary Releases: Gradually expose updates to a small group of users, monitoring for issues before full deployment.
Scaling Considerations
As applications grow, scaling requires thoughtful architectural design. You should consider:
- Task Separation: For example, train machine learning models periodically as batch jobs, while keeping prediction services running continuously. This is particularly important when services have vastly different user bases (e.g., hundreds of admins versus millions of regular users), as they require varying replication rates for horizontal scaling. Especially if services rely on distinct dependencies, combining them into a single Docker container can result in a large, inefficient image, which increases the services’ startup time.
- Team Autonomy: Design services such that teams can own and work on individual components independently, thereby reducing communication overhead and speeding up development cycles [8].
Monitoring and Observability
To ensure smooth operation and detect issues proactively, monitoring and observability are essential. Focus on:
- System Performance: Monitor the “golden signals”—latency, traffic, errors, and saturation of your services. Tools like Prometheus and Grafana are commonly used for this.
- Data Quality: Track changes in input data distributions and monitor metrics like model accuracy to detect data drift.
- Synthetic Monitoring: Simulate user behavior to identify bottlenecks and improve responsiveness. Complement this with chaos engineering tools like Chaos Monkey to test your system’s resilience by deliberately introducing failures, ensuring your infrastructure can handle unexpected disruptions effectively.
- Distributed Tracing: Debug across microservices using tools like Jaeger or OpenTelemetry.
When issues arise, having a rollback strategy is crucial. Options include:
- Reverting to a stable container image.
- Rolling back database migrations.
- Using feature toggles to disable problematic updates.
By combining robust delivery pipelines, thoughtful architecture, and effective monitoring, teams can ensure that their applications remain reliable, scalable, and adaptable to changing needs.
At this point, you should have a clear understanding of:
- Which additional steps you could take to make your research project production-ready.
This use case could also be implemented using an event-driven architecture as discussed in the next section. With this setup, both players would publish their next moves to a message queue and subscribe to it to receive updates about the moves of their opponent.↩︎
Tools like Crontab Guru can help configure these schedules.↩︎