Conclusion
Now that you’ve learned a lot about the machine learning (ML) theory, it is time for a reality check.
Hype vs. Reality
In the introduction, we’ve seen a lot of examples that contribute to the ML hype. However, especially when applying ML in the manufacturing industry, for example, the reality often looks quite different and not every idea might work out as hoped:
| Hype: Big Data, Generative AI | Reality: |
|---|---|
| Database with millions of examples | 150 manual entries in an excel sheet |
| Homogeneous unstructured data (e.g., pixels, sound, text) | Measurements from different sources with different scales (e.g., temperature, flow, pressure sensors) |
| Fancy deep learning architectures | Neural networks are tricky to train and even more difficult to explain → Need to understand and trust predictions to make business decisions |
But it can be done! A good example comes from the startup alcemy, which uses ML to optimize the production of CO2-reduced cement. They describe how they overcame the above mentioned challenges in this talk.
Machine Learning is just the tip of the iceberg
You were already warned that in their day-to-day operations, data scientists usually spend only about 10% of their time doing the fun machine learning stuff, while the bulk of their work consists of gathering and cleaning data. This is true for an individual ML project. If your goal is to become a data-driven enterprise that uses AI in production for a wide range of applications, there are some additional challenges that should be addressed – but which would typically not be the responsibility of a data scientist (alone):

On the plus side, things like a centralized data infrastructure and clear governance process only need to be set up once and then all future ML projects will benefit from them.
Domain knowledge is key!
In the introduction, you’ve seen the Venn diagram showing that ML lies at the intersection of math and computer science. However, this is actually not the complete picture. In the previous chapters, you’ve hopefully picked up on the fact that in order to build trustworthy models that use meaningful features to arrive at robust conclusions, it is necessary to combine ML with some domain knowledge and understanding of the business problems, what is then often referred to as Data Science:
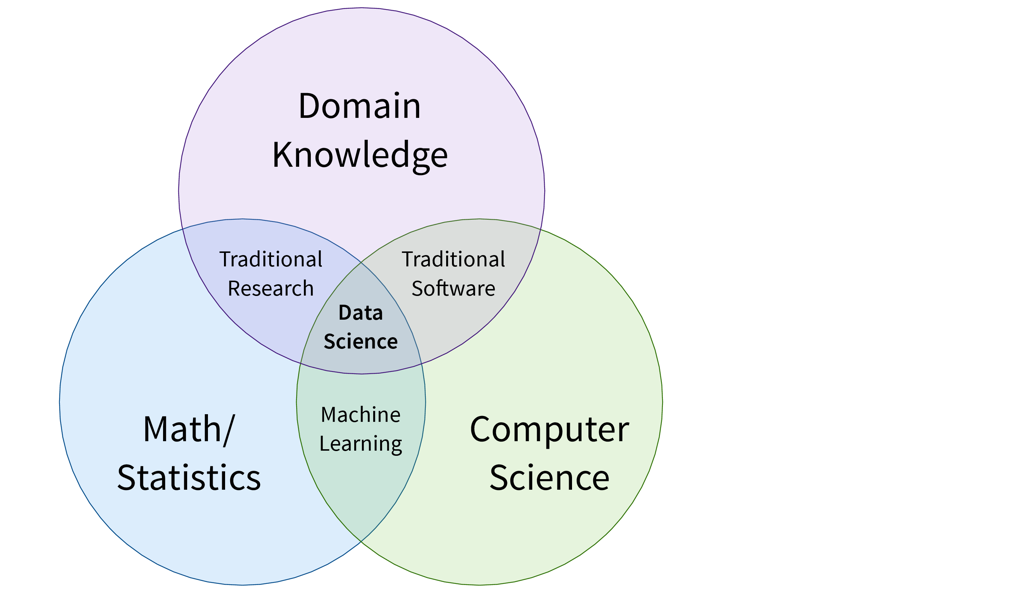
As we will argue in the next section, it is unrealistic to expect an individual data scientist to be an expert in all three areas, and we therefore instead propose three data-related roles to divide responsibilities in an organization.
Take Home Messages
- ML is and will be transforming all areas of our lives incl. work.
- ML has limitations:
- Performance: Some problems are hard.
- Data Quality & Quantity: Garbage in, garbage out!
- Causality & Adversarial Attacks ⇒ Explainability!!
- Combine ML with subject matter expertise!
- It’s an iterative process:
- Don’t expect ML to work right away!
- Monitor and update after initial release.
If you’ve now gotten curious and want to know more about how the different machine learning algorithms actually work, have a look at the full version of this book!
AI Transformation of a Company
The famous ML researcher Andrew Ng has proposed a five-step process to transform your company into a data-driven enterprise capable of using AI in production to add value.
Five steps for a successful AI Transformation by Andrew Ng
- Execute pilot projects to gain momentum
- Build an in-house AI team & data infrastructure
- Provide broad AI training (for all employees)
- Develop an AI & data strategy
- Develop internal and external communications
Recommended Materials:
→ “AI for everyone” Coursera course
→ AI Transformation Playbook

Co-Founder Google Brain
Vice President Baidu
Co-Founder Coursera
Professor @ Stanford University
[Step 1] Start with small pilot projects to understand the potential and challenges of using ML
Machine learning projects are unlike traditional software projects, where you’re usually certain that a solution at least exists and you only need to figure out an efficient way to get there. Instead, ML heavily relies on the available data. Even though it might theoretically be possible to solve your problem with ML, this might not be the case with the data you have at hand. Before implementing some big AI initiative spanning the whole company, it is therefore strongly recommended that you start with several smaller pilot projects in order to get a better feeling for what it means to rely on an AI to solve your problems.
When choosing a pilot project, the most important factor is not the Return on Investment (ROI) of the project, since here the experience with ML gained along the way should be the priority. However, it is important to choose a project that is technically feasible, i.e., which can be solved with existing ML algorithms and you don’t need years of research to develop your own fancy neural network architecture. Furthermore, you should have enough high-quality data available to get started, so you don’t spend months just on data preprocessing, e.g., due to the need to combine data from different sources within a poor data infrastructure.
If you do not yet have the necessary AI talent in-house to tackle such a project, you can also partner with external consultants, which provide the ML expertise, while you supply the subject matter expertise to ensure the pilot project is a success.
[Step 2] Set up a centralized AI team and data infrastructure to carry out bigger projects efficiently and effectively
We’ve already seen that in practice, it’s really about the intersection of Theory, Programming, and Domain Knowledge, i.e., Data Science. However, it is unlikely that you’ll find a single person that is truly competent in all three areas. Instead, people will always have a certain focus and we therefore propose three distinct roles, which also align very well with the three main steps for successfully executing an ML project:
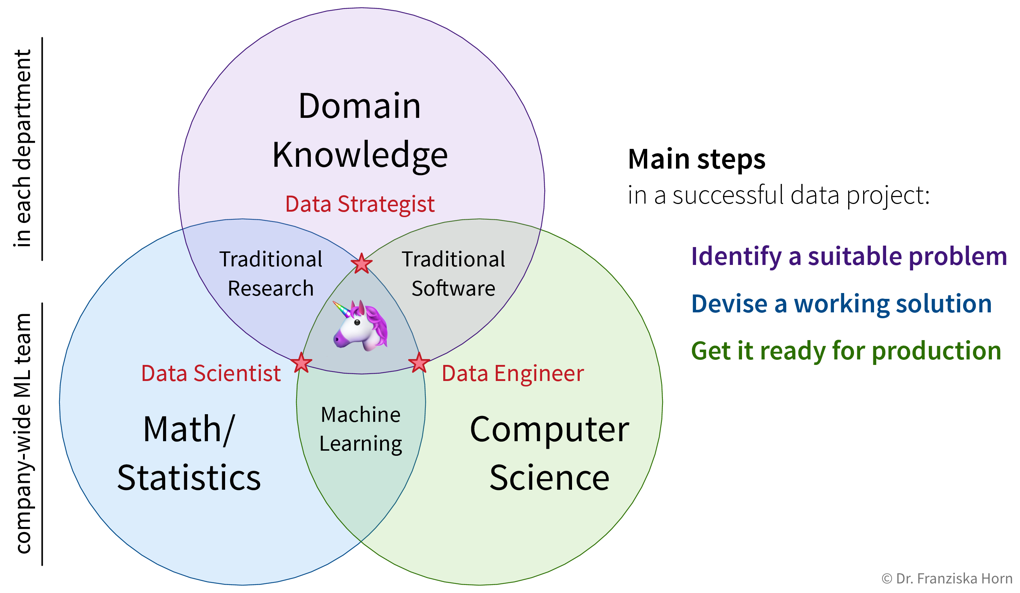
Ideally, data scientists and engineers should be in their own separate team (i.e., the “AI Team”) and work on projects from different departments like an in-house consultancy:
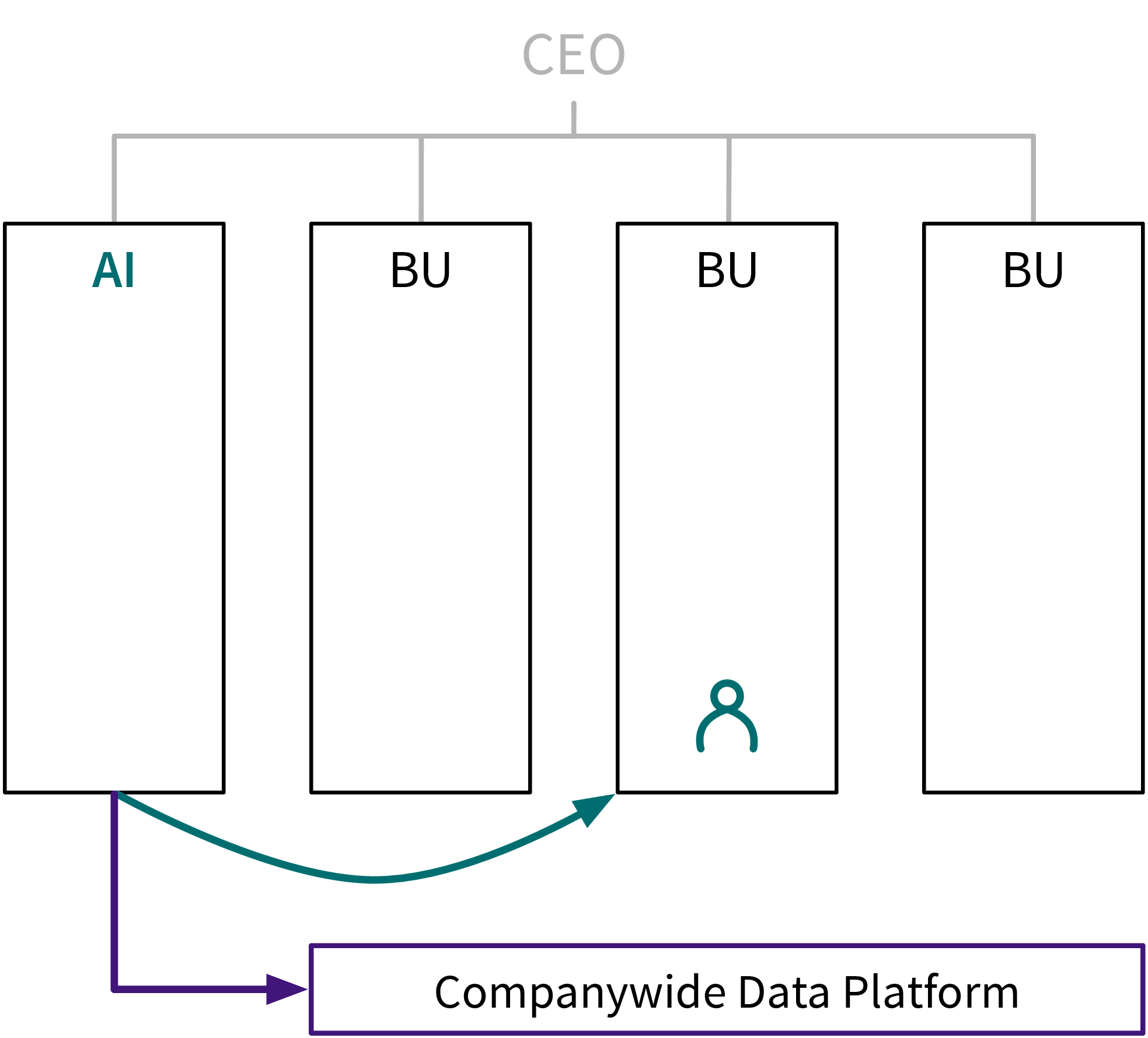
This has several advantages:
- Data scientists can discuss solutions with other ML experts → many problems will be similar from an algorithmic standpoint.
- Combine data from the whole company for a holistic analysis.
- Funding independent from individual business unit, e.g., necessary for the up front investment in data infrastructure, time required to keep up with new research, etc.
As we’ve discussed in the introduction, about 90% of the time in an ML project is spent on data wrangling. Therefore, especially in the beginning, the AI team should contain more Data Engineers than Data Scientists, so they can build a solid data infrastructure, which will save Data Scientists lots of time and headaches later.
[Step 3] Train other employees to recognize ML problems and establish a data-driven culture
While data scientists need to be intimately familiar with the algorithms they are using, other employees, especially data strategists and department leaders, should have some basic understanding of what ML is and is not capable of, such that they can identify possible ML problems and refer them to the AI team.

[Step 4] Devise a cohesive strategy with long-term goals that result in a competitive advantage
Developing a strategy might be the first impulse of an executive when confronted with a new topic such as AI. However, since AI problems are so different from other kinds of projects, it really pays off to first gain some experience with this topic (i.e., start with step 1!). After you’ve successfully completed some pilot projects and set the wheels in motion to create an AI team as well as educate the other employees to get them on board, here are a few things to consider w.r.t. a companywide strategy to give you an advantage over your competition:
- Create strategic data assets that are hard for your competition to replicate:
- Long-term planning: Which data might be valuable in the future? → Start collecting it now!
- Up-front investments: What infrastructure and processes are needed to make the data accessible to the right people?
- How can you combine data from different divisions to enable the AI team to “connect the dots” and gain a unique edge over the competition?
- What options do you have in terms of strategic data acquisition, e.g., in the form of ‘free’ products, where users pay with their data (like what Google, Facebook, etc. are doing)?
- Build AI-powered features that are a unique selling point for your products:
- Don’t try to recreate some off-the-shelf service that could be easily procured from an outside vendor, but use ML together with your unique subject matter expertise and data to build new features for your existing products to make them more appealing to your customers or open up new market segments.
- How can you establish a virtuous cycle, where your AI attracts more users, which in turn generate more data, which can then be used to train the AI to become even better and thereby attracts even more users?
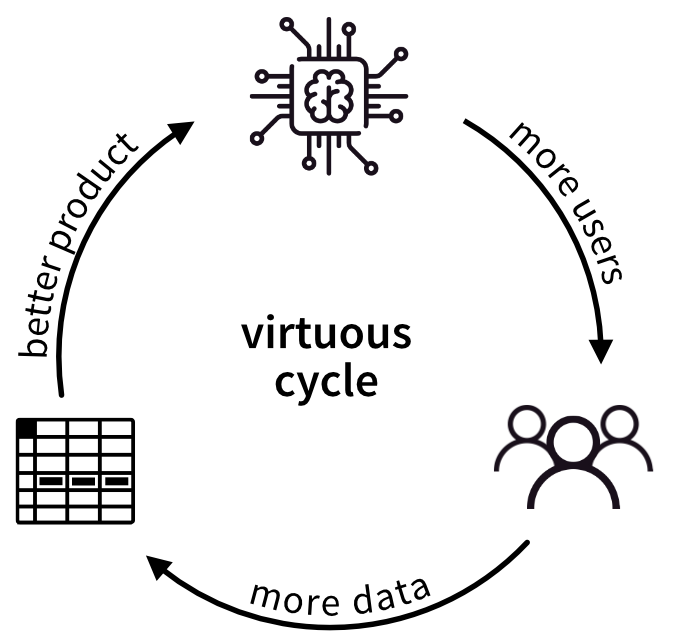
[Step 5] Communicate your success
After successfully implementing AI within the company, you should of course communicate your accomplishments. In addition to internal and external press releases, this also includes, for example, job listings, which will attract more qualified candidates if they are formulated from an informed standpoint instead of listing buzzwords.