Fazit
Nachdem wir nun viel über die Theorie des maschinellen Lernens (ML) gesprochen haben, ist es Zeit für einen Realitätscheck.
Hype vs. Realität
In der Einleitung haben wir viele Beispiele gesehen, die zum ML-Hype beigetragen haben. Doch beim Einsatz von ML beispielsweise in der Fertigungs- oder Prozessindustrie sieht die Realität oft ganz anders aus und nicht jede Idee funktioniert wie erhofft:
| Hype: Big Data, Deep Learning | Realität: |
|---|---|
Datenbank mit Millionen von Beispielen |
150 manuelle Einträge in einer Excel-Tabelle |
Homogene unstrukturierte Daten (z.B. Pixel, Audio, Text) |
Messungen aus verschiedenen Quellen mit unterschiedlichen Skalen (z.B. Temperatur-, Durchfluss-, Drucksensoren) |
Ausgefallene Deep-Learning-Architekturen |
Neuronale Netze sind aufwändig zu trainieren und noch schwieriger zu erklären |
| Aber es ist machbar! Ein gutes Beispiel kommt von dem Startup alcemy, das ML verwendet, um die Produktion von CO2-armen Zementen zu optimieren. Wie sie dabei mit den oben genannten Herausforderungen umgegangen sind, erklären sie in diesem Vortrag. |
- Machine Learning ist nur die Spitze des Eisbergs
-
Du wurdest ja bereits gewarnt, dass Data Scientists normalerweise nur etwa 10% ihrer Zeit mit den spannenden ML Methoden verbringen, während der Großteil ihrer Arbeit aus dem Sammeln und Bereinigen von Daten besteht. Dies trifft auf einzelne ML-Projekte zu. Möchte man jedoch KI produktiv für eine Vielzahl von Anwendungen einsetzen und ein datengesteuertes Unternehmen aufbauen, birgt dies weitere Herausforderungen, welche aber normalerweise nicht in der alleinigen Verantwortung einer Data Scientistin liegen:
 Siehe auch: Sculley, David, et al. “Hidden technical debt in machine learning systems.” Advances in Neural Information Processing Systems. 2015.
Siehe auch: Sculley, David, et al. “Hidden technical debt in machine learning systems.” Advances in Neural Information Processing Systems. 2015.Viele dieser Dinge, z.B. eine zentralisierte Dateninfrastruktur und ein klarer Data Governance Prozess, müssen jedoch nur einmal etabliert werden und alle zukünftigen ML-Projekte können davon profitieren.
- Fachwissen ist der Schlüssel zum Erfolg!
-
Das Venn-Diagramm in der Einleitung zeigt ML an der Schnittstelle von Mathematik und Informatik. Doch vorherige Kapitel verdeutlichten, dass es notwendig ist, ML mit Fachwissen und Verständnis für die internen Geschäftsabläufe zu kombinieren. Diese Kombination führt zu vertrauenswürdigen Modellen, die durch aussagekräftige Informationen zu robusten Schlussfolgerungen gelangen. Diese Schnittmenge wird als Data Science bezeichnet:
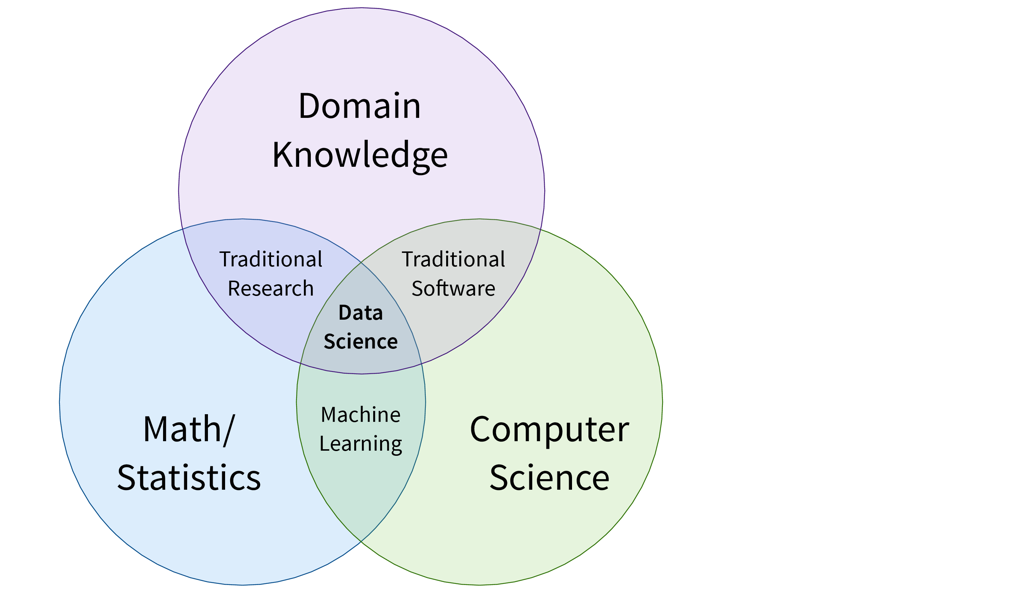
Wie wir im nächsten Kapitel begründen werden, ist es jedoch unrealistisch, von einer einzigen Data Scientistin zu erwarten, dass sie in allen drei Bereichen eine Expertin ist. Um die Verantwortlichkeiten in einer Organisation sinnvoll aufzuteilen, empfehlen wir daher ein Aufgabensplitting in drei datenbezogene Bereiche.
Wenn du jetzt neugierig geworden bist und mehr darüber erfahren möchtest, wie die verschiedenen ML-Algorithmen im Detail funktionieren, wirf einen Blick in die Vollversion dieses Buches!