[Fehler #5] Daten & Konzept Drifts
Wir dürfen nie vergessen, dass sich die Welt permanent verändert und Modelle regelmäßig mit neuen Daten nachtrainiert werden müssen. Nur so können sie sich an diese geänderten Umstände anpassen.
|
ML versagt leise! D.h. auch wenn alle Vorhersagen falsch sind, stürzt das Programm nicht einfach mit einer Fehlermeldung ab. → Wir brauchen ein konstantes Monitoring, um Veränderungen zu erkennen, die zu einer Verschlechterung der Modellperformance führen! |
Eins der größten Probleme in der Praxis: Daten und Konzept-Drifts:
Die Vorhersagegenauigkeit eines Modells lässt schnell nach, wenn die Daten im Produktivbetrieb von den Trainingsdaten abweichen. Dabei unterscheiden wir zwischen:
-
Daten-Drift: Verteilung der gemessenen Werte einer oder mehrerer Variablen verändert sich. Dies kann entweder die Inputs \(X\) betreffen, dann nennt sich das Covariate Shift oder die Outputs \(y\), dann sprechen wir von Label Shift.
-
Konzept-Drift: Input/Output Zusammenhang \(X \to y\) ändert sich, d.h. exakt die gleichen Inputs \(X\) resultieren plötzlich in einem anderen Output \(y\).
In beiden Fällen ändert sich etwas, das für unsere ML Anwendung wichtig ist, in der Welt. Wenn unsere gesammelten Daten diese Veränderung abbilden, spricht man von Daten-Drift. Wenn wir diese Veränderung nicht in unseren Inputdaten sehen können, handelt es sich um einen Konzept-Drift.
Beispiel: Anhand der Produktionsbedingungen inkl. der Größe des produzierten Teils (\(X\)) möchten wir vorhersagen ob das jeweilige Produkt in Ordnung oder Ausschuss ist (\(y\)):
-
Daten-Drift: Der Hersteller produzierte früher nur kleine Teile, nun aber auch größere Teile.
-
Konzept-Drift: Während früher 10% Ausschuss produziert wurden, wird nach einer Reparatur der Maschine bei gleichen Produktionsbedingungen (\(X\)) nur noch 5% Ausschuss (\(y\)) produziert.
| Covarite Shifts können, ohne dass es einen Konzept-Drift gibt, zu Label Shifts führen, wenn die Inputvariable kausal mit der Outputvariable verbunden ist. Zum Beispiel wurde ein Modell, das Krebs (\(y\)) bei Patienten basierend auf dem Alter (\(x\)) vorhersagt, mit einem Datensatz trainiert, der größtenteils aus älteren Menschen besteht, die naturgemäß auch häufiger an Krebs erkranken. In der Praxis wird das Modell dann auf Patienten jeden Alters angewendet (Covariate Shift), also auch auf mehr junge Menschen, die seltener an Krebs erkranken (Label Shift). |
Gründe für Drifts & Vorbeugende Maßnahmen
Daten- und Konzeptdrifts entstehen sowohl durch die Art wie die Daten gesammelt werden, als auch durch externe Ereignisse außerhalb unserer Kontrolle.
| Diese Veränderungen können entweder graduell sein (z.B. Sprachen ändern sich schrittweise wenn neue Wörter geprägt werden; ein Kameraobjektiv staubt mit der Zeit ein), oder sie können als plötzlicher Schock auftreten (z.B. jemand reinigt das Kameraobjektiv; als die COVID-19-Pandemie ausbrach, wechselten plötzlich viele Menschen zum Online-Shopping, wodurch Systeme zur Erkennung von Kreditkartenbetrug erstmal irrtümlich Alarm schlugen). |
- Geändertes Datenschema:
-
Viele Probleme entstehen intern und könnten vermieden werden, zum Beispiel:
-
Die Benutzeroberfläche zur Datensammlung ändert sich, zum Beispiel wurde eine Größe zuvor in Metern erfasst und wird jetzt in Zentimetern erfasst.
-
Die Sensor-Konfiguration ändert sich, beispielsweise wird in einer neuen Version eines Geräts ein anderer Sensor verwendet, der jedoch weiterhin Werte unter dem gleichen Variablennamen wie der alte Sensor aufzeichnet.
-
Die als Inputs für das Modell verwendeten Features ändern sich, zum Beispiel werden zusätzliche erstellte Features eingeführt, jedoch wurde die Feature-Transformations-Pipeline nur im Trainingscode geändert, noch nicht im Produktionscode.
⇒ In diesen Fällen sollte idealerweise ein Fehler geworfen werden, zum Beispiel könnten wir einige Tests vor der Anwendung des Modells einbauen, um sicherzustellen, dass wir die erwartete Anzahl von Features erhalten, deren Datentypen (z.B. Text oder Zahlen) wie erwartet sind und die Werte grob im erwarteten Bereich für das jeweilige Feature liegen. Darüber hinaus müssen andere Teams im Unternehmen darüber informiert werden, dass ein ML-Modell auf ihren Daten basiert, damit sie das Data-Science-Team rechtzeitig über Änderungen informieren können.
-
- Daten-Drifts:
-
Daten-Drifts treten auf, wenn unser Modell Vorhersagen für Stichproben treffen muss, die sich von den Trainingsdaten unterscheiden. Das kann zum Beispiel daran liegen, dass bestimmte Bereiche der Trainingsdomäne unterrepräsentiert waren. Im Extremfall könnte das Modell sogar gezwungen sein, über die Trainingsdomäne hinaus zu extrapolieren. Dies könnte beispielsweise durch folgende Gründe verursacht werden:
-
Veränderte Stichprobenauswahl, zum Beispiel wenn das Unternehmen kürzlich in ein anderes Land expandiert ist oder nach einer gezielten Marketingkampagne die Website von einer neuen Nutzergruppe besucht wird.
-
Feindseliges Verhalten, zum Beispiel wenn Spammer ständig ihre Nachrichten anzupassen, um Spam-Filter zu umgehen. Vor zehn Jahren hätte ein Mensch eine Spam-Nachricht von heute auch als Spam erkannt (die Bedeutung von Spam hat sich also nicht geändert), aber diese ausgefeilteren Nachrichten waren damals nicht im Trainingsdatensatz enthalten. Das macht es für ML-Modelle schwierig, diese Muster zu erkennen.
⇒ Daten-Drifts können als Gelegenheit betrachtet werden, unseren Trainingsdatensatz zu erweitern und das Modell mit mehr Daten von unterrepräsentierten Untergruppen neu zu trainieren. Wie jedoch im vorherigen Abschnitt zu modellbasierter Diskriminierung erläutert wurde, bedeutet dies oft, dass diese unterrepräsentierten Untergruppen zunächst mit einem weniger effektiven Modell arbeiten müssen, beispielsweise eine Spracherkennungsfunktion, die bei Frauen schlechter funktioniert als bei Männern. Daher ist es wichtig, Untergruppen zu identifizieren, bei denen das Modell möglicherweise schlechtere Ergebnisse liefert, idealerweise mehr Daten aus diesen Gruppen zu sammeln oder zumindest beim Modelltraining und -evaluierung diesen Datenpunkten größere Beachtung zu schenken.
-
- Konzept-Drifts:
-
Konzept-Drifts treten auf, wenn externe Veränderungen oder Ereignisse eintreten, die wir nicht in unseren Daten erfasst haben oder die die Bedeutung unserer Daten verändern. Das bedeutet, dass genau dieselben Input Features plötzlich zu unterschiedlichen Outputs führen. Ein Grund kann sein, dass uns eine Variable fehlt, die einen direkten Einfluss auf den Output hat, zum Beispiel:
-
Unser Prozess reagiert auf Temperatur und Luftfeuchtigkeit, aber wir haben nur die Temperatur aufgezeichnet und nicht die Luftfeuchtigkeit. Wenn sich also die Luftfeuchtigkeit ändert, führen dieselben Temperaturwerte zu unterschiedlichen Outputs. ⇒ Luftfeuchtigkeit zusätzlich als Input Feature im Modell aufnehmen.
-
Saisonale Trends führen zu Veränderungen in der Beliebtheit von Sommer- gegenüber Winterkleidung. ⇒ Monat / Außentemperatur als zusätzliches Input Feature hinzufügen.
-
Besondere Ereignisse, wie zum Beispiel wenn ein Prominenter unser Produkt in den sozialen Medien erwähnt oder Menschen aufgrund von Lockdowns während einer Pandemie ihr Verhalten ändern. ⇒ Obwohl es schwer sein kann, diese Ereignisse im Voraus zu prognostizieren, können wir, wenn sie eintreten, ein zusätzliches Feature wie ‘während des Lockdowns’ aufnehmen, um die in diesem Zeitraum gesammelten Daten von den übrigen zu unterscheiden.
-
Degenerative Feedbackschleifen, d.h., die Existenz des Modells ändert das Verhalten der Benutzer, zum Beispiel veranlasst ein Empfehlungssystem Benutzer dazu, auf Videos zu klicken, nur weil sie empfohlen wurden. ⇒ Als zusätzliches Feature aufnehmen, ob das Video empfohlen wurde oder nicht, um herauszufinden, wie viel von “Benutzer hat auf Element geklickt” auf die Empfehlung zurückzuführen ist und wie viel auf das natürliche Verhalten des Benutzers.
Zusätzlich können Konzept-Drifts durch Ereignisse verursacht werden, die die Bedeutung der aufgezeichneten Daten ändern, zum Beispiel:
-
Inflation: 1 Euro im Jahr 1990 hatte einen höheren Wert als 1 Euro heute. ⇒ Daten Inflationsbereinigen oder die Inflationsrate als zusätzliches Input Feature aufnehmen.
-
Ein in Wasser getauchter Temperatursensor sammelt Kalkablagerungen, und nach einer Weile ist die Temperaturmessung nicht mehr genau. Zum Beispiel misst ein sauberer Sensor bei einer tatsächlichen Temperatur von 90 Grad die exakten 90 Grad, aber nachdem er einige Schichten Kalk angesammelt hat, misst er unter denselben Bedingungen nur noch 89 Grad. Während unser Output von der wahren Temperatur beeinflusst wird, haben wir nur Zugriff auf die Sensormessung für die Temperatur, die auch durch den Zustand des Sensors selbst bestimmt wird. ⇒ Versuche, die Kalkablagerung zu schätzen, zum Beispiel basierend auf der Anzahl der Tage seit der letzten Reinigung des Sensors (was auch bedeutet, dass solche Wartungsereignisse irgendwo erfasst werden müssen!).
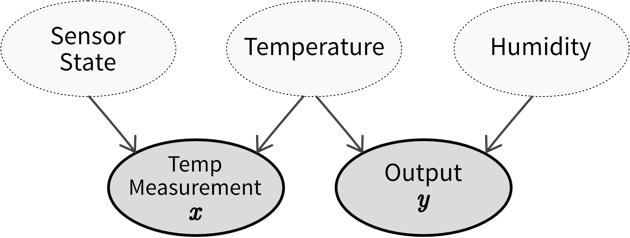 Kausaldiagramm, das zeigt, wie unser beobachteter Input \(x\) (Temperaturmessung) und Output \(y\) durch versteckte Variablen beeinflusst werden (auf die wir keinen direkten Zugriff haben). Diese versteckten Variablen sind der Zustand des Temperatursensors (d.h. wie viel Kalk sich angesammelt hat), die tatsächliche Temperatur und die Luftfeuchtigkeit (für die wir noch keinen Sensor installiert haben). Wenn der Sensorzustand und die Luftfeuchtigkeit konstant bleiben, können wir den Output aus der Temperaturmessung vorhersagen. Wenn sich jedoch einer dieser Werte ändert, treten Konzept-Drifts auf. Daher sollten wir versuchen, Schätzungen dieser versteckten Variablen in unser Modell aufzunehmen, um diese Veränderungen zu berücksichtigen.
Kausaldiagramm, das zeigt, wie unser beobachteter Input \(x\) (Temperaturmessung) und Output \(y\) durch versteckte Variablen beeinflusst werden (auf die wir keinen direkten Zugriff haben). Diese versteckten Variablen sind der Zustand des Temperatursensors (d.h. wie viel Kalk sich angesammelt hat), die tatsächliche Temperatur und die Luftfeuchtigkeit (für die wir noch keinen Sensor installiert haben). Wenn der Sensorzustand und die Luftfeuchtigkeit konstant bleiben, können wir den Output aus der Temperaturmessung vorhersagen. Wenn sich jedoch einer dieser Werte ändert, treten Konzept-Drifts auf. Daher sollten wir versuchen, Schätzungen dieser versteckten Variablen in unser Modell aufzunehmen, um diese Veränderungen zu berücksichtigen.⇒ Vor dem Training eines Modells sollten die Daten untersucht werden, um Fälle zu identifizieren, bei denen identische Inputs unterschiedliche Outputs ergeben. Wenn möglich, sollten zusätzliche Input Features aufgenommen werden, um diese Variationen zu berücksichtigen. Eine schlechte Performance des Modells auf dem Testdatensatz deutet häufig darauf hin, dass relevante Inputs fehlen, was die Anfälligkeit für zukünftige Konzept-Drifts erhöht. Selbst wenn die richtigen Variablen verwendet werden, um einen Konzept-Drift zu erfassen, kann häufiges Nachtrainieren der Modelle dennoch notwendig sein. Zum Beispiel können unterschiedliche Zustände des Konzepts ungleichmäßig in den Trainingsdaten vorhanden sein, was zu Daten-Drifts führen kann (z.B. mehr Daten, die im Winter gesammelt wurden als in den frühen Sommermonaten). Wenn es nicht möglich ist, Variablen einzubeziehen, die den Konzept-Drift abbilden, könnte es notwendig sein, Datenpunkte aus dem ursprünglichen Trainingsdatensatz zu entfernen, die nicht der neuen Input/Output-Beziehung entsprechen, bevor das Modell erneut trainiert wird.
-
| Der beste Weg, Daten und Konzept-Drifts entgegenzuwirken, besteht darin, das Modell häufig mit neuen Daten zu trainieren. Dies kann entweder nach einem fixen Zeitplan erfolgen (z.B. jedes Wochenende, je nachdem, wie schnell sich die Daten ändern) oder wenn das Monitoringsystem Alarm schlägt, weil es Drifts in den Inputs oder eine verschlechterte Modellperformance festgestellt hat. |