ML Geschichte: Warum jetzt?
Warum gibt es einen solchen Anstieg von ML Anwendungen? Allgegenwärtig ist ML nicht nur in unserem Alltag, auch die Zahl der jährlich veröffentlichten Forschungsarbeiten zu dem Thema ist exponentiell gestiegen:
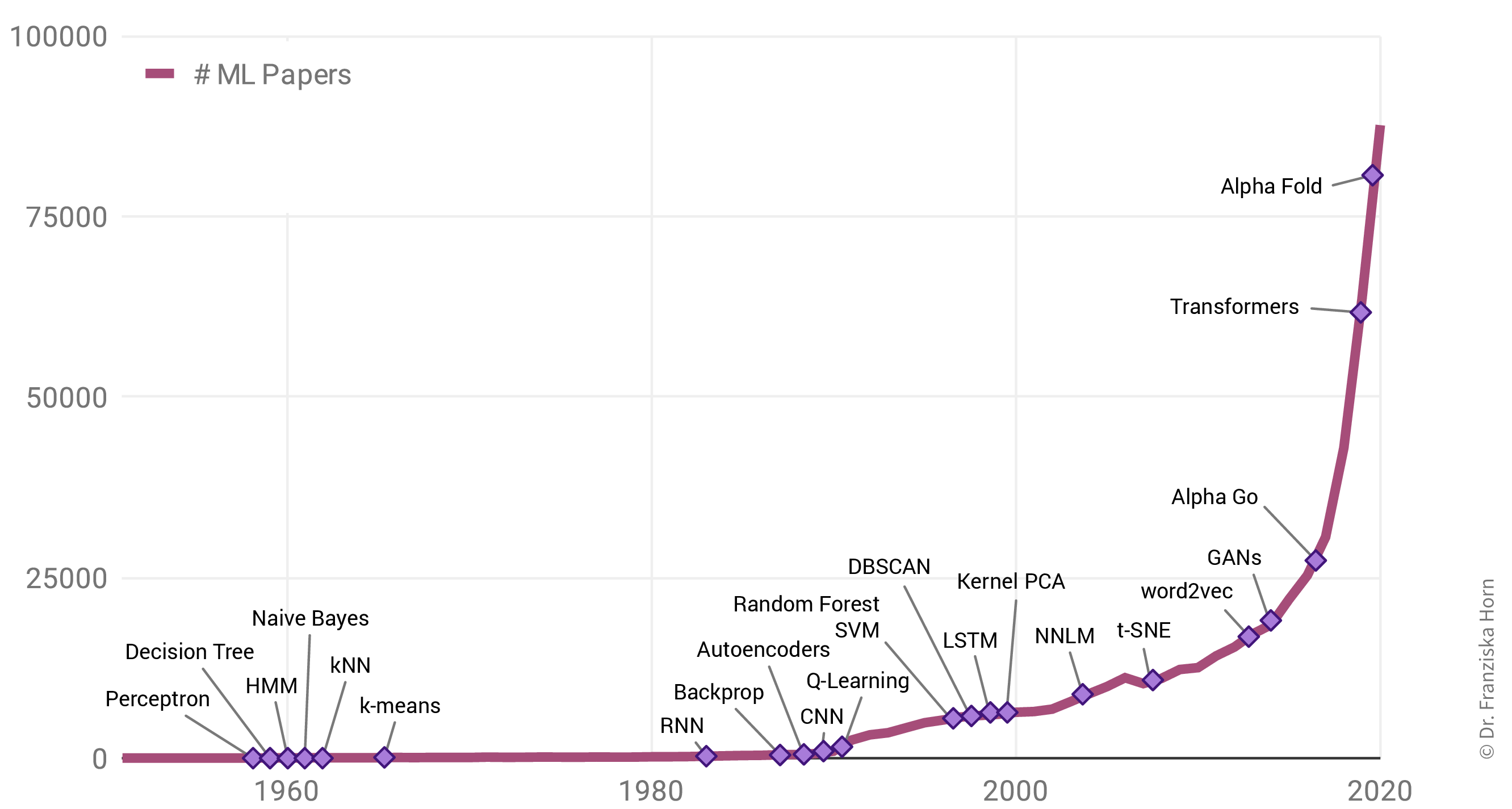
Interessanterweise liegt das aber nicht etwa an einer Fülle bahnbrechender theoretischer Errungenschaften in den letzten Jahren (in der Grafik als violette Rauten gekennzeichnet). Im Gegenteil: Viele der heute verwendeten Algorithmen wurden bereits Ende der 50er / Anfang der 60er Jahre entwickelt. So ist beispielsweise das Perzeptron der Vorläufer von neuronalen Netzen, die hinter allen im letzten Abschnitt gezeigten Beispielen stecken. Die wichtigsten neuronalen Netzarchitekturen, Recurrent Neural Networks (RNN, “rekurrente neuronale Netze”) und Convolutional Neural Networks (CNN, “faltende neuronale Netze”), welche die Grundlage für moderne Sprach- bzw. Bildverarbeitung bilden, wurden in den frühen 80er und 90er Jahren entwickelt. Aber zu dieser Zeit hatten wir noch nicht die Rechenressourcen, um diese Modelle für mehr als kleine Experimente zu verwenden.
Aufgrund dessen korreliert der Anstieg der ML-Publikationen stärker mit der Anzahl der Transistoren auf CPUs (also den regulären Prozessoren in normalen Computern) und GPUs (Grafikkarten, die die Arten von Berechnungen parallelisieren, die zum effizienten Trainieren von neuronalen Netzwerkmodellen erforderlich sind):
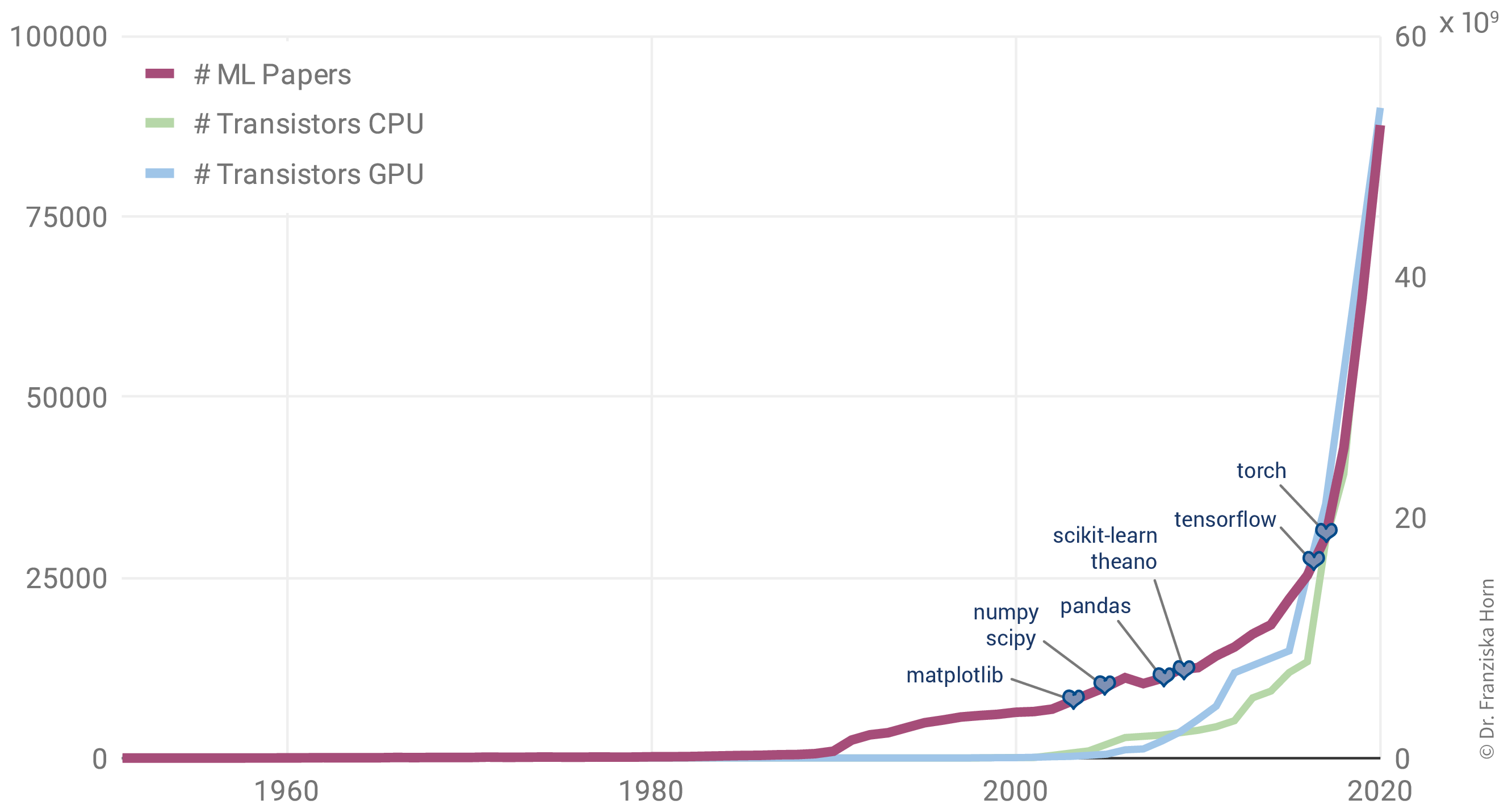
Darüber hinaus hat die Veröffentlichung vieler Open-Source-Bibliotheken wie scikit-learn (für traditionelle ML-Modelle) und theano, tensorflow und (py)torch (für die Implementierung neuronaler Netze) die Verwendung von ML-Algorithmen in anderen Fachbereichen deutlich erleichtert.
| Einerseits demokratisieren solche Bibliotheken die Verwendung von ML, andererseits resultiert eine Nutzung ohne Wissen über die theoretischen Grundlagen auch in Fehlanwendungen. Die Modelle zeigen dann oft nicht die erwartete Performance, was zu (deplatzierter) Enttäuschung führt. Im ungünstigsten Fall kann es passieren, dass die Modelle bestimmte Teile der Bevölkerung diskriminieren, z.B. Kreditbewertungsalgorithmen, die von Banken verwendet werden und die aufgrund von Verzerrungen in den historischen Daten Frauen systematisch Kredite zu höheren Zinssätzen anbieten als Männern. Wir werden solche Probleme im Kapitel zur Vermeidung häufiger Fehler besprechen. |
Ein weiterer Faktor, der zur Verbreitung von ML beiträgt, ist die Verfügbarkeit von (digitalen) Daten. Unternehmen wie Google, Amazon und Meta hatten hier einen Vorsprung, da ihr Geschäftsmodell von Anfang an auf Daten aufgebaute. Andere Unternehmen holen inzwischen langsam auf. Während traditionelle ML-Modelle nur minimal von diesen verfügbaren Daten profitieren, können große neuronale Netzmodelle mit vielen Freiheitsgraden jetzt ihr volles Potenzial entfalten, indem sie aus all den Texten und Bildern lernen, die täglich im Internet veröffentlicht werden:
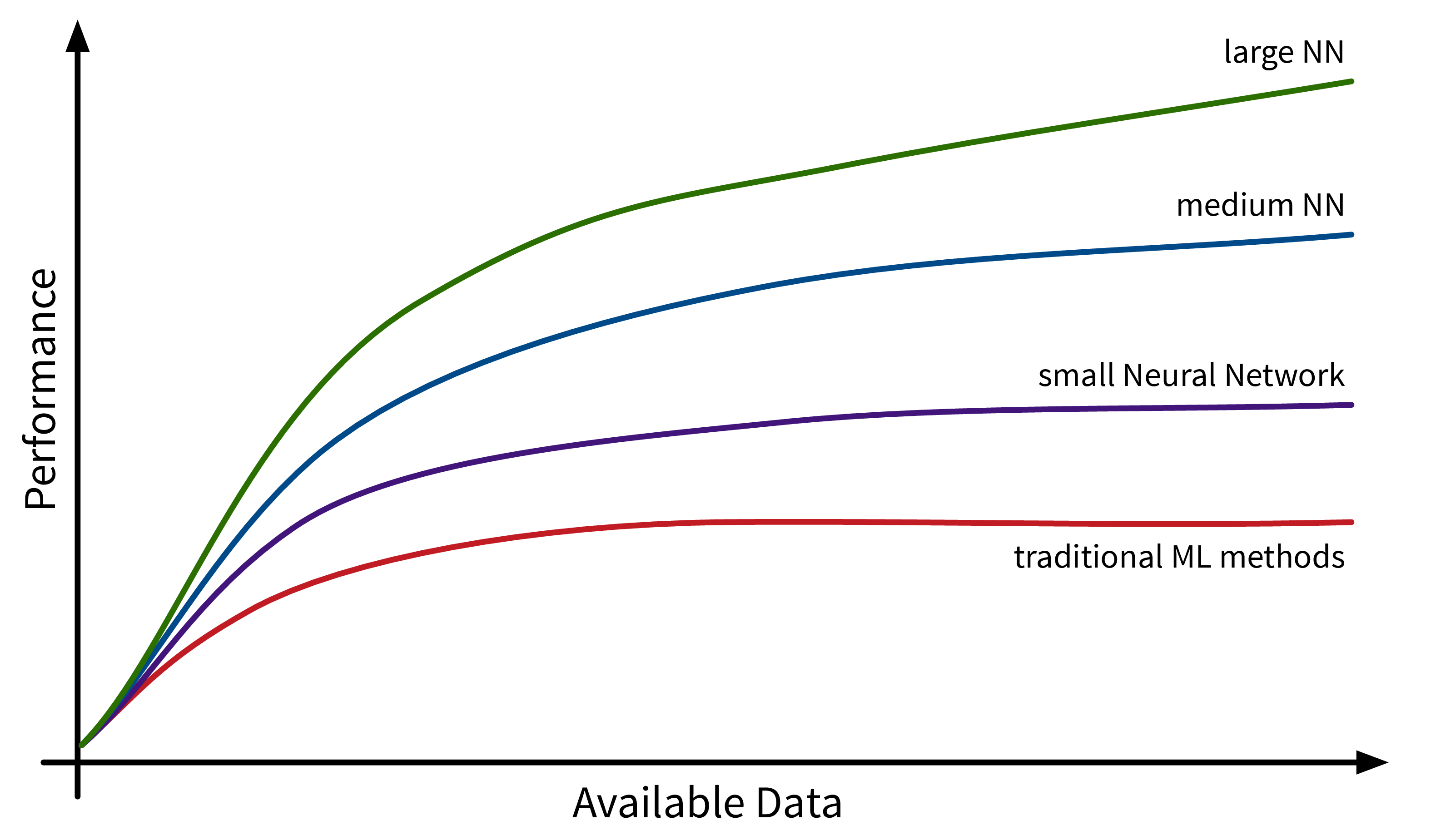
Aber wir sind nach wie vor noch weit von Artificial General Intelligence (AGI, “künstliche allgemeine Intelligenz” oder “starke KI”) entfernt!

Eine AGI ist ein hypothetisches Computersystem mit menschenähnlichen kognitiven Fähigkeiten, das in der Lage wäre, ein breites Spektrum von Aufgaben in verschiedenen Bereichen zu verstehen, zu lernen und auszuführen. Speziell würde eine AGI nicht nur bestimmte Aufgaben ausführen, sondern auch ihre Umgebung verstehen und daraus lernen, autonom Entscheidungen treffen und ihr Wissen auf vollkommen neue Situationen verallgemeinern.
In der Praxis wird stattdessen Artificial Narrow Intelligence (ANI, auch “schwache KI”) verwendet: Modelle, die explizit programmiert wurden, um eine bestimmte Aufgabe zu lösen, z.B. Texte von einer Sprache in eine andere übersetzen. Diese Modelle können nicht (eigenständig) verallgemeinern und neue Aufgaben lernen, sprich das maschinelle Übersetzungsmodell wird nicht morgen auf die Idee kommen, dass es nun auch Gesichter in Bildern erkennen will. Natürlich kann man mehrere einzelne ANIs in einem großen Programm kombinieren, um so mehrere verschiedene Aufgaben zu lösen, aber auch diese Sammlung von ANIs ist nicht in der Lage, selbstständig neue Fähigkeiten darüber hinaus zu erlernen.
Viele KI-Forscher sind derzeit überzeugt, dass wir zumindest mit den aktuell verwendeten Methoden (z.B. den Large Language Models (LLMs) wie ChatGPT von OpenAI) wahrscheinlich nie eine echte menschenähnliche AGI erschaffen werden. Speziell mangelt es diesen KI-Systemen noch immer an einem allgemeinen Verständnis von Kausalität und physikalischen Gesetzen wie der Objektpermanenz — etwas, das sogar viele Haustiere verstehen.
Wenn du mehr über die Mängel aktueller KI-Systeme erfahren möchtest, sind die Blogartikel von Gary Marcus sehr zu empfehlen!