Conclusion
Now that you’ve learned a lot about the machine learning (ML) theory, especially the different algorithms:
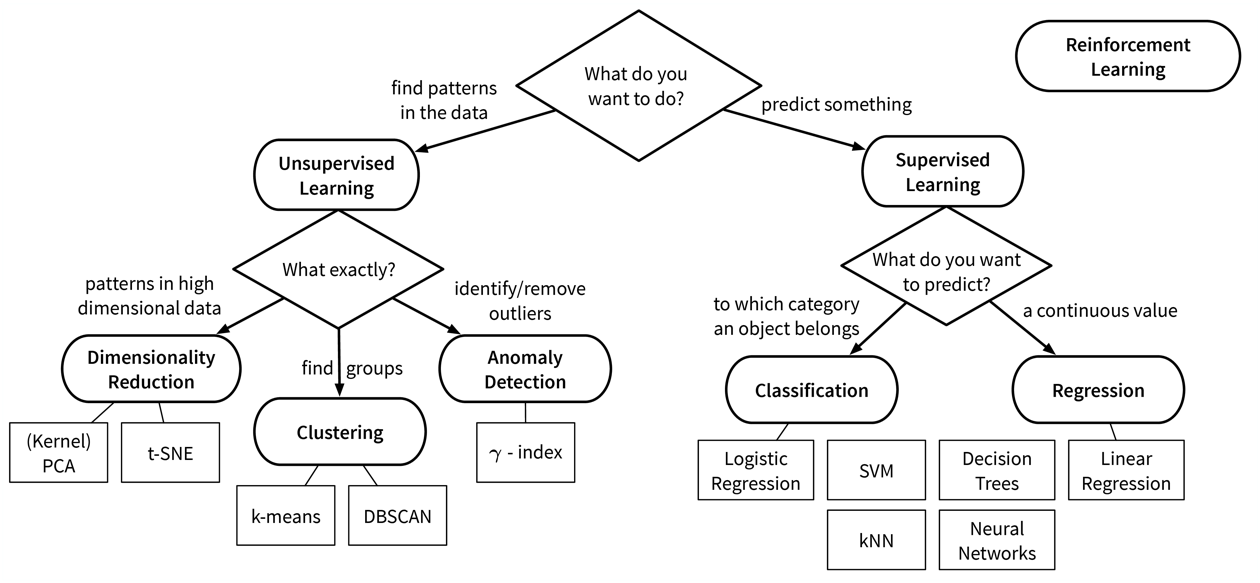
…it is time for a reality check.
Hype vs. Reality
In the introduction, we’ve seen a lot of examples that contribute to the ML hype. However, especially when applying ML in the manufacturing industry, for example, the reality often looks quite different and not every idea might work out as hoped:
| Hype: Big Data, Deep Learning | Reality: |
|---|---|
Database with millions of examples |
150 manual entries in an excel sheet |
Homogeneous unstructured data (e.g., pixels, sound, text) |
Measurements from different sources with different scales (e.g., temperature, flow, pressure sensors) |
Fancy deep learning architectures |
Neural networks are tricky to train and even more difficult to explain |
| But it can be done! A good example comes from the startup alcemy, which uses ML to optimize the production of CO2-reduced cement. They describe how they overcame the above mentioned challenges in this talk. |
- Machine Learning is just the tip of the iceberg
-
You were already warned that in their day-to-day operations, data scientists usually spend only about 10% of their time doing the fun machine learning stuff, while the bulk of their work consists of gathering and cleaning data. This is true for an individual ML project. If your goal is to become a data-driven enterprise that uses AI in production for a wide range of applications, there are some additional challenges that should be addressed — but which would typically not be the responsibility of a data scientist (alone):
 See also: Sculley, David, et al. “Hidden technical debt in machine learning systems.” Advances in Neural Information Processing Systems. 2015.
See also: Sculley, David, et al. “Hidden technical debt in machine learning systems.” Advances in Neural Information Processing Systems. 2015.On the plus side, things like a centralized data infrastructure and clear governance process only need to be set up once and then all future ML projects will benefit from them.
- Domain knowledge is key!
-
In the introduction, you’ve seen the Venn diagram showing that ML lies at the intersection of math and computer science. However, this is actually not the complete picture. In the previous chapters, you’ve hopefully picked up on the fact that in order to build trustworthy models that use meaningful features to arrive at robust conclusions, it is necessary to combine ML with some domain knowledge and understanding of the business problems, what is then often referred to as Data Science:
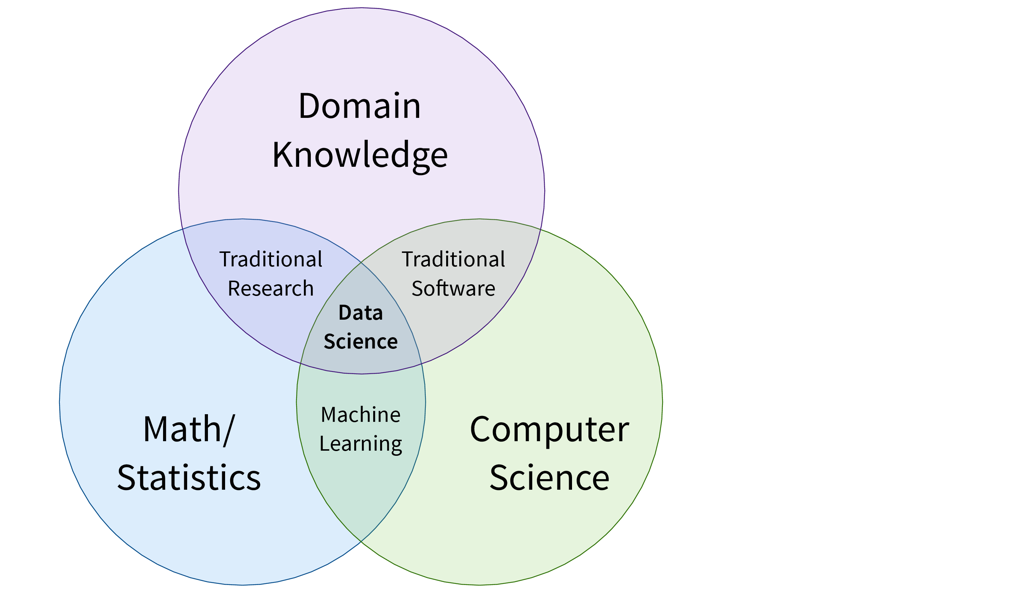
As we will argue in the next section, it is unrealistic to expect an individual data scientist to be an expert in all three areas, and we therefore instead propose three data-related roles to divide responsibilities in an organization.