ML history: Why now?
Why is there such a rise in ML applications? Not only in our everyday lives has ML become omnipresent, but also the number of research paper published each year has increased exponentially:
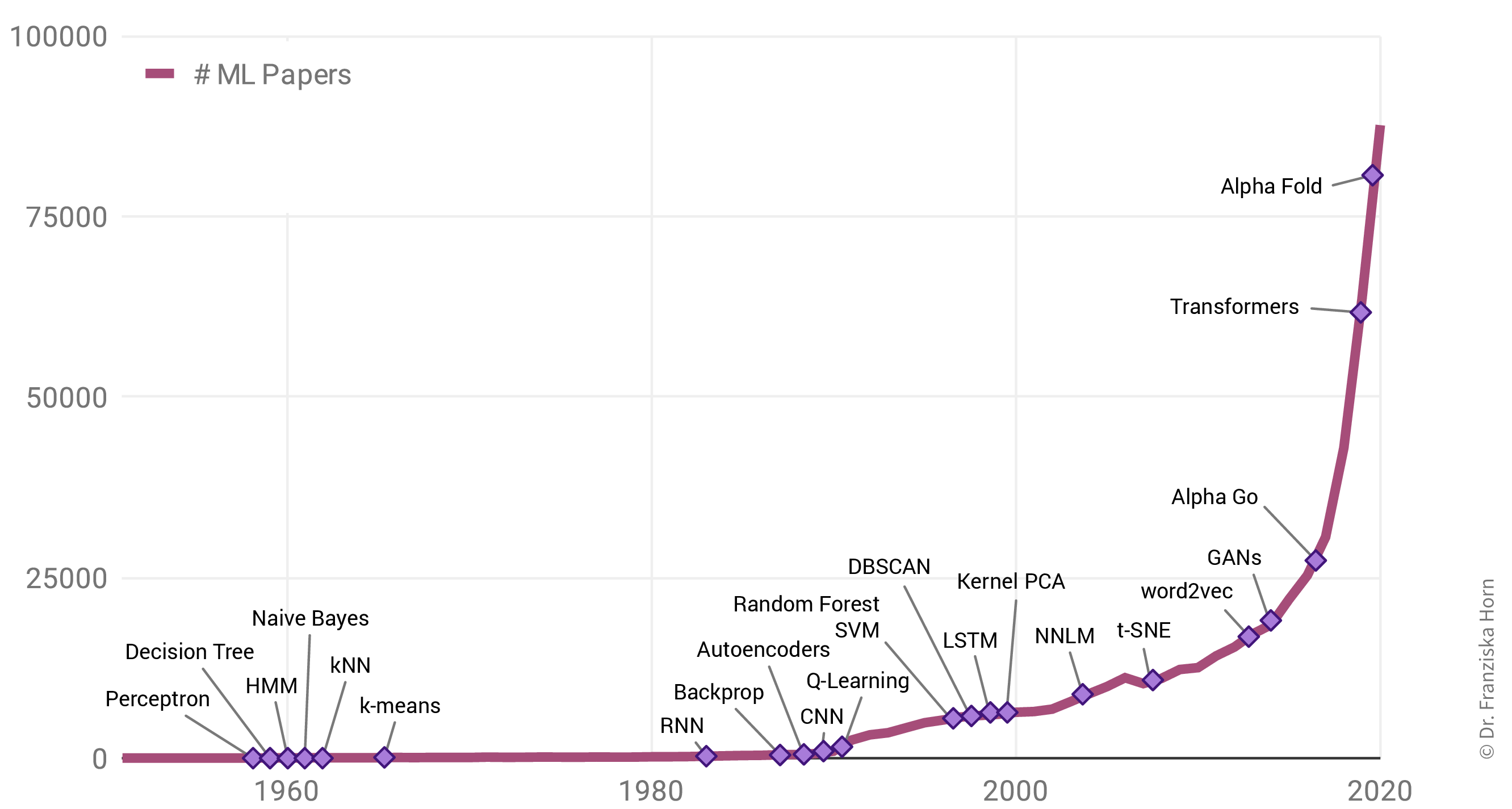
Interestingly, this is not due to an abundance of groundbreaking theoretical accomplishments in the last few years (indicated as purple diamonds in the plot), but rather many of the algorithms used today were actually developed as far back as the late 50s / early 60s. For example, the perceptron is a precursor of neural networks, which are behind all the examples shown in the last section. Indeed, the most important neural network architectures, recurrent neural networks (RNN) and convolutional neural networks (CNN), which provide the foundation for state-of-the-art language and image processing respectively, were developed in the early 80s and 90s. But back then we lacked the computational resources to use them on anything more than small toy datasets.
This is why the rise in ML publications correlates more closely with the number of transistors on CPUs (i.e., the regular processors in normal computers) and GPUs (graphics cards, which parallelize the kinds of computations needed to train neural network models efficiently):
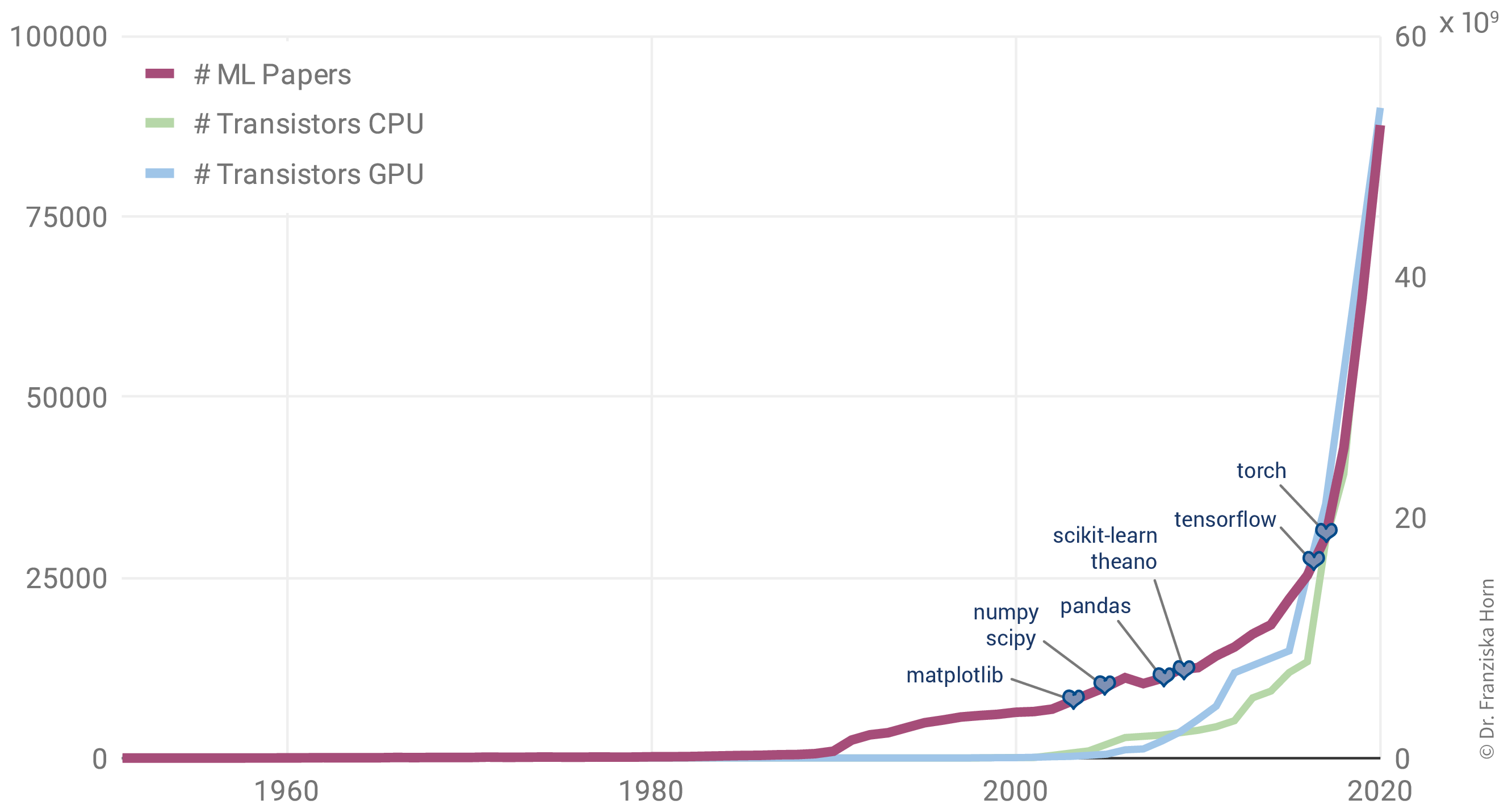
Additionally, the release of many open source libraries, such as scikit-learn (for traditional ML models) and theano, tensorflow, and (py)torch (for the implementation of neural networks), has further facilitated the use of ML algorithms in many different fields.
| While these libraries democratize the use of ML, unfortunately, this also brings with it the downside that ML is now often applied without a sound understanding of the theoretical underpinnings of these algorithms or their assumptions about the data. This can result in models that don’t show the expected performance and subsequently some (misplaced) disappointment in ML. In the worst case, it can lead to models that discriminate against certain parts of the population, e.g., credit scoring algorithms used by banks that systematically give women loans at higher interest rates than men due to biases encoded in the historical data used to train the models. We’ll discuss these kinds of issues in the chapter on avoiding common pitfalls. |
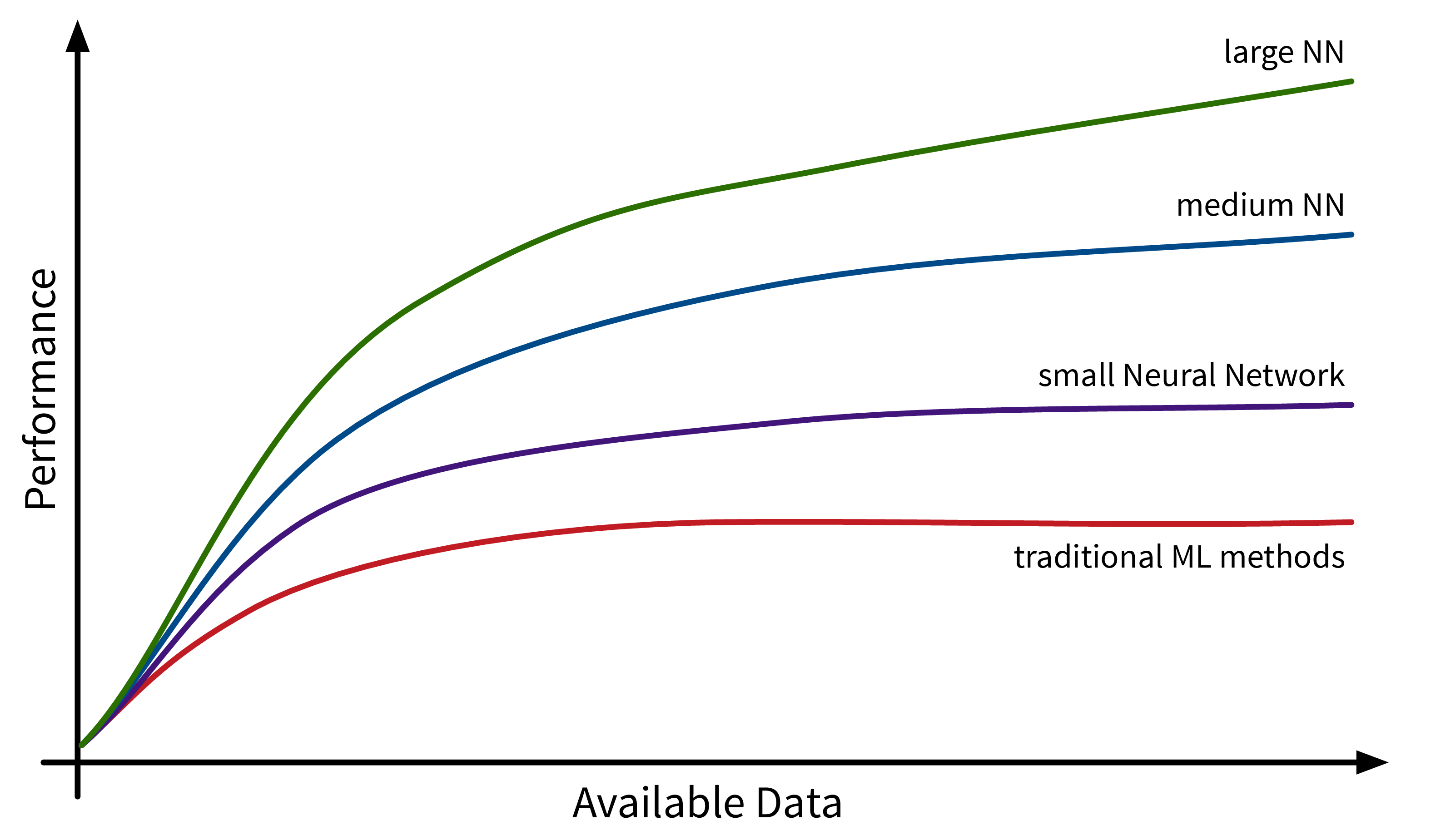
Another factor driving the spread of ML is the availability of (digital) data. Companies like Google, Amazon, and Meta have had a head start here, as their business model was built around data from the start, but other companies are starting to catch up. While traditional ML models do not benefit much from all this available data, large neural network models with many degrees of freedom can now show their full potential by learning from all the texts and images posted every day on the Internet:
But we’re still far from Artificial General Intelligence (AGI)!

An AGI is a hypothetical computer system with human-like cognitive abilities capable of understanding, learning, and performing a wide range of tasks across diverse domains. Specifically, an AGI would not only perform specific tasks but also understand and learn from its environment, make decisions autonomously, and generalize its knowledge to completely new situations.
Instead, what is used in practice today is Artificial Narrow Intelligence (ANI): models explicitly programmed to solve a specific task(s), e.g., translate texts from one language to another. But they can’t generalize (on their own) to handle novel tasks, i.e., a machine translation model will not tomorrow decide that it now also wants to recognize faces in images. Of course, one can combine several individual ANIs into one big program trained to solve multiple different tasks, but this collection of ANIs is still not able to learn (on its own) any new skills beyond these capabilities.
Many AI researchers believe that at least with the currently used approaches to AI (e.g., large language models (LLMs) like ChatGPT from OpenAI), we might never produce a true human-like AGI. Specifically, these AI systems still lack a general understanding of causality and physical laws like object permanence — something that even many pets understand.
If you’re interested to learn more about the faults of current AI systems, the blog articles by Gary Marcus are highly recommended!