[Fehler #2] Modell generalisiert nicht
Wir wollen ein Modell, das den ‘Input → Output’-Zusammenhang in den Daten erfasst und interpolieren kann, d.h. wir müssen prüfen:
Generiert das Modell zuverlässige Vorhersagen für neue Datenpunkte aus derselben Verteilung wie die der Trainingsdaten?
Wenn ja, garantiert dies zwar noch nicht, dass das Modell tatsächlich den echten kausalen Zusammenhang zwischen Inputs und Outputs gelernt hat und über den Trainingsbereich hinaus extrapolieren kann (dazu kommen wir im nächsten Abschnitt). Zumindest generiert das Modell aber zuverlässige Vorhersagen für neue Datenpunkte, die den Trainingsdaten ähnlich sind. Ist dies nicht gegeben, ist das Modell nicht nur falsch, sondern auch nutzlos.
Aber warum macht ein Modell überhaupt Fehler? Eine schlechte Performance auf dem Testset kann zwei Gründe haben: Overfitting oder Underfitting.
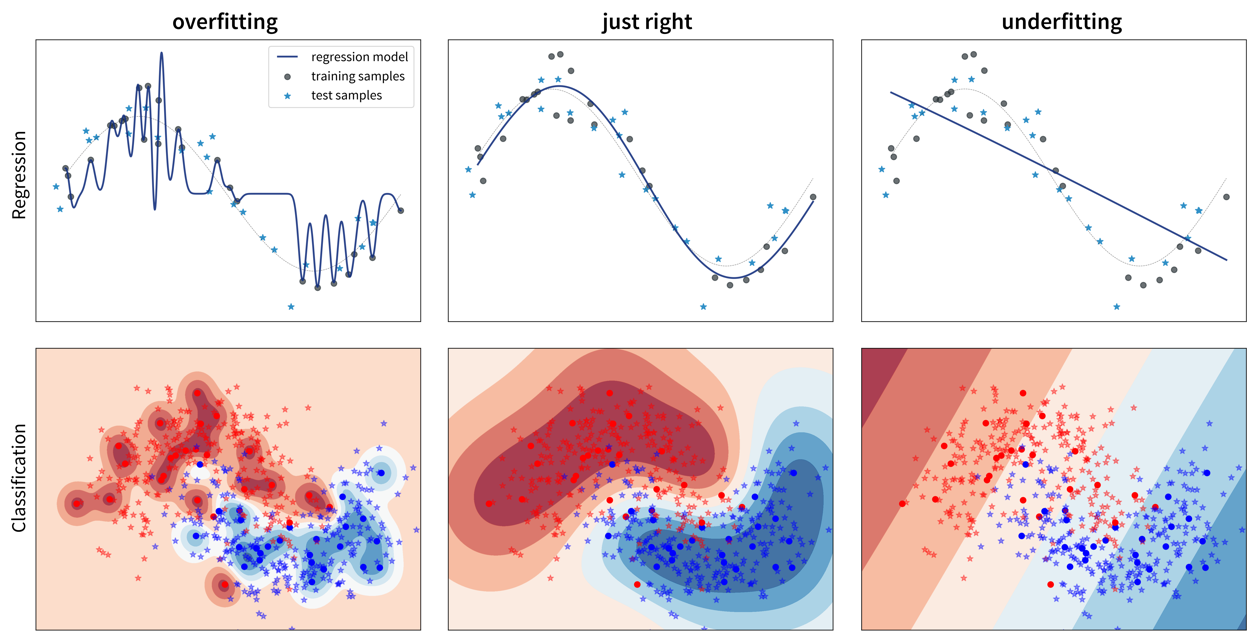
Diese beiden Fälle erfordern sehr unterschiedliche Ansätze, um die Modellperformance zu verbessern.
Da die meisten Datensätze sehr viele Inputvariablen haben, kann man das Modell in der Regel nicht einfach wie oben aufmalen, um zu sehen, ob es over- oder underfittet. Stattdessen muss man sich den mit einer aussagekräftigen Evaluierungsmetrik berechneten Fehler sowohl auf dem Trainings- als auch dem Testset anschauen um zu bestimmen, ob man es mit Overfitting oder Underfitting zu tun hat:
Overfitting: super Trainingsperformance, inakzeptabel auf den Testdaten
Underfitting: schlechte Trainings- UND Testperformance
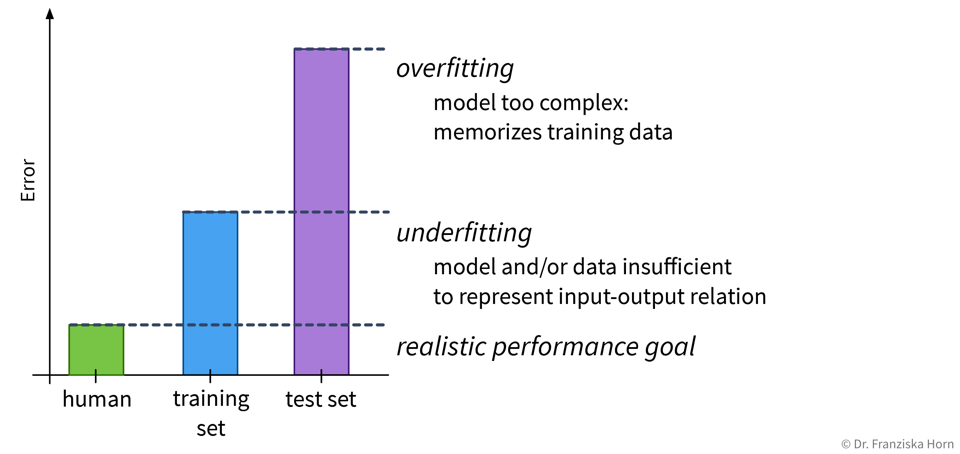
Je nachdem, ob ein Modell over- oder underfittet, gibt es verschiedene Möglichkeiten die Performance zu verbessern. Eine perfekte Modellperformance ist jedoch unrealistisch, da manche Aufgaben einfach schwierig sind, zum Beispiel weil die Daten sehr verrauscht sind.
| Schaue dir immer die Daten an! Gibt es ein Muster unter den falschen Vorhersagen, z.B. eine Diskrepanz zwischen der Performance für verschiedene Klassen? |