Garbage in, Garbage out!
Vergiss nie: Daten sind unser Rohstoff, um mit ML etwas Wertvolles zu schaffen. Ist die Qualität oder Quantität der Daten nicht ausreichend, haben wir ein “Garbage in, Garbage out”-Szenario und egal welche Art von ausgefallenem ML-Algorithmus wir verwenden, wir werden kein zufriedenstellendes Ergebnis erreichen. Im Gegenteil, je aufwändiger die Algorithmen (z.B. Deep Learning), desto mehr Daten werden benötigt.
Nachfolgend findest du eine Zusammenfassung einiger allgemeiner Risiken im Zusammenhang mit Daten, die die Anwendung von ML erschweren oder sogar unmöglich machen:
| Beobachte wenn möglich wie die Daten erfasst werden, im Sinne von: Stehe tatsächlich physisch da und beobachte, wie jemand die Werte in ein Programm eingibt oder wie die Maschine arbeitet, wenn die Sensoren etwas messen. Sicherlich werden dir einige Dinge auffallen, die man direkt bei der Datenerhebung optimieren könnte. Dies erspart in Zukunft viel Preprocessing Arbeit. |
- Best Practice: Datenkatalog
-
Um Datensätze leichter zugänglich zu machen, sollten diese dokumentiert werden. Für strukturierte Datensätze sollte es für jede Variable Zusatzinformationen geben wie:
-
Name der Variable
-
Beschreibung
-
Einheit
-
Datentyp (z.B. numerische oder kategorische Werte)
-
Datum der ersten Messung (z.B. falls ein Sensor erst später eingebaut wurde)
-
Normaler/erwarteter Wertebereich (→ “Wenn die Variable unter diesem Schwellwert liegt, dann ist die Maschine ausgeschaltet und die Datenpunkte können ignoriert werden”)
-
Wie werden fehlende Werte aufgezeichnet, d.h. werden sie tatsächlich als fehlende Werte aufgezeichnet oder stattdessen durch einen unrealistischen Wert ersetzt, was passieren kann, da einige Sensoren kein Signal für “Not a Number” (NaN) senden können oder die Datenbank es nicht zulässt, dass das Feld leer bleibt.
-
Anmerkungen zu sonstigen Vorfällen oder Ereignissen, z.B. eine Fehlfunktion des Sensors während eines bestimmten Zeitraums oder ein anderer Fehler, der zu falschen Daten geführt hat. Diese sind sonst oft schwer zu erkennen, z.B. wenn jemand stattdessen manuell Werte eingibt oder kopiert hat, die auf den ersten Blick normal aussehen.
-
Weitere Empfehlungen, was bei der Dokumentation von Datensätzen speziell für Machine Learning Anwendungen wichtig ist, findest du im Data Cards Playbook.
| Neben der Dokumentation von Datensätzen als Ganzes ist es auch sehr hilfreich, Metadaten für einzelne Proben zu speichern. Bei Bilddaten können dies beispielsweise der Zeitstempel der Bildaufnahme, die Geolokalisierung (oder wenn die Kamera in einer Fertigungsmaschine verbaut ist, dann die ID dieser Maschine), Informationen zu den Kameraeinstellungen etc. sein. Dies kann bei der Analyse von Modellvorhersagefehlern sehr hilfreich sein, da sich beispielsweise herausstellen kann, dass Bilder, die mit einer bestimmten Kameraeinstellung aufgenommen wurden, besonders schwer zu klassifizieren sind, was uns wiederum Hinweise liefert, wie wir den Datenerfassungsprozesses verbessern könnten. |
- Daten als Asset
-
Mit den richtigen Prozessen (z.B. Etablierung von Rollen wie “Data Owner” und “Data Controller”, die für die Datenqualität verantwortlich sind, und Aufbau einer konsistenten Dateninfrastruktur, inkl. eines Monitoring-Prozesses zur Validierung neuer Daten) ist es für eine Organisation möglich, von “Garbage in, Garbage out” zu “Daten sind das neue Öl” zu kommen:
- Mit (Big) Data kommt große Verantwortung!
-
Einige Daten erscheinen auf den ersten Blick manchmal nicht sehr wertvoll, können aber für andere (d.h. mit einem anderen Anwendungsfall) von großem Nutzen sein!
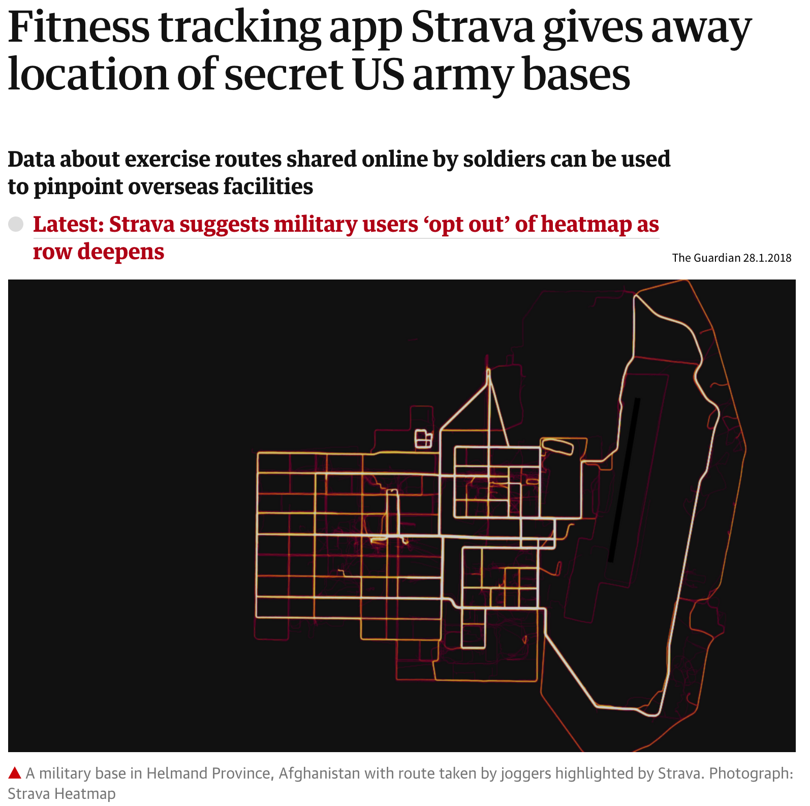 Ein Fitness-Tracker-Startup hielt es für eine coole Idee, beliebte Joggingrouten basierend auf den von ihren Nutzern generierten Daten zu veröffentlichen. Da aber auch viele US-Soldaten den Tracker benutzten und häufig um ihre Militärstützpunkte joggten, hat dieses Startup dadurch versehentlich einen geheimen US-Armeestützpunkt in Afghanistan geoutet, der auf ihrer interaktiven Karte als heller Punkt in einem Gebiet auftauchte, wo sonst nur wenige andere Nutzer joggten. Auch wenn deine Daten erstmal harmlos erscheinen, denk bitte darüber nach, was bei einer Veröffentlichung (auch in aggregierter, anonymisierter Form) schief gehen könnte!
Ein Fitness-Tracker-Startup hielt es für eine coole Idee, beliebte Joggingrouten basierend auf den von ihren Nutzern generierten Daten zu veröffentlichen. Da aber auch viele US-Soldaten den Tracker benutzten und häufig um ihre Militärstützpunkte joggten, hat dieses Startup dadurch versehentlich einen geheimen US-Armeestützpunkt in Afghanistan geoutet, der auf ihrer interaktiven Karte als heller Punkt in einem Gebiet auftauchte, wo sonst nur wenige andere Nutzer joggten. Auch wenn deine Daten erstmal harmlos erscheinen, denk bitte darüber nach, was bei einer Veröffentlichung (auch in aggregierter, anonymisierter Form) schief gehen könnte!