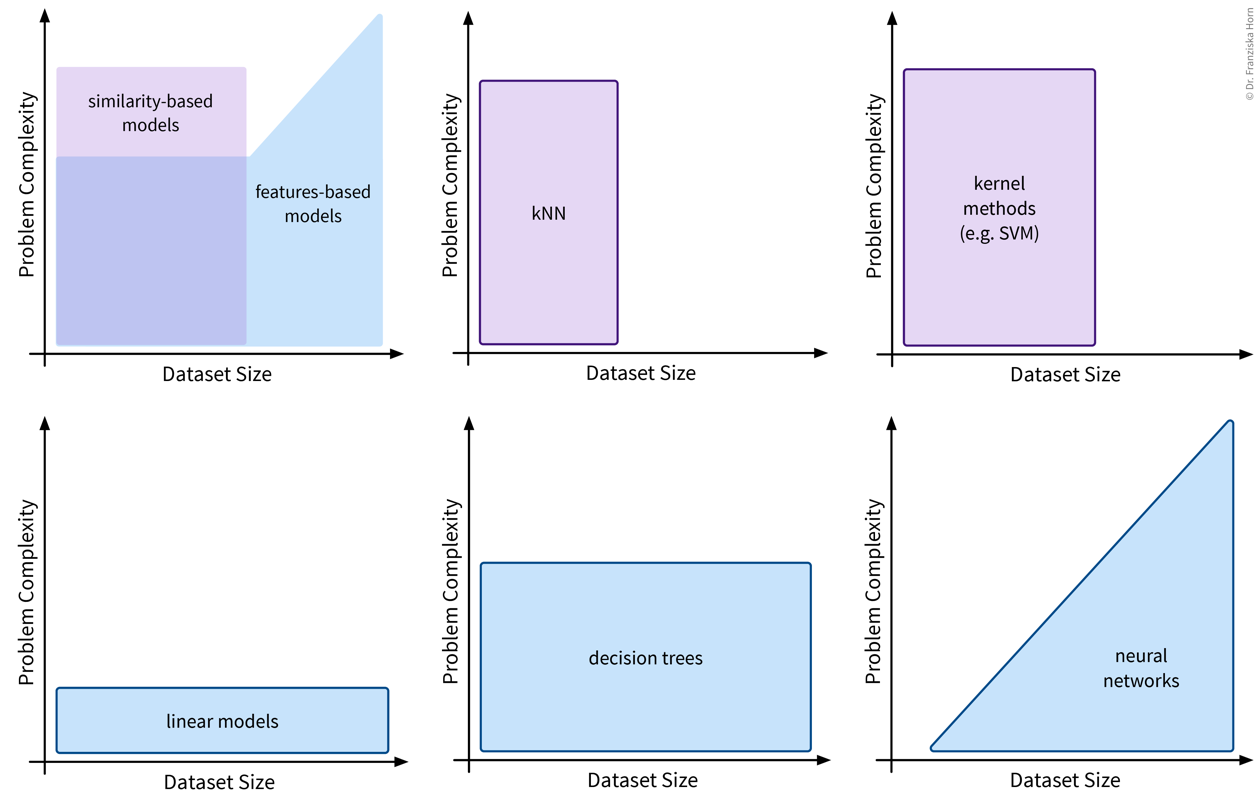
Different types of models
The most important task of a data scientist is to select an appropriate model (and its hyperparameters) for solving a problem.
Problem type: regression vs. classification
The type of the target variable that we want to predict determines whether we are dealing with a regression or classification problem.
- Regression
-
Prediction of continuous value(s) (e.g., price, number of users, etc.).
- Classification
-
Prediction of discrete values:
-
binary (e.g., product will be faulty: yes/no)
-
multi-class (e.g., picture displays cat/dog/house/car/…)
-
multi-label (e.g., picture may display multiple objects)
→ Many classification models actually predict probabilities for the different classes, i.e., a score between 0 and 1 for each class. The final class label is then chosen by applying a threshold on this score (typically 0.5 for binary classification problems) or by taking the outcome with the highest score (in multi-class problems).
-
⇒ Whether we are dealing with a regression or classification problem is important to know and has implications for our overall workflow, e.g., how we define & measure success. However, the actual models that we use to solve these problems are very similar, e.g., almost all sklearn models exist in either a Regressor or Classifier variant to generate the appropriate output for the respective problem type.
Problem complexity: linear or nonlinear
In accordance with the product warranty example described above, we now illustrate what it means for a problem to be linear or nonlinear on a small toy dataset:
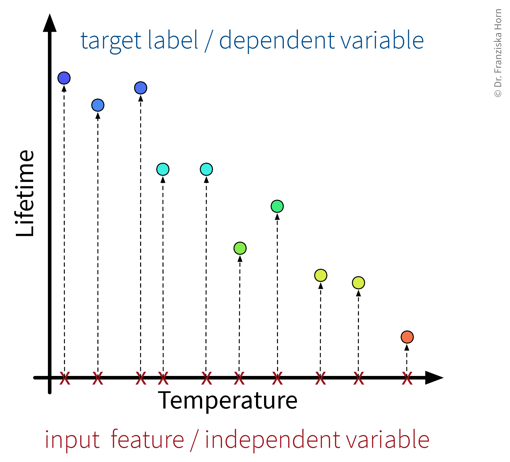
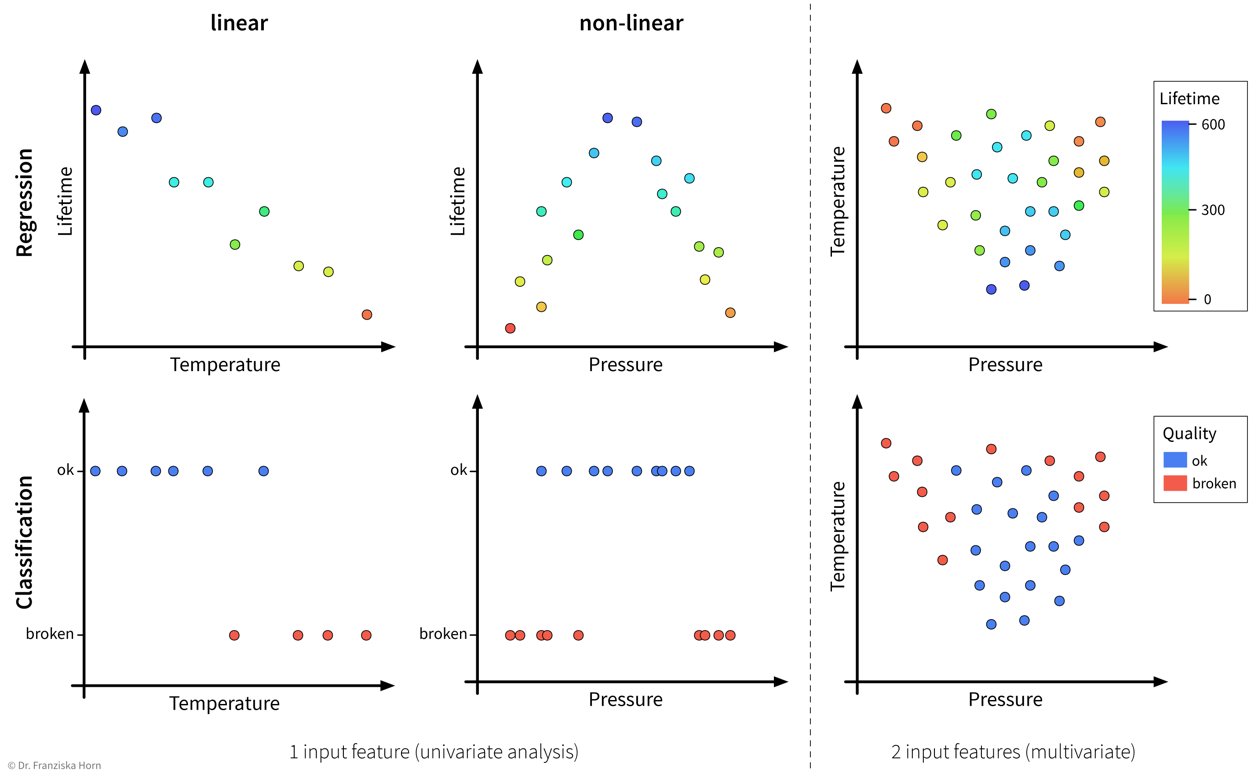
As illustrated in the above examples, whether a problem can be solved by a simple linear model (i.e., a single straight line or hyperplane) or requires a more complex nonlinear model to adequately describe the relationship between the input features and target variable entirely depends on the given data.
This also means that sometimes we can just install an additional sensor to measure some feature that is linearly related to the target variable or do some feature engineering to then be able to get satisfactory results with a linear model, i.e., sometimes, with the right preprocessing, a nonlinear problem can also be transformed into a linear one.
Algorithmic approaches: features-based vs. similarity-based models
Finally, lets look at how the different models work and arrive at their predictions. This is what really distinguishes the various algorithms, whereas we have already established that there always exists a regression and a classification variant of each model and some models are inherently expressive enough that they can be used to describe nonlinear relationships in the data, while others will only yield satisfactory results if there exists a linear relationship between the available input features and the target variable.
Features-based models learn some parameters or rules that are applied directly to a new data point’s input feature vector \(\mathbf{x} \in \mathbb{R}^d\). Similarity-based models, on the other hand, first compute a vector \(\mathbf{s} \in \mathbb{R}^n\) with the similarities of the new sample to the training data points and the model then operates on this vector instead of the original input features.
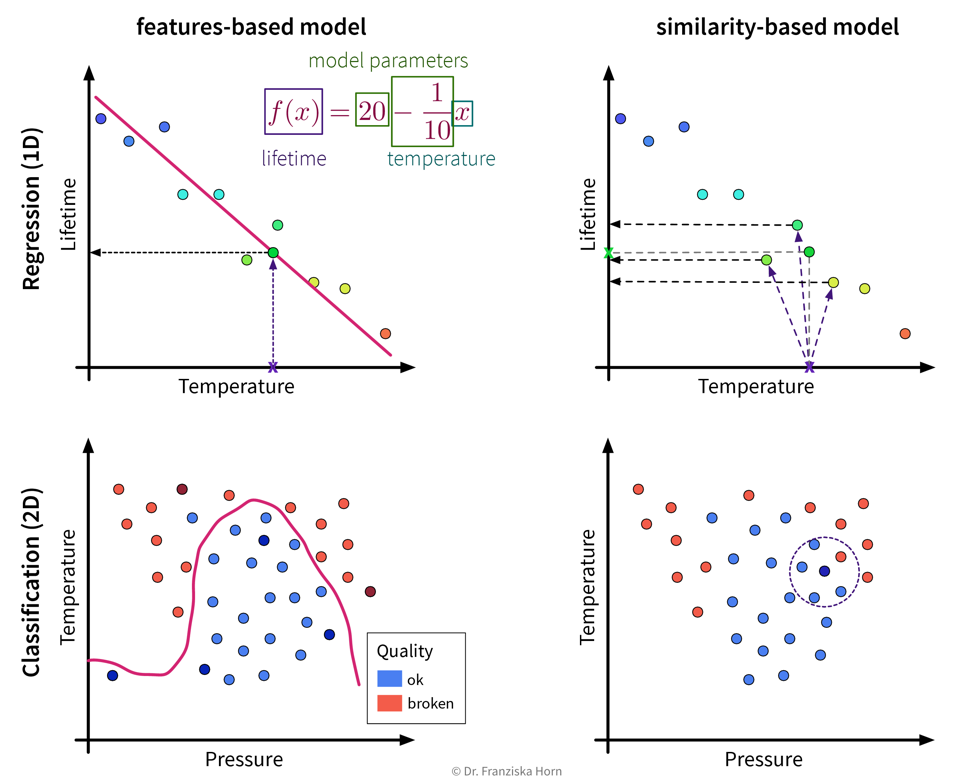
| This distinction between algorithmic approaches is not only interesting from a theoretical point of view, but even more so from a practitioner’s perspective: When using a similarity-based algorithm, we have to be deliberate about which features to include when computing the similarities, make sure that these features are appropriately scaled, and in general think about which similarity measure is appropriate for this data. For example, we could capture domain knowledge by using a custom similarity function specifically tailored to the problem. When using a features-based model, on the other hand, the model itself can learn which features are most predictive by assigning individual weights to each input feature and therefore possibly ignore irrelevant features or account for variations in heterogeneous data. But of course, subject matter expertise is still beneficial here, as it can, for example, guide us when engineering additional, more informative input features. |
Okay, now, when should we use which approach?
- Features-based models
-
-
Number of features should be less than the number of samples!
-
Good for heterogeneous data due to individual feature weights (although scaling is usually still a good idea).
-
Easier to interpret (since they describe a direct relationship between input features & target).
-
- Similarity-based models
-
-
Nonlinear models for small datasets.
-
Need appropriate similarity function → domain knowledge! (especially for heterogeneous data)
-