[Pitfall #2] Model does not generalize
We want a model that captures the ‘input → output’ relationship in the data and is capable of interpolating, i.e., we need to check:
Does the model generate reliable predictions for new data points from the same distribution as the training set?
While this does not ensure that the model has actually learned any true causal relationship between inputs and outputs and can extrapolate beyond the training domain (we’ll discuss this in the next section), at least we can be reasonably sure that the model will generate reliable predictions for data points similar to those used for training the model. If this isn’t given, the model is not only wrong, it’s also useless.
So, why does a model make mistakes on new data points? A poor performance on the test set can have two reasons: overfitting or underfitting.
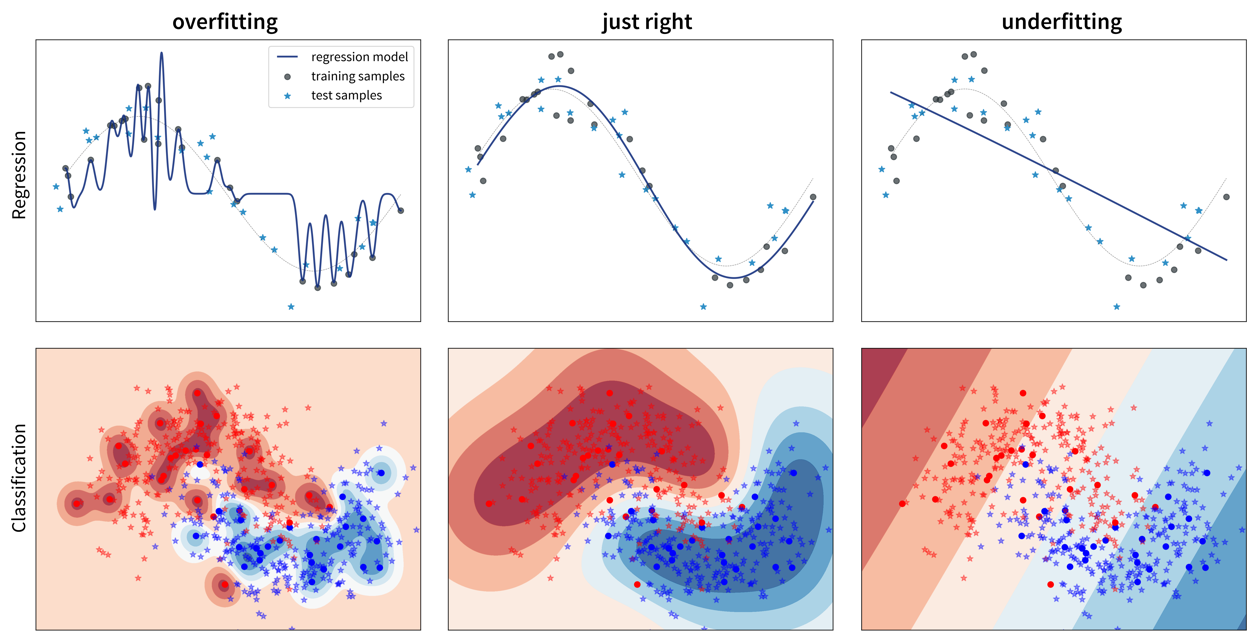
These two scenarios require vastly different approaches to improve the model’s performance.
Since most datasets have lots of input variables, we can’t just plot the model like we did above to see if it is over- or underfitting. Instead we need to compute the model’s prediction error with a meaningful evaluation metric for both the training and the test set and compare the two to see if we’re dealing with over- or underfitting:
Overfitting: great training performance, bad on test set
Underfitting: poor training AND test performance
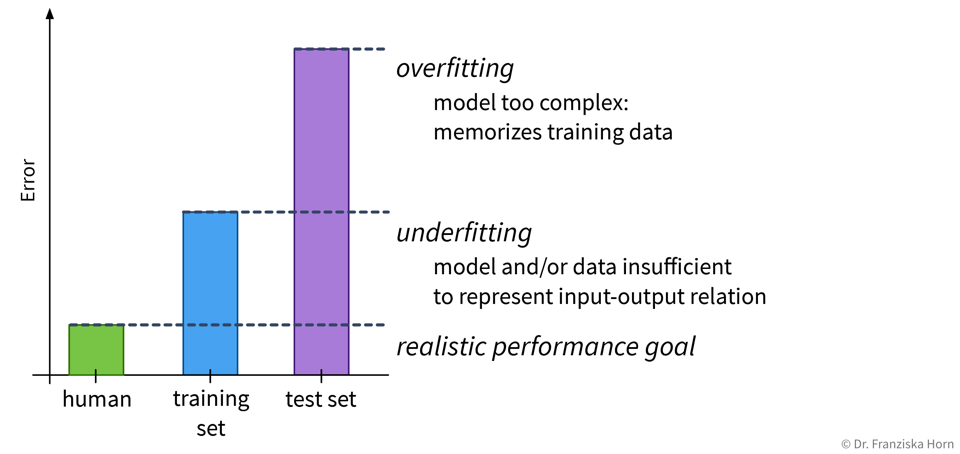
Depending on whether a model over- or underfits, different measures that can be taken to improve its performance. However, it is unrealistic to expect a model to have a perfect performance, as some tasks are just hard, for example, because the data is very noisy.
| Always look at the data! Is there a pattern among wrong predictions, e.g., is there a discrepancy between the performance for different classes? |