[Pitfall #4] Model discriminates
As we ponder the true causal relations between variables in the data, we also need to consider whether there are some causal relationships encoded in the historical data that we don’t want a model to pick up on. For example, discrimination based on gender or ethnicity can leak into the training data and we need to take extra measures to make sure that these patterns, although they might have been true causal relationships in the past, are not present in our model now.
- Biased data leads to (strongly) biased models
-
Below are some examples where people with the best of intentions have set up an ML model that has learned problematic things from real world data.

de Vries, Terrance, et al. “Does object recognition work for everyone?” IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2019.
The above problems all arose because the data was not sampled uniformly:
-
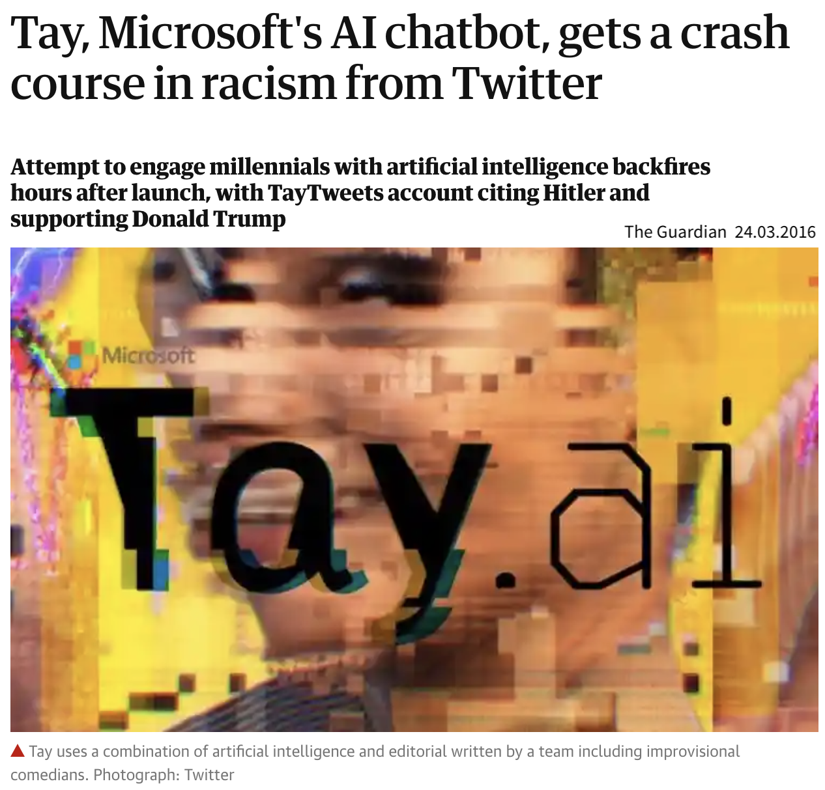
Tay has seen many more racist and hateful comments and tweets than ‘normal’ ones.
-
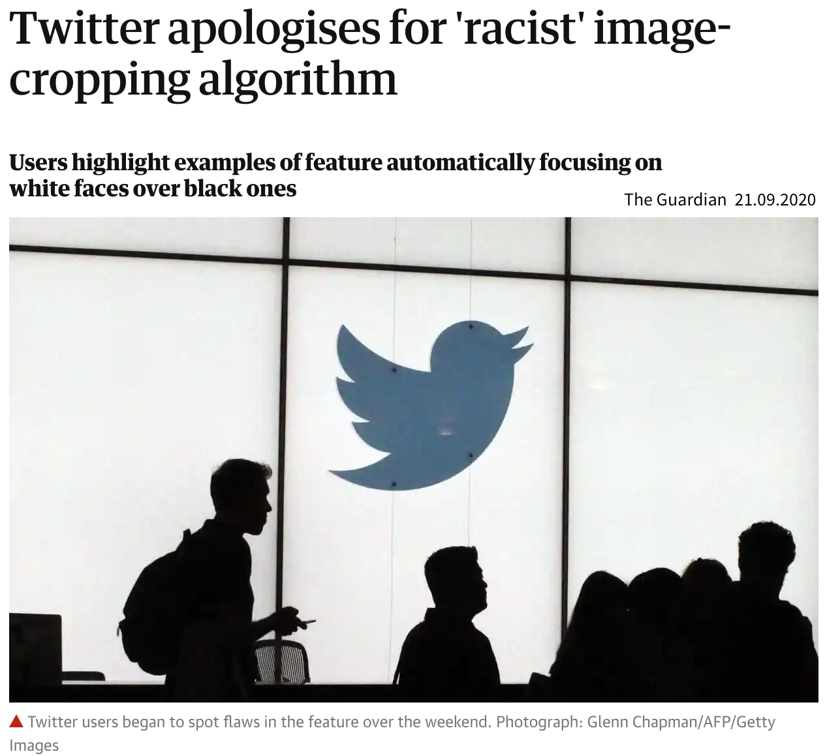
The image dataset Twitter trained its model on included more pictures of white people compared to people of color.
-
Similarly, given a random collection of photos from the internet, these images will have mostly been uploaded by people from developed countries, i.e., pictures displaying the status quo in developing nations are underrepresented.
Even more problematic than a mere underrepresentation of certain subgroups (i.e., a skewed input distribution) is a pattern of systematic discrimination against them in historical data (i.e., a discriminatory shift in the assigned labels).
To summarize: A biased model can negatively affect users in two ways:
-
Disproportionate product failures, due to skewed sampling. For example, speech recognition models are often less accurate for women, because they were trained on more data collected from men (e.g., transcribed political speeches).
-
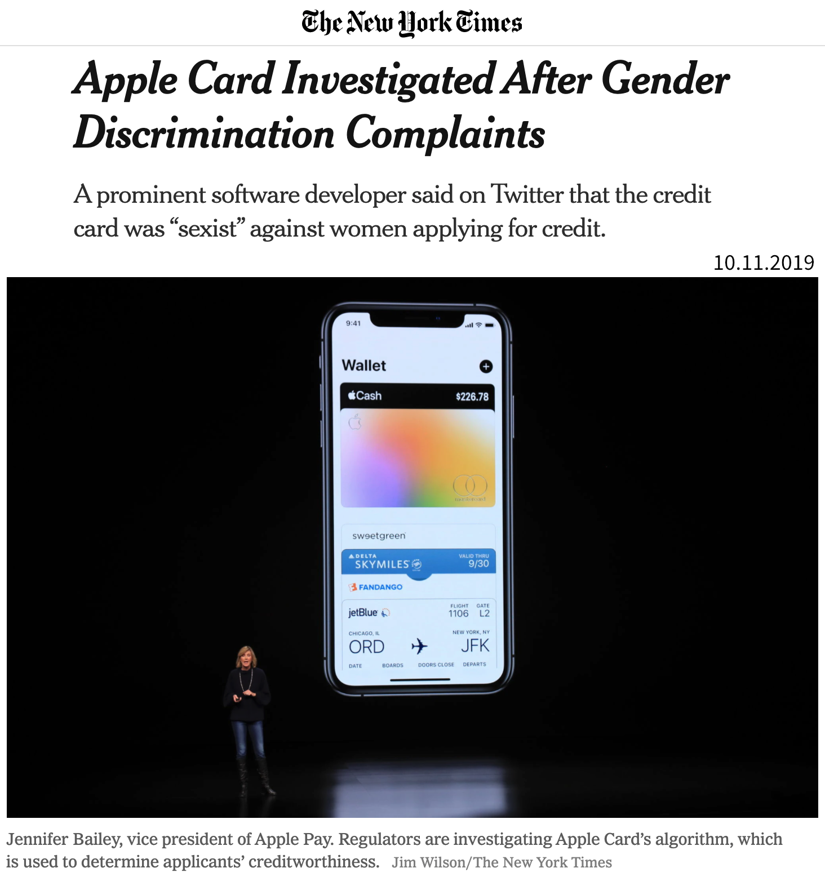
Harm by disadvantage / opportunity denial, due to stereotypes encoded in historical data. For example, women are assigned higher credit interest rates than men or people born in foreign countries are deemed less qualified for a job when their resumes are assessed by an automated screening tool.
| Retraining models on data shaped by predictions from a biased predecessor model can intensify existing biases. For instance, if a resume screening tool recognizes a common trait (e.g., “attended Stanford University”) among current employees, it may consistently recommend resumes with this trait. Consequently, more individuals with this characteristic will be invited for interviews and hired, further reinforcing the dominance of the trait in subsequent models trained on these employee profiles. |
Towards fair models
The first step to mitigating these problems is to become aware of them. Therefore, it is important to always assess the model’s performance for each (known) subgroup individually to verify that the prediction errors of the model are random and the model is not systematically worse for some subgroups.
We should also be careful when including variables in the model that encode attributes such as gender or ethnicity. For example, the performance of a model that diagnoses heart attacks will most likely be improved by including ‘gender’ as a feature, since men and women present different symptoms when they have a heart attack. On the other hand, a model that assigns someone a credit score should probably not rely on the gender of the person for this decision, since, even though this might have been the case in the historical data because the humans that generated the data relied on their own stereotypes, women should not get a lower score just because they are female.
However, a person’s gender or ethnicity, for example, is often correlated with other variables such as income or neighborhood, so even inconspicuous features can still leak problematic information to the model and require some extra steps to ensure the model does not discriminate.
For other examples of what not to do, check out the AI Incidence Database and

Book recommendation:
Weapons of Math Destruction by Cathy O’Neil (2016)