Clustering
The last category of unsupervised learning algorithms is clustering:
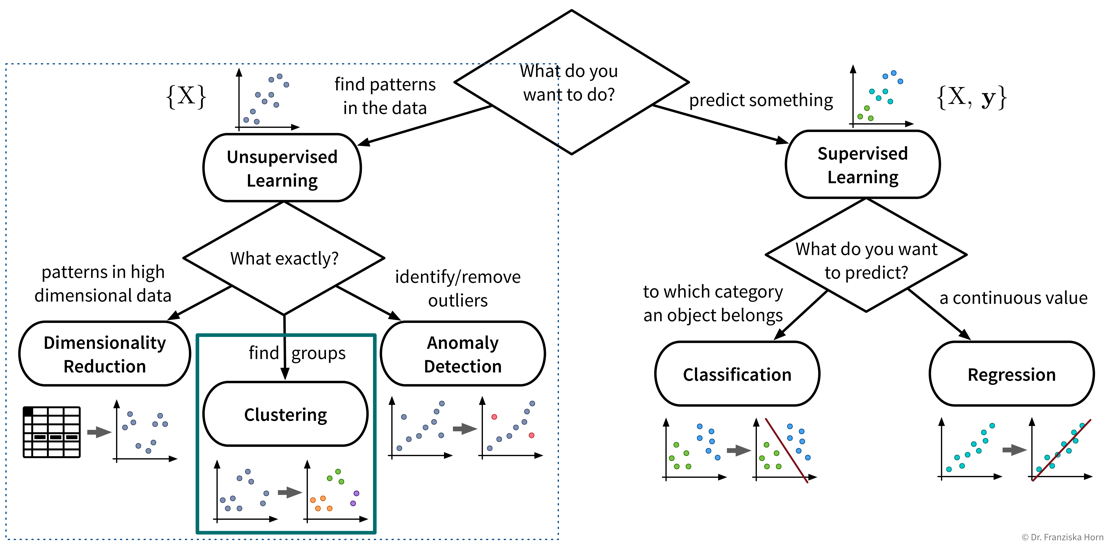
- Useful for
-
Identifying naturally occurring groups in the data (e.g., for customer segmentation).
There exist quite a lot of different clustering algorithms and we’ll only present two with different ideas here.
When you look at the linked sklearn examples, please note that even though other clustering algorithms might seem to perform very well on fancy toy datasets, data in reality is seldom arranged in two concentric circles, and on real-world datasets the k-means clustering algorithm is often a robust choice.
k-means clustering
- Main idea
-
-
Randomly place k cluster centers (where k is a hyperparameter set by the user);
-
Assign each data point to its closest cluster center;
-
Update cluster centers as the mean of the assigned data points;
-
Repeat steps 2-3 until convergence.
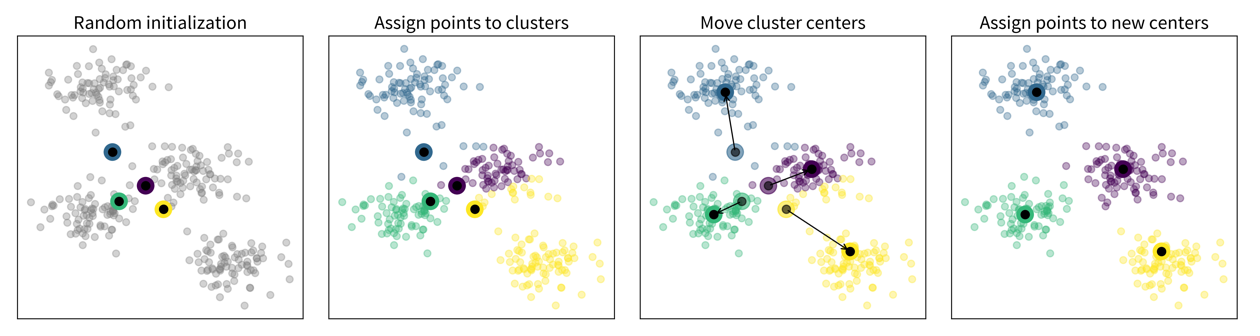 Please note that even though in these pictures the data is depicted in 2D, of course all these methods also work in high dimensional spaces!
Please note that even though in these pictures the data is depicted in 2D, of course all these methods also work in high dimensional spaces! -
from sklearn.cluster import KMeansImportant Parameters:
-
→
n_clusters: How many clusters (k) the algorithm should find.
- Pros
-
-
Fast.
-
Usually good results on real world datasets.
-
- Careful
-
-
Depends on random initialization → solution is local optimum, but usually not problematic in practice due to multiple restarts.
-
Assumes spherical clusters.
-
Need to guess the number of clusters. But this can be done with a heuristic and sometimes we also need to find a fixed number of clusters, e.g., if we only have the budged for three different marketing initiatives, we want to assign our customers to exactly three groups.
-
DBSCAN
- Main idea
-
Find ‘core samples’ in dense areas of the data and then expand the clusters by iteratively including points with a distance <
eps.
from sklearn.cluster import DBSCANImportant Parameters:
-
→
eps: Maximum neighborhood distance of two samples. -
→
metric: How to compute the distance in the input feature space.
- Pros
-
-
Allows for noise ⇒ can also be used to detect outliers.
-
No need to guess the number of clusters.
-
- Careful
-
-
Very dependent on distance measure: may be tricky to get good results for heterogeneous data even after normalization (but: try on text data).
-
→ Also check out the hdbscan library!