Garbage in, garbage out!
Remember: data is our raw material when producing something valuable with ML. If the quality or quantity of the data is insufficient, we are facing a “garbage in, garbage out” scenario and no matter what kind of fancy ML algorithm we try, we wont get a satisfactory result. In fact, the fancier the algorithm (e.g., deep learning), the more data we need.
Below you find a summary of some common risks associated with data that can make it complicated or even impossible to apply ML:
| If you can, observe how the data is collected. As in: actually physically stand there and watch how someone enters the values in some program or how the machine operates as the sensors measure something. You will probably notice some things that can be optimized in the data collection process directly, which will save you lots of preprocessing work in the future. |
- Best Practice: Data Catalog
-
To make datasets more accessible, especially in larger organizations, they should be documented. For example, in structured datasets, there should be information available on each variable like:
-
Name of the variable
-
Description
-
Units
-
Data type (e.g., numerical or categorical values)
-
Date of first measurement (e.g., in case a sensor was installed later than the others)
-
Normal/expected range of values (→ “If this variable is below this threshold, then the machine is off and the data points can be ignored.”)
-
How missing values are recorded, i.e., whether they are recorded as missing values or substituted with some unrealistic value instead, which can happen since some sensors are not able to send a signal for “Not a Number” (NaN) directly or the database does not allow for the field to be empty.
-
Notes on anything else you should be aware of, e.g., a sensor malfunctioning during a certain period of time or some other glitch that resulted in incorrect data. This can otherwise be difficult to spot, for example, if someone instead manually entered or copy & pasted values from somewhere, which look normal at first glance.
-
You can find further recommendations on what is particularly important when documenting datasets for machine learning applications in the Data Cards Playbook.
| In addition to documenting datasets as a whole, it is also helpful to store metadata for individual samples. For example, for image data, this could include the time stamp of when the image was taken, the geolocation (or if the camera is built into a manufacturing machine then the ID of this machine), information about the camera settings, etc.. This can greatly help when analyzing model prediction errors, as it might turn out that, for example, images taken with a particular camera setting are especially difficult to classify, which in turn gives us some hints on how to improve the data collection process. |
- Data as an Asset
-
With the right processes (e.g., roles such as “Data Owner” and “Data Controller” that are accountable for the data quality, and a consistent data infrastructure that includes a monitoring pipeline to validate new data), it is possible for an organization to get from “garbage in, garbage out” to “data is the new oil”:
- With (big) data comes great responsibility!
-
Some data might not seem very valuable to you, but can be a huge asset for others, i.e., with a different use case!
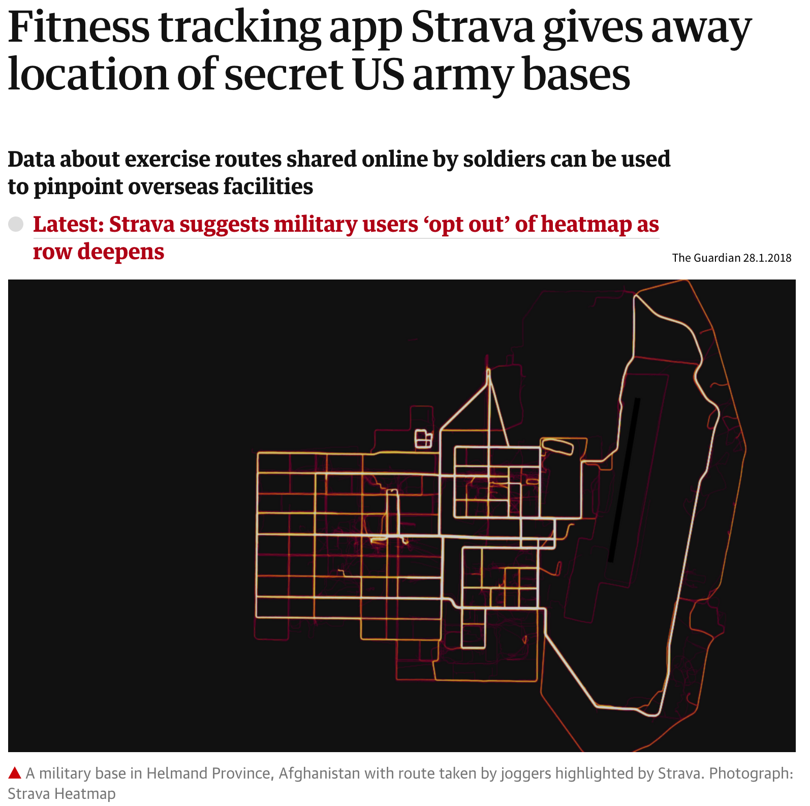 A fitness tracker startup thought it would be a cool idea to publish popular jogging routes based on the data they’ve collected from their users. However, since many US soldiers also happened to use the tracker and frequently jogged around their army bases, this startup thereby accidentally outed a secret army base in Afghanistan, which appeared as a bright spot on their interactive map in an area where they otherwise had only few users. So even if your data looks harmless at first glance, please do think about what could go wrong in case you publish it (even in an aggregated, anonymized form)!
A fitness tracker startup thought it would be a cool idea to publish popular jogging routes based on the data they’ve collected from their users. However, since many US soldiers also happened to use the tracker and frequently jogged around their army bases, this startup thereby accidentally outed a secret army base in Afghanistan, which appeared as a bright spot on their interactive map in an area where they otherwise had only few users. So even if your data looks harmless at first glance, please do think about what could go wrong in case you publish it (even in an aggregated, anonymized form)!