Was ist ML?
Was genau ist nun dieses maschinelle Lernen, das bereits unser aller Leben verändert?
ML ist zunächst ein Forschungsgebiet im Bereich der theoretischen Informatik, an der Schnittstelle von Mathematik und Informatik:
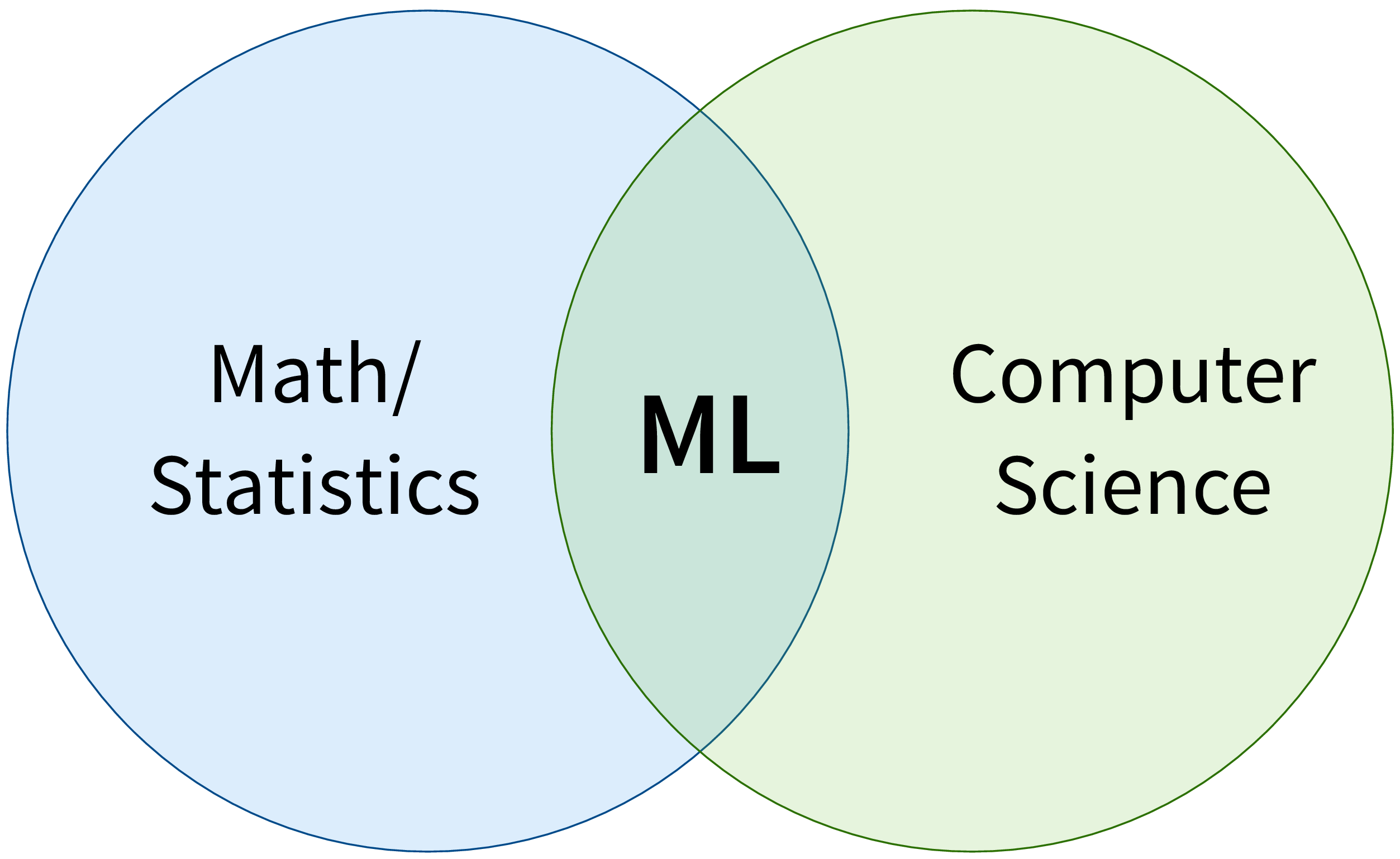
Genauer gesagt ist maschinelles Lernen ein Überbegriff für Algorithmen, die Muster erkennen und Regeln aus Daten lernen.
| Vereinfacht kann man sich einen Algorithmus als Strategie oder Rezept zur Lösung eines speziellen Problems vorstellen. Es gibt zum Beispiel effektive Algorithmen, um den kürzesten Weg zwischen zwei Städten zu finden (z.B. genutzt in den Navigationssystemen von Google Maps) oder um Planungsprobleme zu lösen wie z.B.: “Welche Aufgabe sollte zuerst erledigt werden und welche Aufgabe danach um alle Aufgaben vor ihrer Deadline zu schaffen unter Berücksichtigung eventueller Abhängigkeiten zwischen den Aufgaben.” Maschinelles Lernen befasst sich mit der Teilmenge von Algorithmen, die statistische Regelmäßigkeiten in einem Datensatz erkennen und nutzen, um bestimmte Ergebnisse zu erzielen. |
Analog zu den Werkzeugen, mit denen man etwas in einem traditionellen Produktionsprozess herstellt, kann man sich ML-Algorithmen als Werkzeuge vorstellen, um Wert aus Daten zu generieren:

Um ML erfolgreich anzuwenden, sollte man sich einige wichtige Fragen stellen:
-
Was könnte wertvoll sein? Dies kann beispielsweise ein neues Feature für ein existierendes Produkt sein, z.B. Face ID als neue Möglichkeit um ein Smartphone zu entsperren.
-
Welche Daten werden benötigt? Einen Holzstuhl kann man nicht aus Stoff und Metall oder ein paar im Wald gefundenen Zweigen herstellen. Genauso benötigt man je nachdem, was man mit ML erreichen möchte, auch die richtigen Daten in ausreichender Qualität & Quantität um die Algorithmen überhaupt anwenden zu können. In vielen Anwendungsfällen ist dieser Teil besonders schwierig, da man die benötigten Daten oft nicht einfach kaufen kann, wie Holz im Baumarkt, sondern diese selbst sammeln — also quasi einen eigenen Wald anpflanzen muss, was einige Zeit dauern kann.
-
Welcher ML-Algorithmus ist das richtige Werkzeug für diese Aufgabe? (Welche Kategorie von ML-Algorithmen generiert die Art von Output, die wir benötigen?)
-
Verfüge ich bzw. meine Mitarbeiter über die notwendigen Fähigkeiten und genügend Rechenleistung, um das Vorhaben erfolgreich umzusetzen?
Die unterschiedlichen Algorithmen bilden unseren ML Werkzeugkasten:
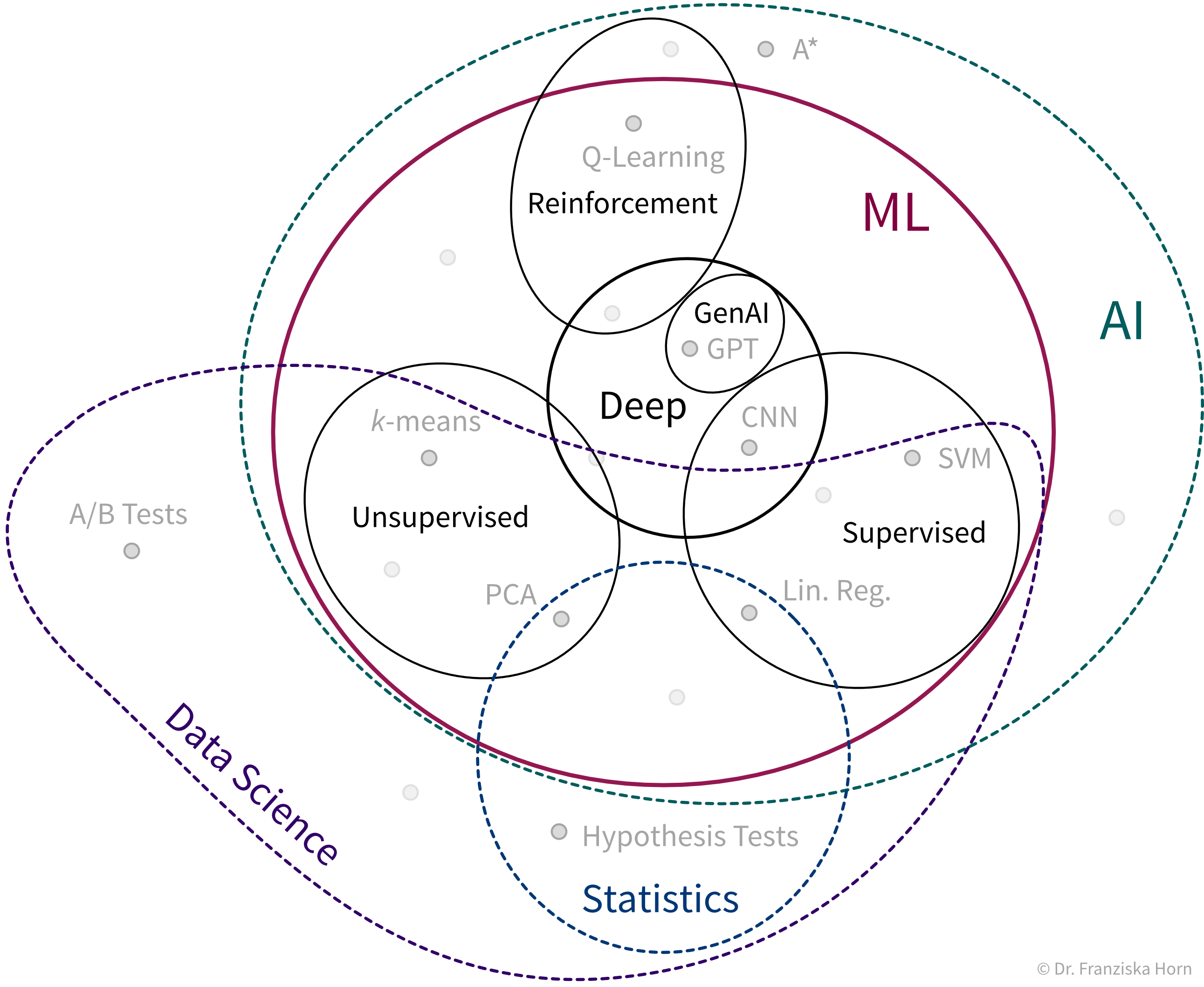
- ML Algorithmen lösen “Input → Output” Probleme
-
All diesen ML-Algorithmen aus unserem Werkzeugkasten ist gemein, dass sie “Input → Output” Probleme wie diese lösen:
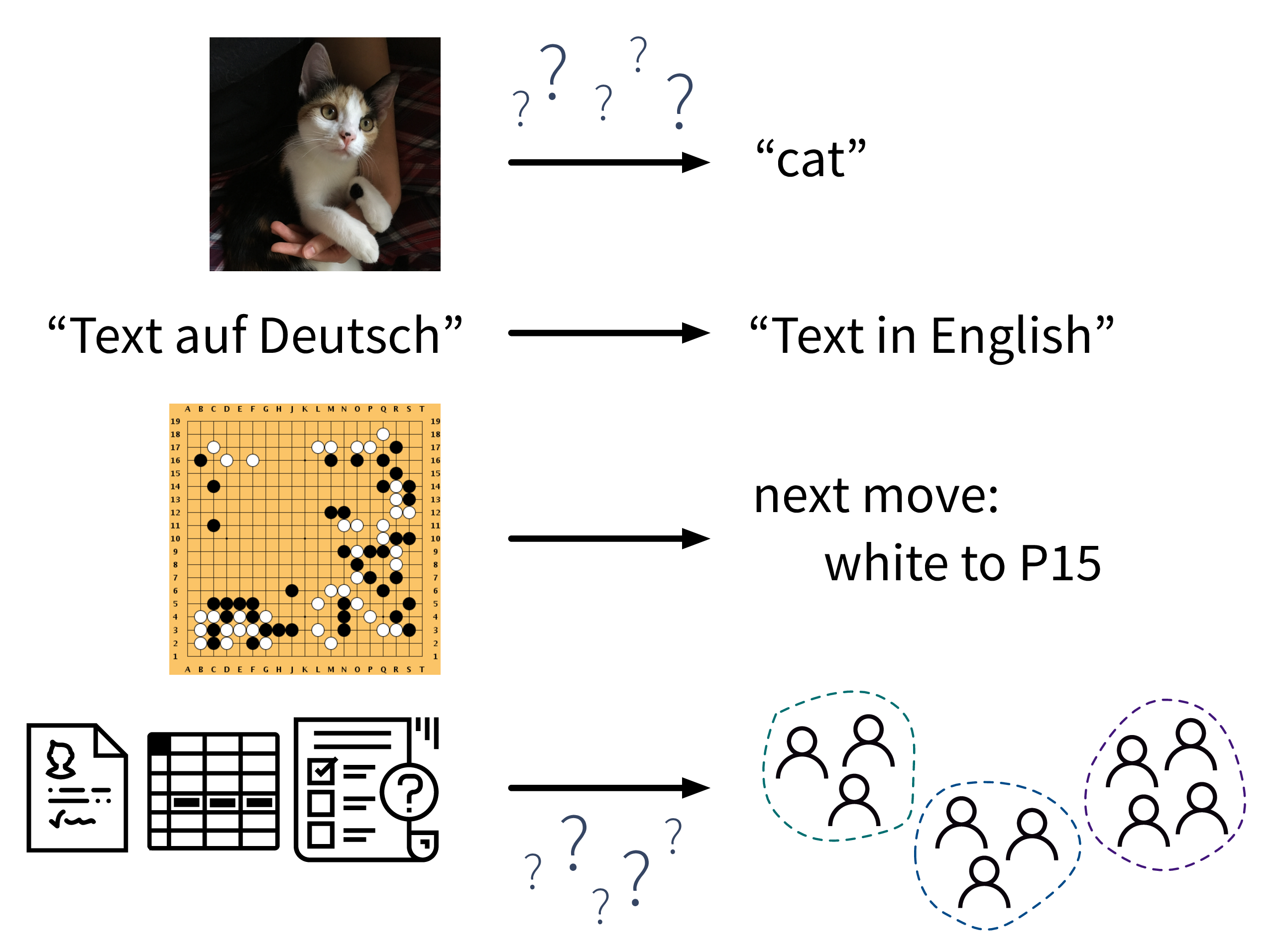
Während in den obigen Beispielen ein (entsprechend geschulter) Mensch zur jeweiligen Eingabe in der Regel leicht die richtige Ausgabe erzeugt (z.B. kann sogar ein kleines Kind die Katze im ersten Bild erkennen), fällt es Menschen oft schwer zu beschreiben, wie sie zur richtigen Antwort gekommen sind (woran erkennt man, dass dies eine Katze und kein kleiner Hund ist? an den spitzen Ohren? den Schnurrhaaren?). Im Gegensatz dazu lernen ML-Algorithmen solche Regeln aus den gegebenen Beispieldaten.
ML vs. herkömmliche Software
Während man herkömmliche Software-Lösungen dazu verwenden kann, um Aufgaben zu automatisieren, bei denen eine vordefinierte Abfolge von Aktionen nach einigen festgeschriebenen Regeln ausgeführt wird (z.B. “Eine Tür soll sich öffnen, wenn ein Objekt eine Lichtschranke durchquert und sich 20 Sekunden später wieder schließen”), kann man mit maschinellem Lernen “Input → Output”-Aufgaben automatisieren, für die es sonst schwierig wäre, solche Regeln aufzustellen.
Die Qualitätskontrolle in einer Keks-Fabrik ist ein Beispiel für eine solche “Input (Keks) → Output (ok/fehlerhaft)”-Aufgabe: Während z.B. zerbrochene Kekse automatisch aussortiert werden könnten, indem man überprüft, dass jeder Keks etwa 15g wiegt, ist es schwierig, Regeln zu formulieren, die alle möglichen Produktionsfehler zuverlässig abfangen. Also müsste entweder ein Mensch die Produktionslinie beobachten, um z.B. zusätzlich verbrannte Kekse zu erkennen, oder man könnte Bilder von den Keksen machen und sie als Input für ein Machine Learning Modell verwenden, um die fehlerhaften Kekse zu erkennen:

Um dieses Problem mit ML zu lösen, muss zunächst ein großer Datensatz mit Fotos vieler guter, aber auch allerlei fehlerhafter Kekse zusammengestellt werden, inklusive der entsprechenden Annotationen, also einem Label für jedes Bild, ob es einen guten oder fehlerhaften Keks zeigt (aber nicht unbedingt die Art des Fehlers). Aus diesen Beispielen kann dann ein ML-Algorithmus lernen, zwischen guten und fehlerhaften Keksen zu unterscheiden.
- Schritte zur Identifizierung eines potenziellen ML-Projekts
-
Erstelle ein Prozessdiagramm: Welche Schritte werden in einem Geschäftsprozess ausgeführt und welche Daten werden wo gesammelt (Material- & Informationsfluss). Zum Beispiel in einem Produktionsprozess, bei dem einige der produzierten Teile fehlerhaft sind:

-
Identifiziere Teile des Prozesses, die entweder mit ML automatisiert werden könnten (z.B. einfache, sich wiederholende Aufgaben, die sonst von Menschen erledigt werden) oder die auf andere Weise durch eine Analyse von Daten verbessert werden könnten (z.B. um die Ursachen eines Problems zu verstehen, die Planung mit Was-wäre-wenn-Simulationen zu verbessern, oder die Ressourcennutzung zu optimieren):
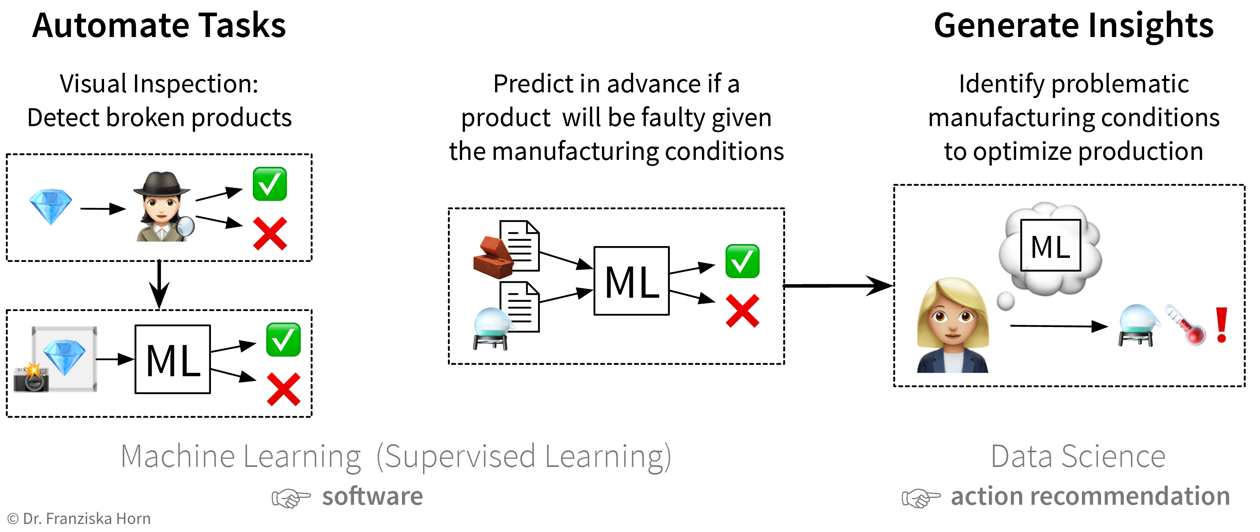 Die erste Idee besteht darin, die bisher von einem Menschen durchgeführte Qualitätsprüfung zu automatisieren: Da der Mensch die Defekte in den aufgenommenen Produktbildern leicht erkennen kann, sollte ein ML-Modell dies auch schaffen. Die nächste Idee besteht darin, anhand der Zusammensetzung der Rohstoffe und der gegebenen Prozessbedingungen vor der Herstellung vorherzusagen, ob ein Produkt fehlerhaft sein wird oder nicht: Der Erfolg ist hier unklar, da eine menschliche Expertin nicht von vorne herein abschätzen kann, ob alle relevanten Informationen dafür in diesen Daten enthalten sind. Aber dennoch wäre es einen Versuch wert, da man dadurch viele Ressourcen sparen könnte. Während das endgültige ML-Modell, welches das Input-Output-Problem löst, als Software im laufenden Betrieb eingesetzt werden kann, kann ein Data Scientist zusätzlich die Ergebnisse analysieren und das Modell interpretieren und somit Erkenntnisse gewinnen und Handlungsempfehlungen aussprechen.
Die erste Idee besteht darin, die bisher von einem Menschen durchgeführte Qualitätsprüfung zu automatisieren: Da der Mensch die Defekte in den aufgenommenen Produktbildern leicht erkennen kann, sollte ein ML-Modell dies auch schaffen. Die nächste Idee besteht darin, anhand der Zusammensetzung der Rohstoffe und der gegebenen Prozessbedingungen vor der Herstellung vorherzusagen, ob ein Produkt fehlerhaft sein wird oder nicht: Der Erfolg ist hier unklar, da eine menschliche Expertin nicht von vorne herein abschätzen kann, ob alle relevanten Informationen dafür in diesen Daten enthalten sind. Aber dennoch wäre es einen Versuch wert, da man dadurch viele Ressourcen sparen könnte. Während das endgültige ML-Modell, welches das Input-Output-Problem löst, als Software im laufenden Betrieb eingesetzt werden kann, kann ein Data Scientist zusätzlich die Ergebnisse analysieren und das Modell interpretieren und somit Erkenntnisse gewinnen und Handlungsempfehlungen aussprechen. -
Priorisieren: Welches Projekt hätte eine große Wirkung und gleichzeitig gute Erfolgsaussichten, hätte also einen hohen Return on Investment (ROI)? Als Beispiel: Die Verwendung von ML zur Automatisierung einer einfachen Aufgabe ist aus technischer Sicht eine vergleichsweise risikoarme Investition, kann jedoch dazu führen, dass einige Fließbandarbeiter ihre Jobs verlieren. Andererseits könnten durch die Ermittlung der Ursachen, warum in einem Produktionsprozess 10% Ausschuss produziert werden, Millionen eingespart werden. Allerdings ist nicht vorhersehbar, ob eine solche Analyse tatsächlich nützliche Ergebnisse liefert, da die gesammelten Daten zu den Prozessbedingungen möglicherweise nicht alle erforderlichen Informationen enthalten.