Wie “lernen” Maschinen?
Wie lösen ML-Algorithmen diese “Input → Output” Probleme, also wie erkennen sie Muster und lernen Regeln aus Daten?
ML-Algorithmen lassen sich nach ihrer Funktionsweise, d.h. wie sie lernen, weiter unterteilen. Diese Unterteilung ist inspiriert von der Art und Weise wie Menschen lernen:

Analog dazu können auch Maschinen nach diesen drei Strategien lernen:
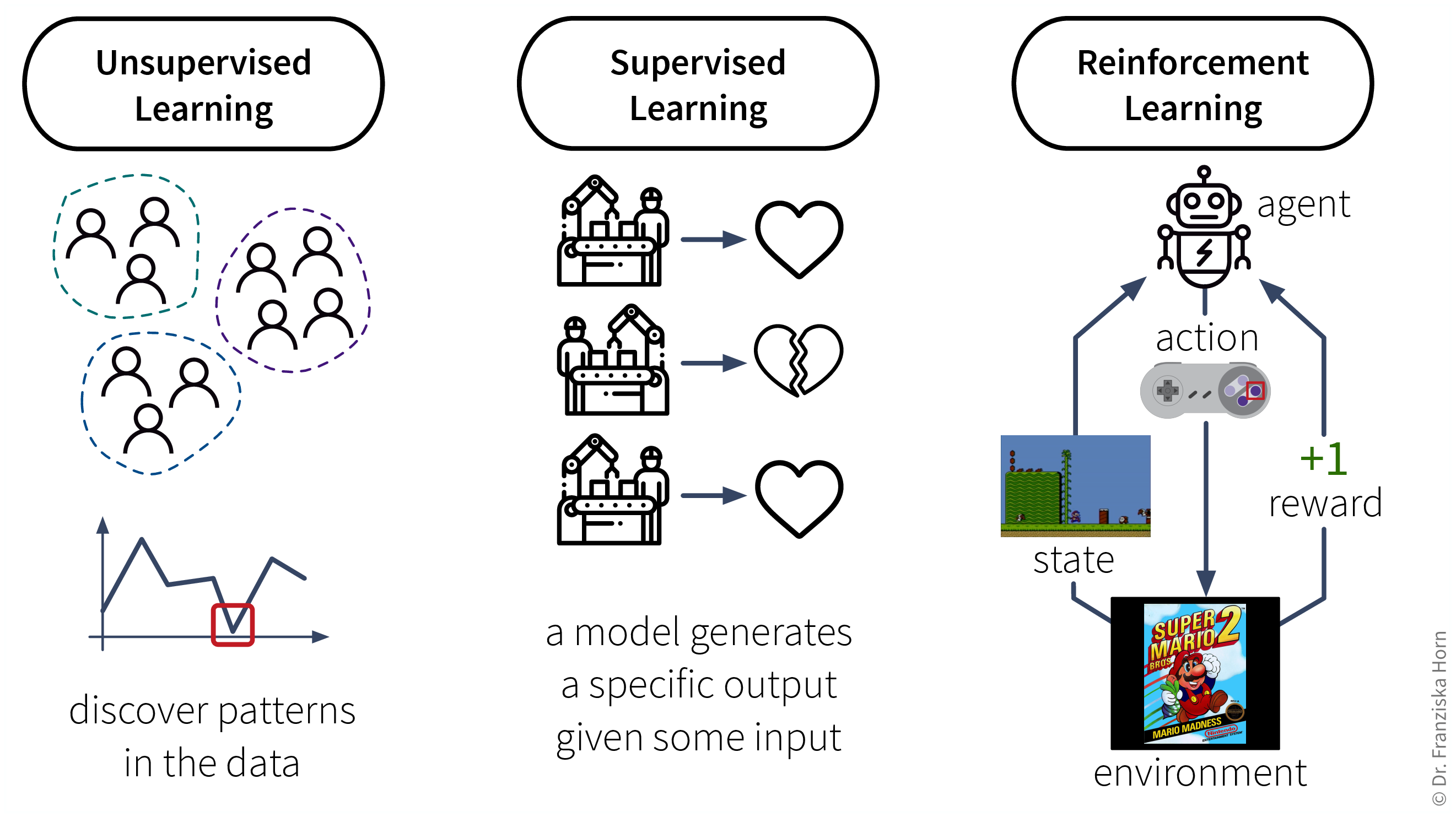
- Daten-Voraussetzungen für das Lernen mit diesen Strategien:
-
-
Unsupervised Learning: ein Datensatz mit Beispielen

-
Supervised Learning: ein Datensatz mit gelabelten Beispielen

-
Reinforcement Learning: eine (Simulations-) Umgebung, die, basierend auf den Aktionen des Agenten, Daten (Belohnung + neue Zustände) generiert

Aufgrund der Abhängigkeit von einer datenerzeugenden Umgebung ist Reinforcement Learning ein Sonderfall. Außerdem ist es derzeit noch sehr schwer, Reinforcement Learning Algorithmen zum Laufen zu bringen, weshalb sie hauptsächlich in der Forschung und weniger für praktische Anwendungen verwendet werden.
-
Supervised Learning
Supervised Learning ist die verbreitetste Art des maschinellen Lernens in heutigen Anwendungen.
Beim Supervised Learning möchten wir ein Modell (= eine mathematische Funktion) \(f(x)\) lernen, um den Zusammenhang zwischen einem oder mehreren Input(s) \(x\) (z.B. Produktionsbedingungen wie Temperatur, Material, etc.) und einem Output \(y\) (z.B. resultierende Produktqualität) zu beschreiben.
Dieses Modell kann dann verwendet werden, um Vorhersagen für neue Datenpunkte zu machen, also \(f(x') = y'\) für ein neues \(x'\) zu berechnen (z.B. für einen neuen Satz von Produktionsbedingungen vorhersagen, ob das Produkt von hoher Qualität sein wird, oder ob man den Vorgang lieber gleich abbrechen sollte).
- Supervised Learning — kurz und knapp:
-
 Zuerst muss man sich darüber im Klaren sein, was vorhergesagt werden soll und inwiefern einem die Vorhersage hilft, das eigentliche Ziel zu erreichen und Mehrwert generiert. Außerdem muss man sich überlegen, wie man den Erfolg misst, d.h. den Key Performance Indicator (KPI) des Prozesses bestimmen. Anschließend muss man Trainingsdaten sammeln. Da wir hier im Bereich des Supervised Learnings sind, müssen dies gelabelte Daten sein, also inkl. der Zielvariable, die man vorhersagen möchte. Dann “lernt” (oder “trainiert” oder “fittet”) man ein Modell auf diesen Daten um schließlich Vorhersagen für neue Datenpunkte zu generieren.
Zuerst muss man sich darüber im Klaren sein, was vorhergesagt werden soll und inwiefern einem die Vorhersage hilft, das eigentliche Ziel zu erreichen und Mehrwert generiert. Außerdem muss man sich überlegen, wie man den Erfolg misst, d.h. den Key Performance Indicator (KPI) des Prozesses bestimmen. Anschließend muss man Trainingsdaten sammeln. Da wir hier im Bereich des Supervised Learnings sind, müssen dies gelabelte Daten sein, also inkl. der Zielvariable, die man vorhersagen möchte. Dann “lernt” (oder “trainiert” oder “fittet”) man ein Modell auf diesen Daten um schließlich Vorhersagen für neue Datenpunkte zu generieren.
Features & Labels
Ein typisches Supervised Learning Problem wäre beispielsweise ein Produktionsprozess, bei dem wir vorhersagen möchten, ob ein unter bestimmten Produktionsbedingungen produziertes Teil Ausschuss ist. Hier beinhalten die gesammelten Daten für jedes produzierte Teil die Prozessbedingungen, unter denen es hergestellt wurde, und ob das resultierende Produkt in Ordnung oder Ausschuss war:
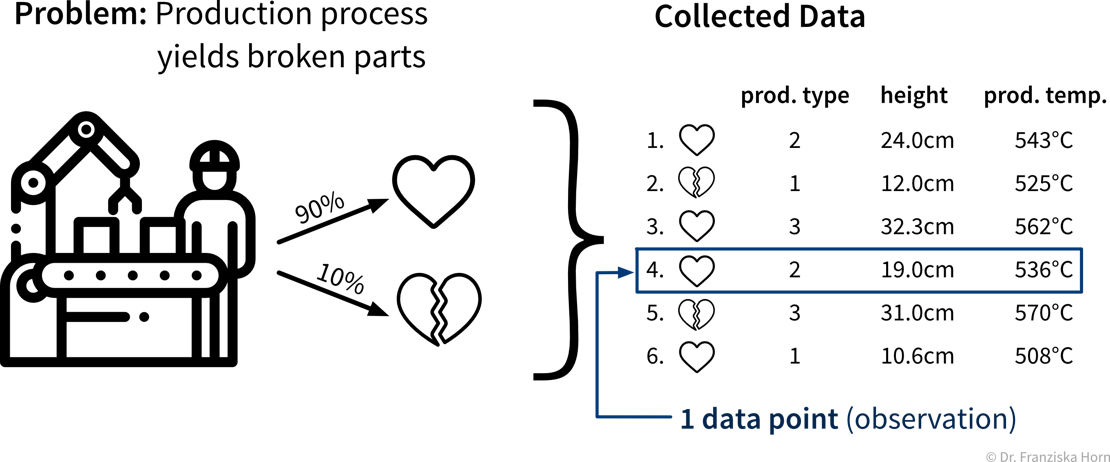
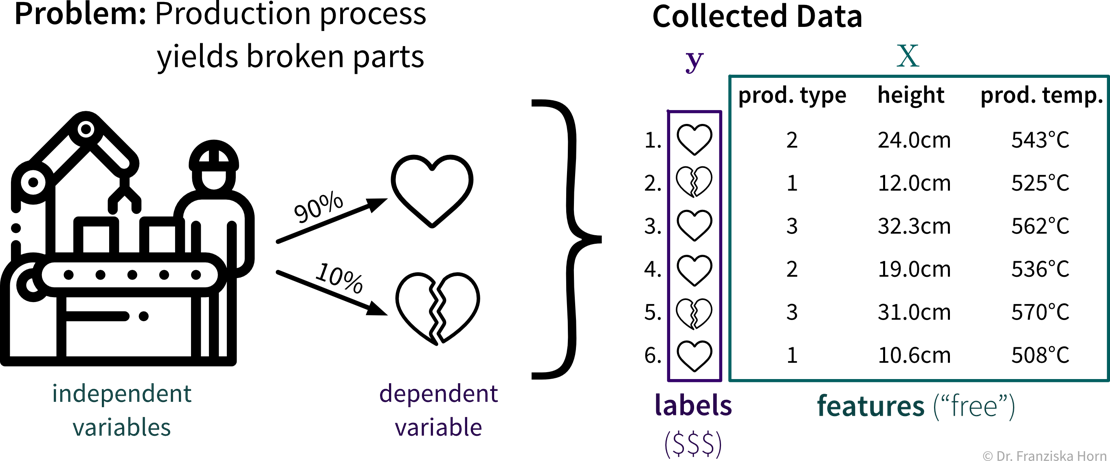
Im Supervised Learning werden die Features als Input (Eingabe) für das Modell verwendet, während die Labels die Zielvariable, d.h. der vorhergesagte Output (Ausgabe) darstellen. Im Allgemeinen sollten Features unabhängige Variablen sein (z.B. Einstellungen, die der Bediener nach Belieben wählen kann), während der Zielwert von diesen Eingaben abhängig sein sollte, damit wir ihn vorhersagen können.
Ein Modell aus Daten “lernen”
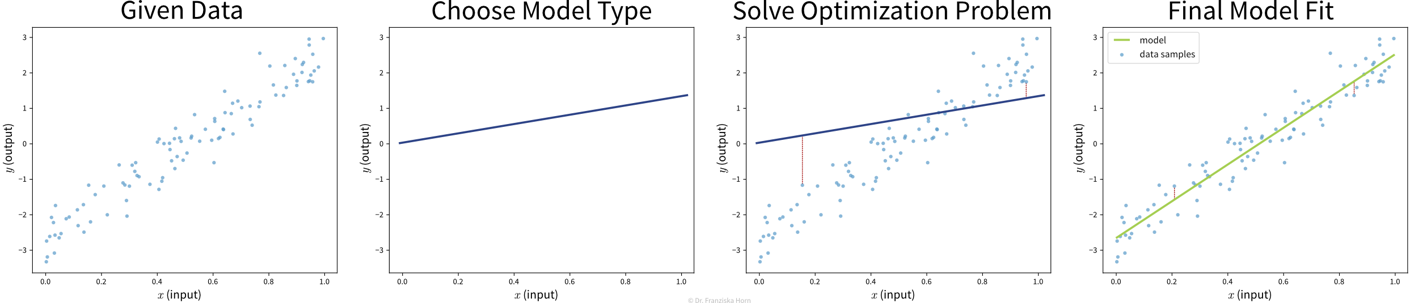
Ziel: Beschreibe den Zusammenhang zwischen Input(s) \(x\) und Output \(y\) mit einem Modell, d.h. einer mathematischen Funktion \(f(x)\)
-
Wähle eine Modell Klasse (= Struktur der Funktion): Annahme: Zusammenhang ist linear
→ lineares Regressionsmodell: \(y = f(x) = b + w\cdot x\) -
Definiere die Zielfunktion: Minimiere die Abweichung zwischen echtem & vorhergesagtem \(y\):
→ \(\min_{b,w} \sum_i (y_i - f(x_i))^2\) -
Finde die besten Modellparameter für die gegebenen Daten: d.h. löse das in Schritt 2 definierte Optimierungsproblem
⇒ \(f(x) = -2.7 + 5.2x\)
| Video Empfehlung: Wenn dir lineare Regression nichts sagt, findest du hier eine tolle Erklärung von der Google-Mitarbeiterin Cassie Kozyrkov zur Funktionsweise der linearen Regression, des einfachsten Supervised Learning Algorithmus: [Teil 1] [Teil 2] [Teil 3] |
Die existierenden Supervised Learning Algorithmen unterscheiden sich in der Art des \(x \to y\,\) Zusammenhangs, den sie beschreiben können (z.B. linear oder nichtlinear) und welche Art von Zielfunktion (auch Fehlerfunktion genannt) sie minimieren. Die Aufgabe eines Data Scientists besteht darin, einen für den Datensatz passenden Modelltyp auszuwählen. Den Rest erledigt dann eine Optimierungsmethode, die Parameter für das Modells findet, welche die Zielfunktion des Modells minimieren, d.h. sodass der Vorhersagefehler des Modells auf den gegebenen Daten so klein wie möglich ist.
| In diesem Buch werden die Begriffe “ML-Algorithmus” und “ML-Modell” meist synonym verwendet. Wenn man es aber genau nimmt, verarbeitet der Algorithmus die gegebenen Daten und lernt die Parameterwerte. Die gefundenen Parameter bestimmen das eigentliche Modell. Ein lineares Regressionsmodell wird beispielsweise durch seine Koeffizienten (d.h. die Parameter des Modells) definiert. Diese werden gefunden, in dem die Schritte des linearen Regressionsalgorithmus befolgt werden, also das Optimierungsproblem auf den gegebenen Daten gelöst wird. |
Da geht noch mehr!
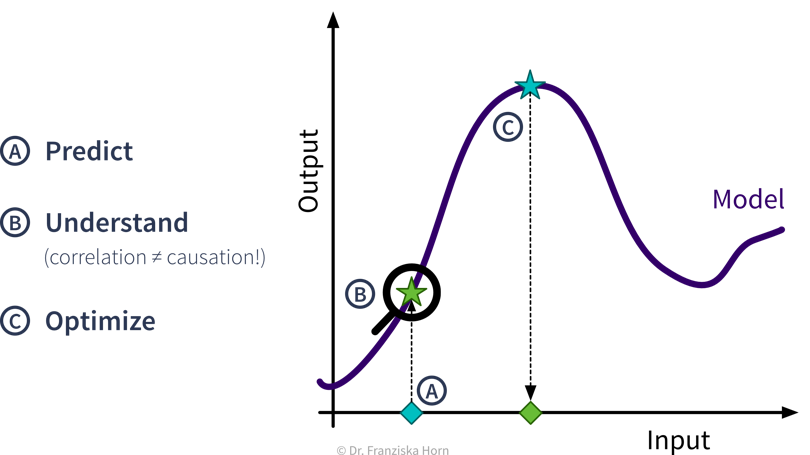
- Prädiktive Analyse
-
Mit Supervised Learning Algorithmen können wir basierend auf historischen Daten ein Vorhersagemodell generieren, das Prognosen über zukünftige Szenarien anstellt um uns bei Plannungen zu unterstützen. Beispiel: Verkaufsprognosen verwenden, um Lagerbestände besser zu planen.
- Interpretation Prädiktiver Modelle
-
Interpretiere das Vorhersagemodell und seine Prognosen, um die zugrundeliegenden Ursache-Wirkung Beziehungen des Prozesses besser zu verstehen.
Beispiel: Gegeben ein Modell, welches die Qualität eines Produkts aus den Produktionsbedingungen vorhersagt, verstehe welche Faktoren dazu führen dass Produkte von geringerer Qualität sind. - Was-wäre-wenn Analyse & Optimierung
-
Verwende ein Vorhersagemodell für eine Was-wäre-wenn-Vorhersage, um zu untersuchen, wie ein System auf unterschiedliche Bedingungen reagieren könnte (aber Vorsicht!).
Beispiel: Gegeben ein Modell, welches die verbleibende Lebenszeit für eine Maschinenkomponente aus den Prozessbedingungen vorhersagt, wie schnell würde diese Komponente unter anderen Prozessbedingungen verschleißen?Wenn wir noch einen Schritt weiter gehen wollen, können wir auch automatisch verschiedene Inputs mit dem Vorhersagemodell in einer Optimierungsschleife bewerten, um systematisch optimale Einstellungen zu finden.
Beispiel: Gegeben ein Modell, welches die Qualität eines Produkts aus den Produktionsbedingungen vorhersagt, bestimme automatisch die besten Produktionseinstellungen für einen neuen Rohstofftyp.