ML Anwendungsfälle
ML-Algorithmen können auf Input Daten in verschiedensten Formaten angewendet werden…
- Strukturierte vs. Unstrukturierte Daten
-
Daten können in verschiedenen Formaten vorliegen und während einige Datentypen evtl. zusätzliche Verarbeitungsschritte erfordern, können ML-Algorithmen im Prinzip mit jeder Art von Daten arbeiten.
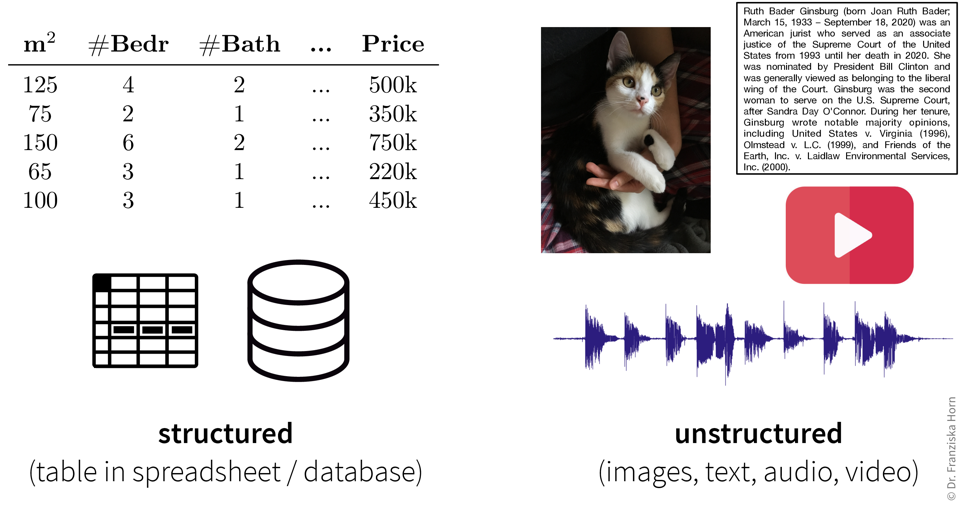 Die wichtigste Unterscheidung bei der Charakterisierung von Daten liegt zwischen strukturierten Daten, das ist jeder Datensatz, der einzelne Messgrößen/Variablen/Attribute/Features enthält, die eindeutige Größen darstellen, und unstrukturierten Daten, die nicht in sinnvolle Variablen unterteilt werden können. Z.B. in Bildern “erster Pixel von links” oder in Texten “10. Wort im 2. Absatz” würden wir nicht Variablen nennen, im Gegensatz zu “Fläche in Quadratmetern” oder “Anzahl Schlafzimmern”, womit man sinnvoll eine Wohnung beschreiben könnte. Strukturierte Daten sind oft heterogen, da die verschiedenen Variablen in einem Datensatz typischerweise für sehr unterschiedliche Dinge stehen. Wenn man beispielsweise mit Sensordaten arbeitet enthält ein Datensatz nicht nur Temperaturmessungen, sondern zusätzlich z.B. Druck und Durchflusswerte, die unterschiedliche Einheiten haben und in sehr unterschiedlichen Skalen gemessen werden können. Unstrukturierte Daten hingegen sind homogen, z.B. gibt es keinen qualitativen Unterschied zwischen dem 10. und dem 100. Pixel in einem Bild.
Die wichtigste Unterscheidung bei der Charakterisierung von Daten liegt zwischen strukturierten Daten, das ist jeder Datensatz, der einzelne Messgrößen/Variablen/Attribute/Features enthält, die eindeutige Größen darstellen, und unstrukturierten Daten, die nicht in sinnvolle Variablen unterteilt werden können. Z.B. in Bildern “erster Pixel von links” oder in Texten “10. Wort im 2. Absatz” würden wir nicht Variablen nennen, im Gegensatz zu “Fläche in Quadratmetern” oder “Anzahl Schlafzimmern”, womit man sinnvoll eine Wohnung beschreiben könnte. Strukturierte Daten sind oft heterogen, da die verschiedenen Variablen in einem Datensatz typischerweise für sehr unterschiedliche Dinge stehen. Wenn man beispielsweise mit Sensordaten arbeitet enthält ein Datensatz nicht nur Temperaturmessungen, sondern zusätzlich z.B. Druck und Durchflusswerte, die unterschiedliche Einheiten haben und in sehr unterschiedlichen Skalen gemessen werden können. Unstrukturierte Daten hingegen sind homogen, z.B. gibt es keinen qualitativen Unterschied zwischen dem 10. und dem 100. Pixel in einem Bild.
…aber unser Ziel, also der gewünschte Output, bestimmt welche Art von Algorithmus wir für das Problem verwenden sollten:
Einige Beispiele für Input → Output Aufgaben und welche Art von ML-Algorithmus verwendet werden kann, um sie zu lösen:
| Input \(X\) | Output \(Y\) | ML-Algorithmus Kategorie |
|---|---|---|
Fragebogenantworten |
Kundensegmentierung |
Clustering |
Sensormessungen |
alles normal? |
Anomalieerkennung |
Vergangene Nutzung einer Maschine |
Restlebensdauer |
Regression |
Spam (ja/nein) |
Klassifikation (binär) |
|
Bild |
welches Tier? |
Klassifikation (mehrere Klassen) |
Bisherige Einkäufe des Nutzers |
Produktvorschläge |
Empfehlungssysteme |
Suchanfrage |
relevante Dokumente |
Information Retrieval |
Audio |
Text |
Spracherkennung |
Text auf Englisch |
Text auf Französisch |
Maschinelle Übersetzung |
Zusammengefasst (siehe auch: Übersichtstabelle als PDF):
- Existierende ML-Lösungen & entsprechende Outputs (für einen Datenpunkt):
-
-
Dimensionsreduktion: (normalerweise) 2D-Koordinaten (um den Datensatz zu visualisieren)
-
Ausreißer-/Anomalieerkennung: Anomalie-Score (normalerweise ein Wert zwischen 0 und 1, der angibt, inwiefern dieser Punkt von der Norm abweicht)
-
Clustering: Cluster-Index (eine Zahl zwischen 0 und k-1, die angibt, zu welchem der k Cluster ein Datenpunkt gehört (oder -1 für Ausreißer))
-
Regression: ein kontinuierlicher Wert (eine numerischer Größe, die vorhergesagt werden soll)
-
Klassifikation: ein diskreter Wert (eine von mehreren sich gegenseitig ausschließenden Kategorien)
-
Generative AI: unstrukturierte Outputs wie Text oder Bild (z.B. Spracherkennung, maschinelle Übersetzung, Bild Generierung oder Neural Style Transfer)
-
Empfehlungssysteme & Information Retrieval: Rangliste einer Menge von Elementen (Empfehlungssysteme ordnen beispielsweise die Produkte nach Relevanz für den jeweiligen Nutzer; Information Retrieval Systeme sortieren Elemente nach ihrer Ähnlichkeit zu einer gegebenen Suchanfrage)
-
Reinforcement Learning: eine Sequenz von Aktionen (abhängig vom Zustand in dem sich der Agend befindet)
-
Beginnen wir mit einem detaillierteren Blick auf die verschiedenen Unsupervised und Supervised Learning Algorithmen und wie sie uns helfen können:
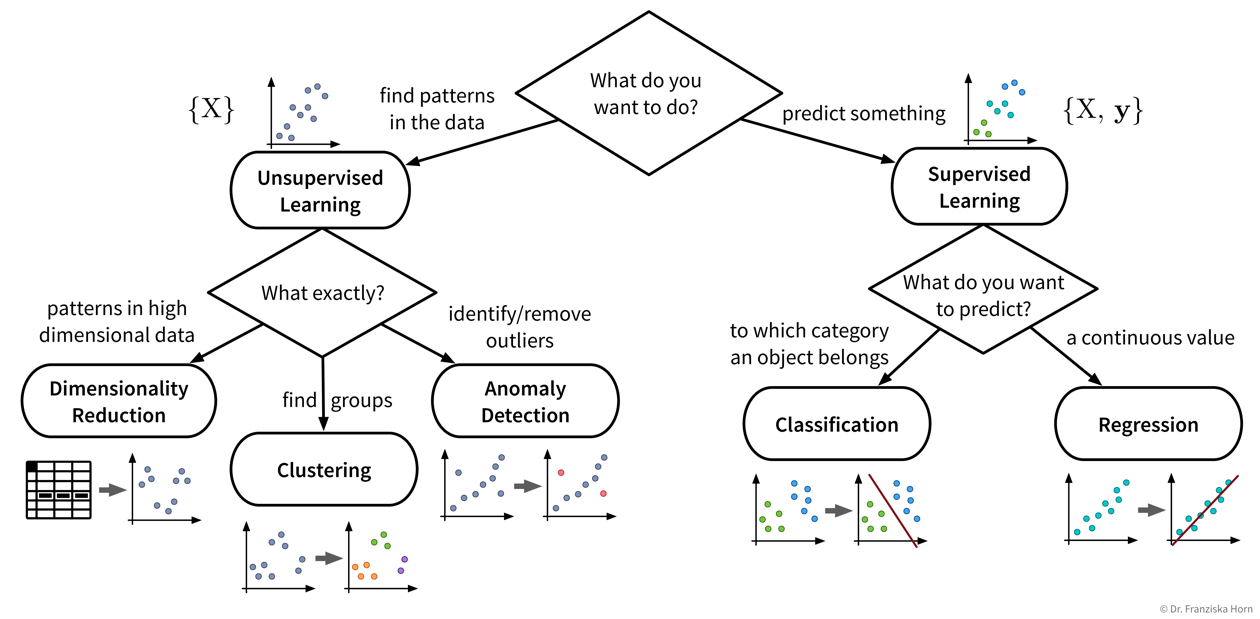
| Auch wenn unser eigentliches Ziel darin besteht, etwas vorherzusagen (also Supervised Learning zu verwenden), kann es dennoch sehr hilfreich sein, zunächst Unsupervised Learning Algorithmen anzuwenden, um den Datensatz besser zu verstehen. Beispielsweise kann man die Daten im Vorfeld mit Dimensionsreduktionsmethoden visualisieren, um alle Datenpunkte und ihre Vielfalt auf einen Blick zu sehen. Anschließend kann man den Datensatz bereinigen, in dem man Ausreißer identifiziert. Bei einem Klassifikationsproblem ist es häufig sinnvoll, die Datenpunkte zuerst zu clustern, um zu überprüfen, in wie weit die angegebenen Klassenlabels mit den natürlich vorkommenden Gruppen in den Daten übereinstimmen. Beispielsweise sieht man dann vielleicht, dass man das Problem vereinfachen kann, in dem man zwei sehr ähnliche Klassen kombiniert. |
Dimensionsreduktion
-
Erstellen einer 2D-Visualisierung, um den Datensatz im Ganzen zu überblicken, wobei wir oft bereits beim Draufschauen Muster identifizieren können, wie Datenpunkte, die zusammen gruppiert werden können (Cluster) oder die nicht ins Bild passen (Ausreißer)
-
Rauschunterdrückung und/oder Feature-Engineering als Datenvorverarbeitungsschritt zur Verbesserung der Ergebnisse eines Vorhersagemodells
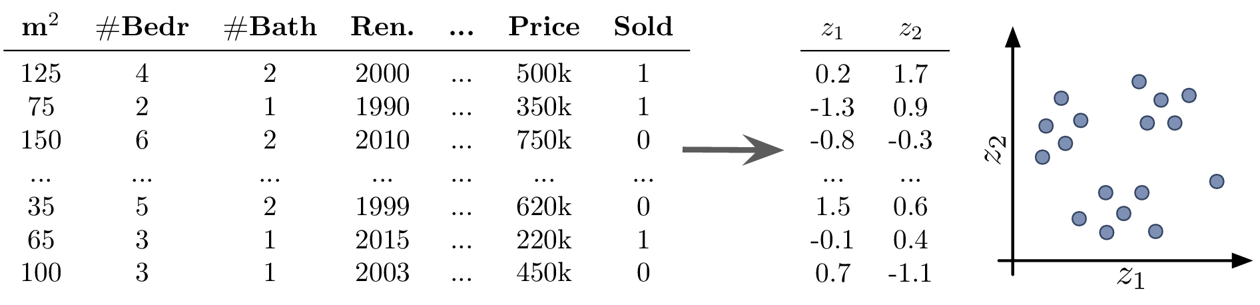
- Beispiel Unsupervised Learning: Dimensionsreduktion
-
Ziel: Datensatz visualisieren
-
die Transformation der Daten mit Dimensionsreduktionsmethoden konstruiert neue Features als (nicht)lineare Kombination der ursprünglichen Features, was die Interpretation der nachfolgenden Analyseergebnisse erschwert
Anomalieerkennung
-
Bereinigung der Daten, z.B. durch Entfernen von Datenpunkten mit falsch eingegebenen Werten, als Datenvorverarbeitungsschritt zur Verbesserung der Ergebnisse eines Vorhersagemodells
-
Warnung für Anomalien einrichten, zum Beispiel:
-
Betrugserkennung: Identifizierung betrügerischer Kreditkartentransaktionen im E-Commerce
-
Überwachen einer Maschine, um zu erkennen, wenn etwas Außergewöhnliches passiert oder die Maschine möglicherweise gewartet werden muss
-
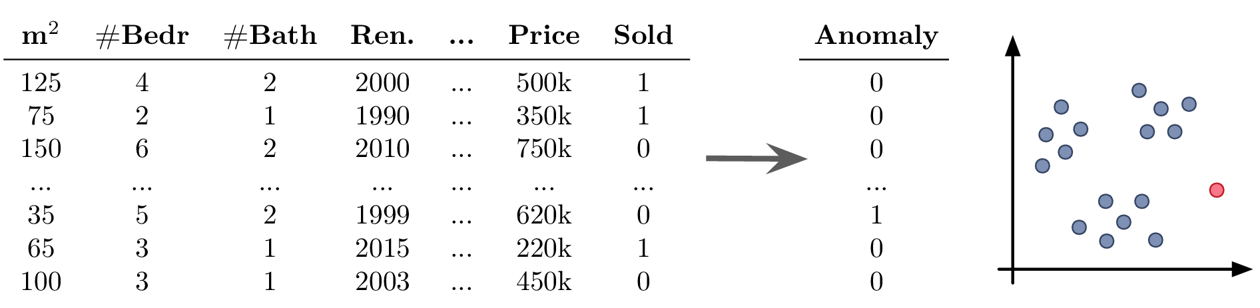
- Beispiel Unsupervised Learning: Anomalieerkennung
-
Ziel: Ausreißer im Datensatz finden
-
du solltest immer einen guten Grund haben, Datenpunkte weg zu lassen – Ausreißer sind selten zufällig, manchmal sind dies interessante Randfälle, die nicht ignoriert werden sollten
Clustering
-
Identifizieren von Gruppen verwandter Datenpunkte, zum Beispiel:
-
Kundensegmentierung für gezielte Marketingkampagnen
-
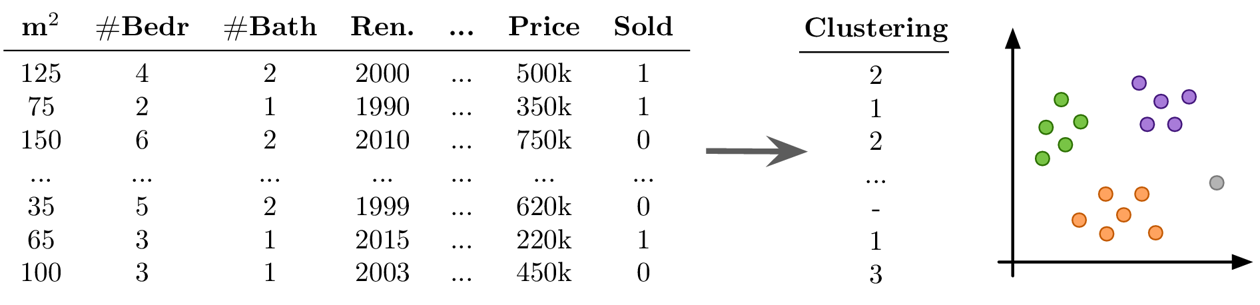
- Beispiel Unsupervised Learning: Clustering
-
Ziel: Natürlich vorkommende Gruppen im Datensatz finden
-
keine Ground Truth: Modell- und Parameterselektion nicht trivial → die Algorithmen werden immer etwas finden, aber ob dies sinnvoll ist (d.h. was die identifizierten Muster bedeuten), kann ein Menschen in einem Nachbearbeitungsschritt bestimmen
-
viele der Algorithmen beruhen auf Ähnlichkeiten oder Distanzen zwischen Datenpunkten, und es kann schwierig sein, dafür ein geeignetes Maß zu definieren oder im Voraus zu wissen, welche Merkmale verglichen werden sollten (z.B. was macht zwei Kunden ähnlich?)
Unsupervised Learning hat keine zugrundeliegende Wahrheit
Bei Unsupervised Learning Problemen sollte uns bewusst sein, dass es keine richtigen oder falschen Antworten gibt. Unsupervised Learning Algorithmen erkennen lediglich Muster in den Daten. Das Ergebnis kann für uns Menschen sinnvoll sein oder auch nicht.
Ein Beispiel: Im Bereich Unsupervised Learning gibt es eine Reihe verschiedener Algorithmen, die Datenpunkte in Cluster gruppieren. Dabei arbeitet jeder Algorithmus nach einer etwas anderen Strategie und bewertet unterschiedlich, ab wann zwei Punkte ähnlich genug sind, dass sie in denselben Cluster eingeordnet werden können.
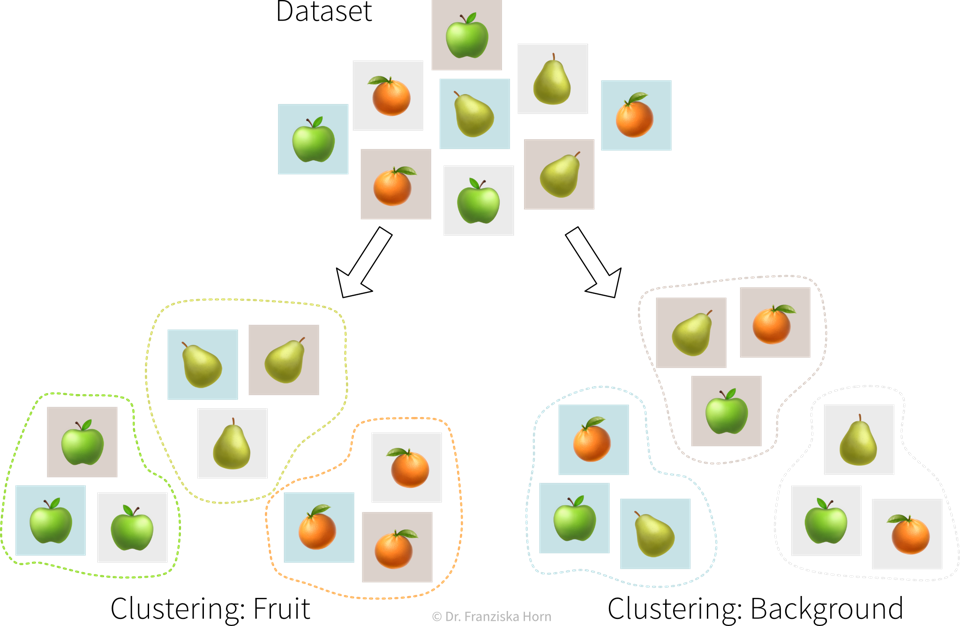
Es ist unsere Aufgabe, die Ergebnisse eines Unsupervised Learning Algorithmus zu untersuchen und zu verstehen. Entsprechen die Resultate nicht unseren Erwartungen, spricht nichts dagegen, einen anderen Algorithmus auszuprobieren.
Regression & Klassifikation
-
Lerne ein Modell, um eine Input-Output-Beziehung zu beschreiben und Vorhersagen für neue Datenpunkte zu treffen, zum Beispiel:
-
vor der Produktion vorhersagen, ob ein unter den vorgeschlagenen Prozessbedingungen hergestelltes Produkt von hoher Qualität oder Ressourcenverschwendung sein wird
-
Churn Prediction: Erkenne Kunden, die kurz davor stehen, ihren Vertrag zu kündigen (oder Mitarbeiter, die kurz davor stehen zu kündigen), damit du sie kontaktieren und überzeugen kannst zu bleiben
-
Preisoptimierung: Bestimme den optimalen Preis für ein Produkt (oft für dynamische Preisgestaltung verwendet, z.B. um Preise basierend auf dem Gerät anzupassen, das ein Kunde verwendet, wenn er auf eine Website zugreift, wie z. B. ein neues iPhone gegenüber einem alten Android-Handy)
-
Predictive Maintenance: Sage voraus, wie lange ein Maschinenbauteil halten wird
-
Umsatzprognosen: Sag den Umsatz in den kommenden Wochen und den erforderlichen Lagerbestand voraus, um die Nachfrage zu befriedigen
-
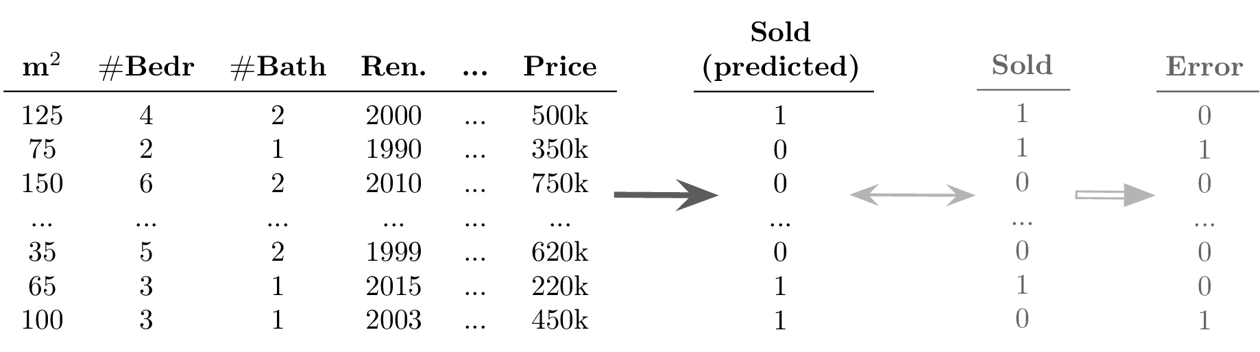
- Beispiel Supervised Learning: Klassifikation
-
Ziel: Vorhersage eines diskreten Werts für jeden Datenpunkt
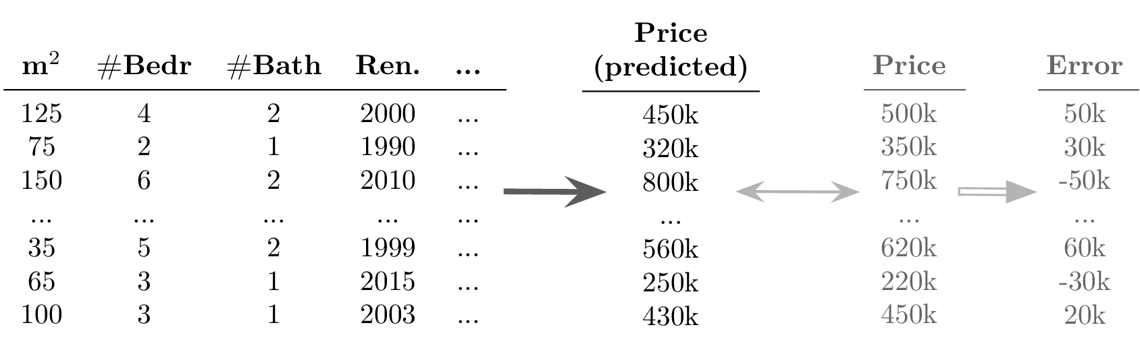
- Beispiel Supervised Learning: Regression
-
Ziel: Vorhersage eines kontinuierlichen Werts für jeden Datenpunkt
-
Erfolg ungewiss: die Anwendung der Algorithmen ist zwar relativ einfach, aber es ist schwierig, im Voraus festzustellen, ob überhaupt ein Zusammenhang zwischen den gemessenen Inputs und Outputs besteht (→ Achtung: Garbage in, Garbage out!)
-
angemessene Definition des Ergebnisses/Ziels/KPI, das modelliert werden soll, d.h. was bedeutet es eigentlich, dass ein Prozess gut läuft, und wie könnten externe Faktoren diese Definition beeinflussen (können wir z.B. die gleiche Leistung in einem außergewöhnlich heißen Sommertag erwarten?)
-
wichtige Inputs fehlen, z.B. wenn es andere Einflussfaktoren gibt, die wir nicht berücksichtigt haben oder nicht messen konnten, wodurch nicht die gesamte Varianz der Zielgröße erklärt werden kann
-
viele möglicherweise irrelevante Inputs, die eine sorgfältige Feature Selektion erfordern, um Scheinkorrelationen zu vermeiden, die zu falschen “Was-wäre-wenn”-Prognosen führen würden, da die wahre kausale Beziehung zwischen den Inputs und Outputs nicht erfasst wird
-
oft sehr zeitintensive Datenvorverarbeitung notwendig, z.B. bei der Zusammenführung von Daten aus unterschiedlichen Quellen und manuellem Feature Engineering
Deep Learning & Generative AI
-
Automatisierung langwieriger, repetitiver Aufgaben, die sonst ein Menschen erledigt würde, z.B. (siehe auch ML ist überall!):
-
Textklassifizierung (z.B. Spam / Hate Speech / Fake News erkennen; Kundensupportanfragen an die passende Abteilung weiterleiten)
-
Sentimentanalyse (Teilaufgabe der Textklassifikation: Positive oder negative Texte erkennen, z.B. um Produktbewertungen oder das, was Social-Media-Nutzer über ein Unternehmen sagen, zu überwachen)
-
Spracherkennung (z.B. diktierte Notizen transkribieren oder Videos mit Untertiteln versehen)
-
maschinelle Übersetzung (Texte von einer Sprache in eine andere übersetzen)
-
Bildklassifizierung / Objekterkennung (z.B. Identifizierung problematischer Inhalte (wie Kinderpornografie) oder Erkennung von Straßenschildern und Fußgängern beim autonomen Fahren)
-
Bildbeschreibungen generieren (z.B. um das Online-Erlebnis für Menschen mit Sehbehinderung zu verbessern)
-
Predictive Typing (z.B. bei der Texteingabe auf dem Smartphone mögliche nächste Wörter vorschlagen)
-
Datengenerierung (z.B. neue Fotos/Bilder von bestimmten Objekten oder Szenen generieren)
-
Style Transfer (ein Bild in einen anderen Stil zeigen, z.B. Fotos wie van Gogh-Gemälde aussehen lassen)
-
einzelne Quellen eines Audiosignals trennen (z.B. einen Song entmischen, d.h. Gesang und Instrumente in einzelne Spuren trennen)
-
-
klassische Simulationsmodelle durch ML Modelle ersetzen: da exakte Simulationsmodelle oft langsam sind, kann die Berechnung für neue Datenpunkte beschleunigt werden, indem die Ergebnisse stattdessen mit einem ML-Modell vorhergesagt werden, z.B.:
-
AlphaFold: 3D-Proteinstruktur aus Aminosäuresequenz generieren (zur Erleichterung der Arzneimittelentwicklung)
-
SchNet: Energie und andere Eigenschaften von Molekülen anhand ihrer Atomkonfiguration vorhersagen (um die Materialforschung zu beschleunigen)
-
-
Auswählen einer geeigneten neuronalen Netzarchitektur und dafür sorgen, dass das Modell gute Vorhersagen generiert; insbesondere beim Ersetzen traditioneller Simulationsmodelle ist es häufig erforderlich, eine völlig neue Art von neuronaler Netzarchitektur zu entwickeln, die speziell für diese Aufgabe und Inputs/Outputs ausgelegt ist, was viel ML- und Domänenwissen, Intuition und Kreativität erfordert
-
Rechenressourcen (trainiere kein neuronales Netz ohne GPU!)
-
Datenqualität und -quantität: es werden viele konsistent (von Menschen) gelabelte Daten benötigt
Information Retrieval
-
Verbesserte Suchergebnisse durch Identifizierung ähnlicher Artikel, zum Beispiel:
-
bei einer Suchanfrage passende Dokumente / Websites zurückgeben
-
gegeben einem Film, den der Nutzer gerade anschaut, ähnliche Filme anzeigen (z.B. gleiches Genre, gleicher Regisseur usw.)
-
-
Qualität der Ergebnisse hängt stark von der gewählten Ähnlichkeitsmetrik ab; die Identifizierung semantisch verwandter Elemente ist derzeit für einige Datentypen (z.B. Bilder) schwieriger als für andere (z.B. Text)
Empfehlungssysteme
-
personalisierte Vorschläge: gegeben einer Instanz (z.B. Benutzer, Proteinstruktur) die relevantesten Elemente identifizieren (z.B. Film, Arzneimittelzusammensetzung), zum Beispiel:
-
einem Nutzer Filme vorschlagen, die anderen Nutzern mit ähnlichem Geschmack ebenfalls gefallen haben
-
Molekülstrukturen empfehlen, die in eine, für eine bestimmte Krankheit relevante, Proteinstruktur passen könnte
-
-
wenig / unvollständige Daten, z.B. mögen verschiedene Nutzer denselben Artikel aus unterschiedlichen Gründen und es ist unklar, ob z.B. ein Nutzer einen Film nicht angesehen hat, weil er sich nicht dafür interessiert oder weil er ihn einfach noch nicht gefunden hat
Reinforcement Learning
-
Ermittlung einer optimalen Handlungsabfolge bei wechselnden Umgebungsbedingungen, z.B.:
-
Virtueller Agent, der ein (Video-)Spiel spielt
-
Roboter mit komplexen Bewegungsmustern, z.B. Aufnehmen unterschiedlich geformter Gegenstände aus einer Kiste
-
⇒ Anders als bei der regulären Optimierung, wo eine optimale Eingabe für einen spezifischen externen Zustand bestimmt wird, versucht hier ein “Agent” (= der RL-Algorithmus) eine optimale Reihenfolge von Eingaben zu finden, um die kumulative Belohnung über mehrere Schritte zu maximieren. Dabei kann zwischen einer Handlung und der dazugehörigen Belohnung eine erhebliche Zeitverzögerung liegen (z.B. wenn in einem Videospiel zu Beginn eines Levels ein Schlüssel gefunden werden muss, aber die Tür, die damit geöffnet werden kann, erst einige Frames später kommt).
-
erfordert normalerweise eine Simulationsumgebung, in der der Agent “angelernt” wird, bevor er anfängt, in der realen Welt zu handeln. Die Entwicklung eines exakten Simulationsmodells ist allerdings nicht einfach und der Agent wird alle Bugs ausnutzen, wenn dies zu höheren Belohnungen führt
-
es kann schwierig sein, eine klare Belohnungsfunktion zu definieren, die optimiert werden soll (“Imitation Learning” ist dabei oft einfacher, wobei der Agent stattdessen versucht, die Entscheidungen eines Menschen in einer bestimmten Situation nachzuahmen)
-
lange Verzögerungen zwischen kritischen Aktionen und der dazugehörigen Belohnung erschweren das lernen korrekter Assoziationen
-
der Agent generiert seine eigenen Daten: Wenn er mit einer schlechten Policy startet, wird es schwierig, dieser zu entkommen (z.B. wenn der Agent in einem Videospiel immer in eine Lücke fällt, anstatt darüber zu springen, sieht er nie die Belohnung, die auf der anderen Seite wartet und lernt daher nicht, dass es von Vorteil wäre, über die Lücke zu springen)
Andere
| ML-Algorithmen werden anhand des Outputs kategorisiert, den sie für eine Eingabe generieren. Wenn man ein ‘Input → Output’-Problem mit einem anderen als den oben aufgeführten Outputs lösen möchte, wird das wahrscheinlich auf ein mehrjähriges Forschungsprojekt hinauslaufen — wenn das Problem überhaupt mit ML gelöst werden kann! |