Mit ML Probleme lösen
Das Lösen von “Input → Output”-Problemen mit ML erfordert drei Hauptschritte:
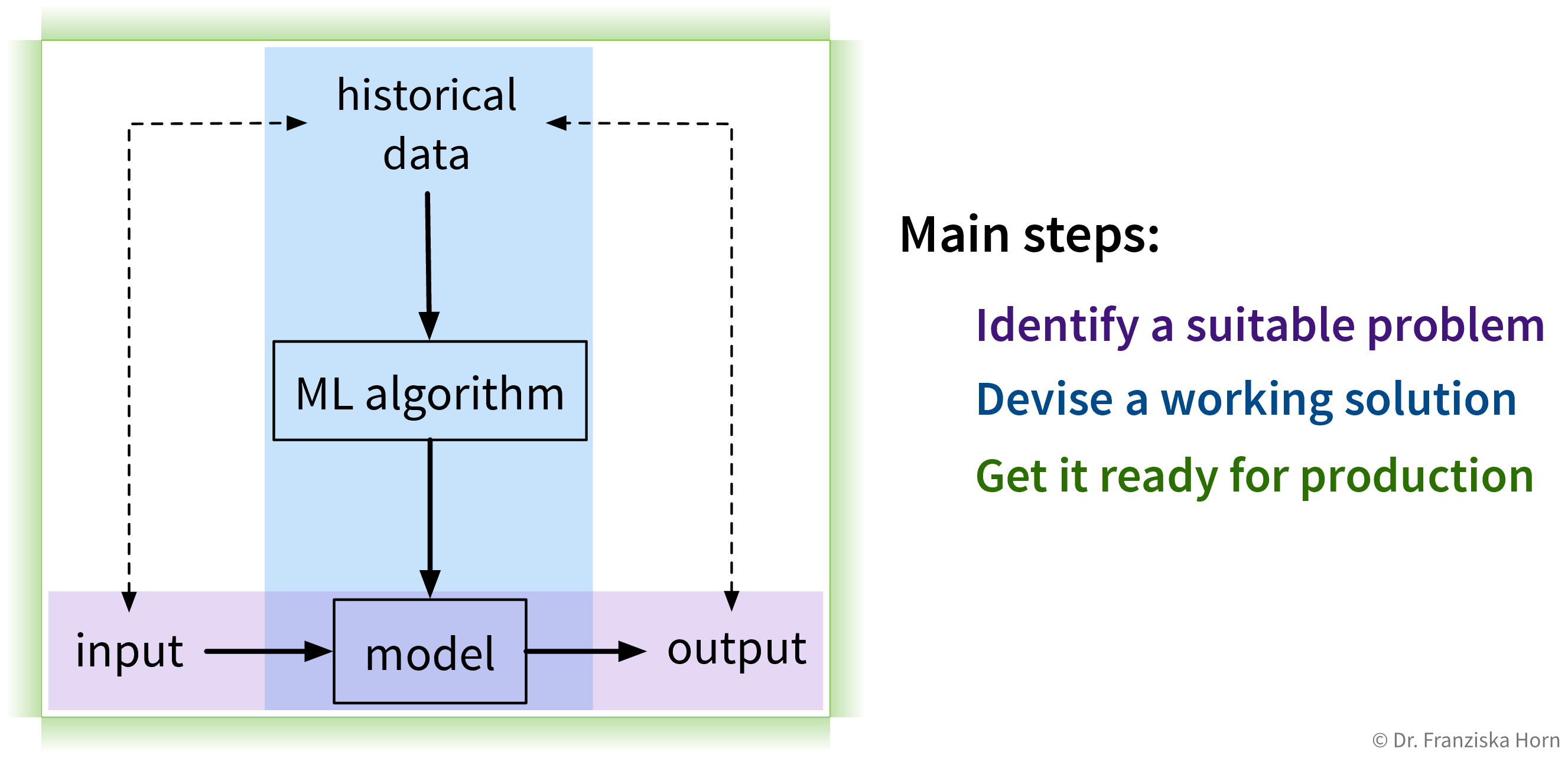
1. Identifiziere ein Problem
Der erste (und wohl wichtigste) Schritt besteht darin, zu identifizieren, wo maschinelles Lernen überhaupt eingesetzt werden kann (und sollte).
ML Projekt Checkliste
Motivation
-
Welches Problem möchtest du lösen?
Machine Learning kann dir in verschiedenen Situationen helfen, z.B. indem es Erkenntnisse aus großen Mengen (möglicherweise unstrukturierter) Daten generiert, Entscheidungsfindungs- und Planungsprozesse durch Vorhersagen über zukünftige Ereignisse verbessert, oder mühsame Aufgaben automatisiert, die sonst menschliche Experten erfordern.
Wo läuft etwas ineffizient, was durch eine effektivere Nutzung von Daten verbessert werden könnte? Du könntest zum Beispiel nach Möglichkeiten suchen, verschwendete Ressourcen/Zeit/Kosten zu reduzieren oder den Umsatz/die Kundenzufriedenheit/usw. zu steigern.
Um systematisch Probleme oder Verbesserungsmöglichkeiten zu erkennen, kann es auch helfen, ein Prozessdiagramm oder eine Customer Journey Map zu erstellen. -
Auf welche Art und Weise würde dies Wert für eure Organisation generieren?
Wie könnte eure Organisation damit Geld verdienen oder Kosten senken?-
Könnte dies einen internen Prozess verbessern (z.B. könnte ein Prozess mit den Erkenntnissen aus einer Analyse effizienter gestaltet werden oder eine lästige Aufgabe, die sonst einen menschlichen Arbeiter erfordern würde, kann mithilfe eines ML-Modells automatisiert werden)?
-
Könnte das ML-Modell als neues Feature in ein bestehendes Produkt integriert werden und dadurch z.B. dieses Produkt für Kunden attraktiver machen?
-
Könnte die ML-Lösung als völlig neues Produkt oder Service verkauft werden, z.B. als Software-as-a-Service (SaaS)-Lösung angeboten werden?
Bitte beachte, dass die letztendliche Verwendung der ML-Lösung auch eine strategische Entscheidung sein kann, die für jede Organisation unterschiedlich sein kann. Beispielsweise könnte eine ML-Lösung, die Kratzer auf produzierten Produkten erkennt, von einem Unternehmen verwendet werden, um ihren internen Produktionsprozess zu verbessern, während ein anderes Unternehmen, das die Maschinen herstellt, die die Produkte herstellen, dies als neues Feature in seine Maschinen integrieren könnte, und ein drittes Unternehmen bietet dies möglicherweise als SaaS-Lösung an, die mit verschiedenen Produktionslinien kompatibel ist.
-
-
In welcher Größenordnung könnte dieses Projekt Mehrwerte generieren?
Überlege dir den Impact im Hinblick auf-
Größenordnung: Kleine Verbesserung oder Revolution? Würde die Lösung einen strategischen Vorteil schaffen?
-
Skalierung: Wie oft wird es verwendet? Wie viele Benutzer/Kunden/Mitarbeiter werden davon profitieren?
Zum Beispiel:
-
Kleine Prozessoptimierung, aber da dieser Prozess täglich in der gesamten Organisation verwendet wird, spart dies unzählige Stunden
-
Neue Funktion, die ein Produkt revolutioniert und euch von der Konkurrenz abhebt, aber der Markt dafür ist winzig
-
-
Hätte dies irgendwelche wertvollen Nebenwirkungen? Was wird anders sein? Gibt es zusätzliche Möglichkeiten, die sich daraus ergeben könnten? Können Synergien geschaffen werden zwischen Abteilungen, die mit ähnlichen Daten arbeiten?
-
-
Wann hast du dein Ziel erreicht?
Wie würde Erfolg aussehen, d.h. was ist deine Definition von ‘fertig’?-
Kannst du den Fortschritt mit einem KPI quantifizieren?
-
Wie ist der Status quo, d.h. wie weit bist du derzeit von deinem Ziel entfernt?
-
Welche Metriken sollten sich nicht verändern (verschlechtern) durch das Projekt?
-
Lösungsansatz
-
Wie sieht deine Vision für die Zukunft mit ML aus?
-
Wie sieht dein bestehender Prozess / dein bestehendes System aus und was wird nach der Integration der ML-Lösung anders sein?
-
Wer sind die Nutzer und wie werden sie von dieser Veränderung betroffen sein, brauchen sie z.B. zusätzliche Schulungen, um das neue System zu nutzen?
-
-
Was sind die Deliverables?
Besteht die Lösung aus einer Software, die irgendwo eingesetzt wird, um kontinuierlich Vorhersagen für neue Datenpunkte zu generieren, oder interessierst du dich für die Erkenntnisse, die aus einer einmaligen Analyse historischer Daten gewonnen werden? -
Wie wird im Falle einer Softwarelösung das ML-Modell in das bestehende Setup integriert?
-
Wie sieht eine Interaktion mit dem System aus (= 1 Datenpunkt / Beobachtung), z.B. ein Nutzer, der eine Anfrage stellt oder ein produziertes Produkt, das eine Qualitätskontrolle passiert?
-
Von welchem System stammen die Inputs für das ML-Modell? Was passiert mit den Outputs des ML-Modells?
-
Wird eine zusätzliche Benutzeroberfläche (UI) oder API benötigt, um mit dem ML-Modell zu interagieren?
-
Muss das ML-Modell Vorhersagen sofort treffen, sobald neue Daten eintreffen, oder kann es Daten asynchron in Batches verarbeiten? Wie hoch ist der erwartete Traffic (d.h. die Anzahl der Datenpunkte, die pro Sekunde verarbeitet werden müssen)?
-
Wie sollte das ML-Modell deployed werden (z.B. Cloud, On-Premise oder Edge-Gerät)? Erfordert dies zusätzliche Infrastruktur oder spezielle Hardware (z.B. GPUs)?
-
Modellwartung: Was sind die Pläne im Hinblick auf Pipelines für zukünftige Datenerfassung, Modellüberwachung und automatisiertes Nachtrainieren?
-
-
Wie sehen die Input Daten aus? Wie sollen die Outputs aussehen?
-
Welche Art von Inputs bekommt das ML Modell (z.B. Bild / Text / Sensormessungen / etc.)?
-
Welche Art von Outputs soll das ML-Modell produzieren, d.h. welche Kategorie von ML-Algorithmen löst dieses Problem?
-
Hast du bereits Zugriff auf einen initialen Datensatz, um das Modell zu trainieren?
-
-
Wie soll die Performance des ML-Modells evaluiert werden?
-
Welche Evaluierungsmetriken sind für den gegebenen ML-Anwendungsfall geeignet (z.B. Accuracy)?
-
Wie stehen diese Metriken in Zusammenhang mit den Geschäfts-KPIs, die durch diese Lösung verbessert werden sollen?
-
Wie kann die Performance des Modells im laufenden Betrieb überwacht werden? Werden dafür kontinuierlich neue gelabelte Daten gesammelt?
-
-
Gibt es eine einfachere Lösung ohne ML?
Verwende ML, um unbekannte, komplexe Regeln aus Daten zu lernen.-
Auch wenn ML hier die richtige Wahl ist, könntest du ein minimal funktionsfähiges Produkt ohne ML entwickeln, um die Lösung als Ganzes zu validieren, bevor du in ML investierst?
-
Herausforderungen & Risiken
-
Gibt es genügend hochwertige Daten um das Modell zu trainieren und zu evaluieren?
-
Qualität: Hast du die richtigen Inputs und eindeutige Labels?
→ Frage eine Fachexpertin, ob sie denkt, dass alle relevanten Inputs vorhanden sind, um das gewünschte Ergebnis zu berechnen. Dies ist bei unstrukturierten Daten wie Bildern in der Regel leicht zu bestimmen - wenn ein Mensch das Objekt im Bild sehen kann, sollte es ML auch können. Aber bei strukturierten Daten, wie z.B. einer Tabelle mit Hunderten von Spalten mit Sensormessungen, kann dies unmöglich zu bestimmen sein, bevor man eine Analyse der Daten durchführt. -
Quantität: Wie viele Daten wurden bereits gesammelt (einschließlich seltener Ereignisse und Labels)? Wie lange würde es dauern, mehr Daten zu sammeln? Könnten zusätzliche Daten von einem Anbieter gekauft werden und wenn ja, wie viel würde das kosten?
-
Wie schwierig ist es, auf alle Daten zuzugreifen und sie ordentlich an einem Ort zu kombinieren? Mit wem würdest du sprechen, um die Dateninfrastruktur einzurichten/zu verbessern?
-
Wie viel Vorverarbeitung ist notwendig (z.B. Entfernung von Ausreißern, Korrigieren fehlender Werte, Feature Engineering, d.h. Berechnung neuer Variablen aus den bestehenden Messungen, etc.)? Was sollten die nächsten Schritte sein, um die Datenqualität und -quantität systematisch zu verbessern und die Vorverarbeitungsanforderungen in Zukunft zu verringern?
-
-
Kann das Problem mit einem existierenden ML-Algorithmus gelöst werden?
Frage eine ML-Expertin, ob ein ähnliches Problem bereits mit einem bewährten Algorithmus gelöst wurde.-
Für bekannte Lösungen: Wie komplex ist es, das Modell zum Laufen zu bringen (z.B. lineare Regression vs. tiefes neuronales Netz)?
-
Für unbekannte Lösungen: Anstatt Jahre in die Forschung zu investieren, um einen neuartigen Algorithmus zu entwickeln, wäre es möglich, das Input-Output-Problem in einfachere Teilprobleme mit bekannten Lösungen zu zerlegen?
-
-
Was würde im schlimmsten Fall passieren, wenn das Modell falsch liegt?
Das ML-System wird (wie Menschen auch) Fehler machen. Benutze kein ML wenn du immer 100% korrekte Ergebnisse brauchst!-
Welches Performance-Level wird mindestens benötigt, damit die ML-Lösung Mehrwert liefert? Z.B. welche Falsch Positiv oder Falsch Negativ Rate wäre noch akzeptabel? Was wäre das Worst-Case-Szenario und wie viel Risiko bist du bereit einzugehen?
-
Wie wahrscheinlich ist es, dass sich die Inputs im Laufe der Zeit ändern, beispielsweise auf Grund sich ändernder Demographie der Nutzer oder durch unerwartete Ereignisse (Black Swan Events) wie eine Pandemie (z.B. COVID-19)? Wie oft müsste man das Modell nachtrainieren, um diese Veränderungen zu kompensieren und werden dafür schnell genug neue (gelabelte) Daten gesammelt?
-
Besteht für die Nutzer ein Anreiz, das System absichtlich zu täuschen (z.B. entwickeln Spammer raffiniertere Nachrichten, wenn ihre ursprünglichen Nachrichten vom Spamfilter abgefangen werden)?
-
Gibt es eine Möglichkeit, das System erst zu überwachen und trotzdem einen Mehrwert zu generieren (z.B. mit einer “Human in the Loop” Lösung), statt vom ersten Tag an voll auf ML zu setzen?
-
-
Gibt es rechtliche oder ethische Bedenken beim Einsatz der Lösung?
-
Verbietet irgendeine Verordnung, zum Beispiel das EU-Gesetz über künstliche Intelligenz (EU AI Act), den Einsatz von ML für diese Anwendung?
-
Gibt es datenschutzrechtliche Bedenken, zum Beispiel weil personenbezogene Daten verwendet werden?
-
Müssen die Entscheidungen des ML-Modells transparent und nachvollziehbar sein, z.B. wenn jemandem aufgrund eines algorithmisch generierten Kreditscores ein Kredit verweigert wird?
-
Besteht die Gefahr, dass das Modell Nutzer diskriminieren könnte, beispielsweise weil es mit verzerrten Daten trainiert wurde?
-
-
Was könnte sonst noch schief gehen?
-
Warum könnten die Nutzer von der Lösung frustriert sein? An welcher Stelle würden sie z.B. lieber mit einem echten Menschen statt einem Chatbot interagieren?
-

Selbst bauen oder einkaufen?
-
Kernbereich vs. generische Anwendung: Schafft diese Lösung einen strategischen Vorteil?
Wird die Lösung ein wichtiger Bestandteil eures Geschäfts sein, z.B. ein neues Feature, das euer Produkt attraktiver macht und/oder erfordert die Lösung spezifisches Domänenwissen, das nur in eurer Organisation verfügbar ist, z.B. weil du Daten analysierst, die von euren eigenen speziellen Prozessen/Maschinen generiert werden? Oder ist dies ein allgemeines (aber komplexes) Problem, für das es bereits eine Lösung gibt (z.B. als Software-as-a-Service (SaaS)-Produkt), die ihr von der Stange kaufen könntet?
Beispielsweise ist das Extrahieren der relevanten Informationen aus gescannten Rechnungen zur Automatisierung von Buchhaltungsprozessen eine relativ komplexe Aufgabe, für die es bereits viele gute Lösungen gibt. Wenn du nicht gerade in einem Unternehmen arbeitest, das Buchhaltungssoftware entwickelt, und ihr plant, eine bessere Alternative zu diesen vorhandenen Lösungen zu verkaufen, ist es wahrscheinlich nicht sinnvoll, dies selbst zu implementieren. -
Besitzt ihr die nötige technische Expertise und Wissen im Anwendungsbereich, um die Lösung selbst zu implementieren?
-
Wie schwierig wäre es, die ML-Lösung selbst zu implementieren? Welche Open-Source-Bibliotheken gibt es, die eine solche Aufgabe lösen?
-
Verfügt eure Organisation über das nötige ML-Talent? Falls nicht könnte auch eine hybride Entwicklung zusammen mit einer Universität oder Forschungsinstitution oder externen Beratern möglich sein.
-
-
Was wäre der Return on Investment (ROI) einer eingekauften Lösung?
-
Wie zuverlässig ist die eingekaufte ML-Lösung? Gibt es Benchmarks und/oder könnt ihr sie mit einigen gängigen Beispielen und Randfällen selbst testen?
-
Wie aufwändig wäre die Vorverarbeitung eurer Daten um die eingekaufte ML-Lösung zu verwenden?
-
Wie kompliziert wäre es, die Outputs der eingekauften ML-Lösung in euer System zu integrieren? Macht diese Lösung genau das, was ihr braucht, oder wären zusätzliche Nachbearbeitungsschritte erforderlich?
-
Kann die eingekaufte ML-Lösung intern deployed werden oder läuft sie auf einem externen Server und würde dies Datenschutzprobleme mit sich bringen?
-
Wie hoch sind die laufenden Lizenzgebühren und was ist in der Wartung enthalten (z.B. wie oft werden die Modelle nachtrainiert)?
Sofern die ML-Lösung kein integraler Bestandteil eures Geschäftsmodells sein wird, wird es am Ende wahrscheinlich darauf hinauslaufen, die internen Kosten für die Entwicklung, Implementierung, den Betrieb und die Wartung des Systems mit den Kosten für die Integration der Standardlösung in euren bestehenden Arbeitsablauf (einschließlich der erforderlichen Datenvorverarbeitung) und den laufenden Lizenzgebühren zu vergleichen.
-
Für weitere Informationen lies diesen Blog Artikel.
2. Entwickle eine Lösung
Sobald ein geeignetes “Input → Output”-Problem identifiziert wurde, müssen historische Daten gesammelt und der richtige ML-Algorithmus ausgewählt und angewendet werden, um eine funktionierende Lösung zu erhalten. Darum geht es in den nächsten Kapiteln.
Um ein konkretes Problem mit ML zu lösen, gehen wir in der Regel wie folgt vor:
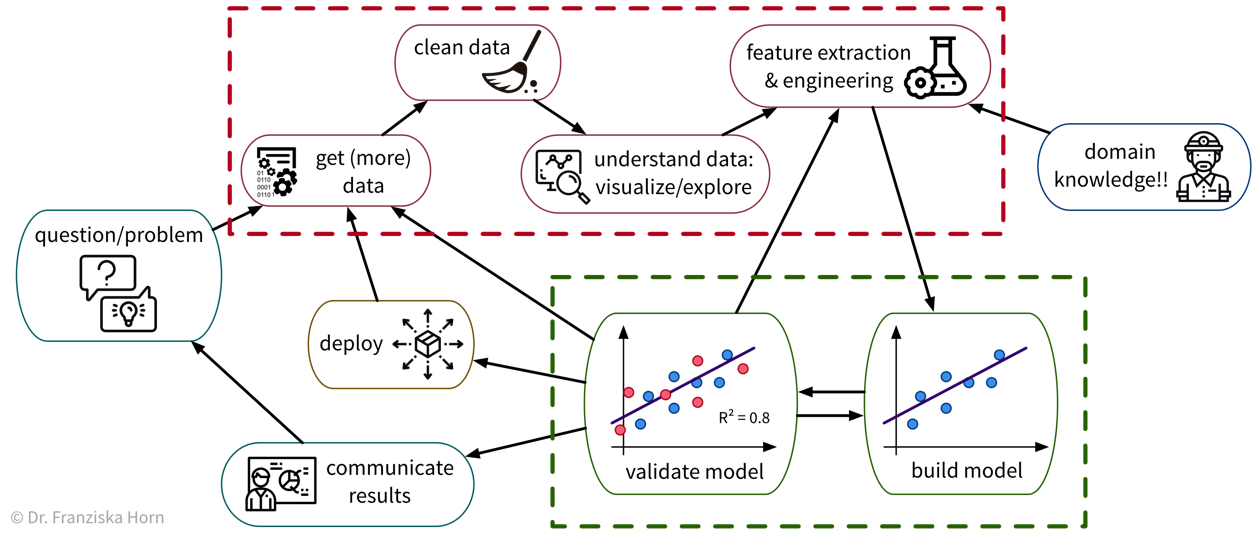
Da viele Unternehmen keine standardisierte Dateninfrastruktur besitzen, ist die traurige Wahrheit leider, dass eine Data Scientistin normalerweise (mindestens) etwa 90% ihrer Zeit damit verbringt, die Daten zu sammeln, zu bereinigen und anderweitig vorzuverarbeiten, um sie in ein Format zu bringen worauf die ML-Algorithmen angewendet werden können:
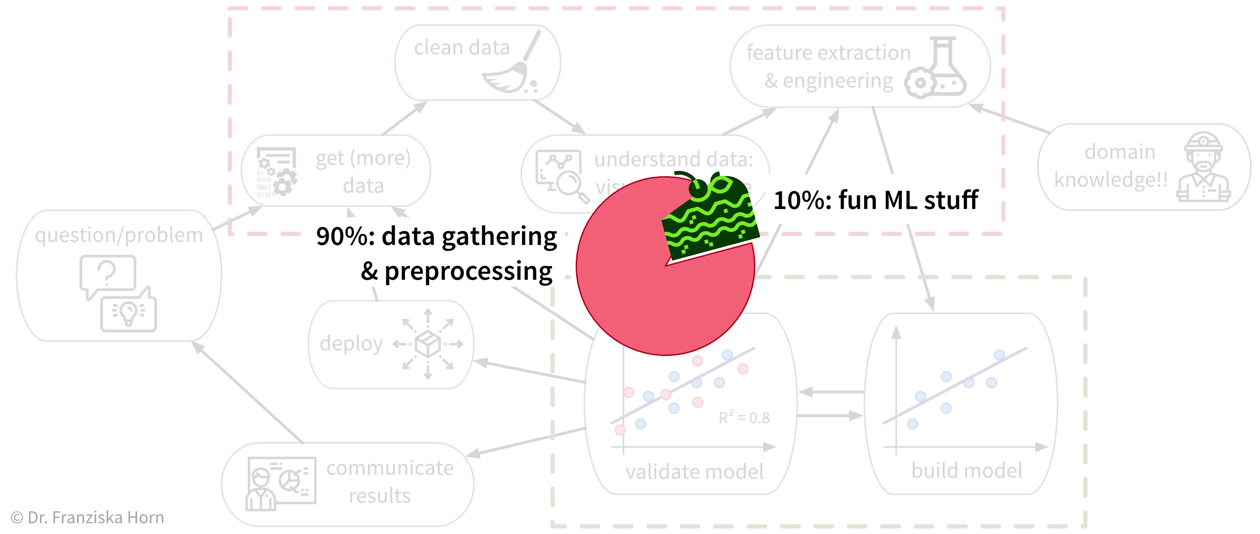
Auch wenn es manchmal frustrierend ist, ist die Zeit, die man mit der Bereinigung und Vorverarbeitung der Daten verbringt, nie verschwendet, da die ML-Algorithmen nur mit einer soliden Datengrundlage brauchbare Ergebnisse erzielen können.
3. Setze die Lösung ein
Wenn die prototypische Lösung implementiert ist und das geforderte Performance-Level erfüllt, muss diese Lösung dann “deployed” werden, d.h. produktiv in den allgemeinen Workflow und die Infrastruktur integriert werden, damit sie in der Praxis tatsächlich zur Verbesserung des jeweiligen Prozesses eingesetzt werden kann (als Software, die kontinuierlich Vorhersagen für neue Datenpunkte macht). Das könnte auch den Bau zusätzlicher Software rund um das ML-Modell erfordern, wie etwa eine API, um das Modell programmatisch abzufragen, oder eine dedizierte Benutzeroberfläche, um mit dem System zu interagieren. Schließlich gibt es im Allgemeinen zwei Strategien, wie die fertige Lösung betrieben werden kann:
-
Das ML-Modell läuft auf einem “Edge-Gerät”, d.h. auf jedem einzelnen Gerät (z.B. Smartphone), das Inputdaten erzeugt und die Ergebnisse des Modells im nachfolgenden Prozessschritt verwendet. Dies ist oft die beste Strategie, wenn Ergebnisse in Echtzeit berechnet werden müssen und/oder eine durchgehende Internetverbindung nicht gewährleistet ist, wie z.B. bei selbstfahrenden Autos. Der Nachteil dieser Strategie ist jedoch, dass je nach Art des ML-Modells vergleichsweise teure Rechenressourcen in jedes Gerät eingebaut werden müssen, z.B. GPUs für neuronale Netze.
-
Das ML-Modell läuft in der “Cloud”, d.h. auf einem zentralen Server, z.B. in Form einer Webanwendung, die Daten einzelner Nutzer entgegennimmt, verarbeitet und die Ergebnisse zurücksendet. Dies ist oft die effizientere Lösung, wenn für den Anwendungsfall eine Antwort innerhalb weniger Sekunden ausreicht. Die Verarbeitung personenbezogener Daten in der “Cloud” kann jedoch Datenschutzbedenken mit sich bringen. Einer der Hauptvorteile dieser Lösung besteht darin, dass man das ML-Modell einfacher aktualisieren kann, sobald mehr historische Daten verfügbar werden oder wenn sich der Prozess ändert und das Modell nun mit leicht anderen Eingaben umgehen muss (worauf wir in späteren Kapiteln noch ausführlicher eingehen).
→ Da diese Entscheidungen stark vom spezifischen Anwendungsfall abhängen, sprengen sie den Rahmen dieses Buches. Suche online nach “MLOps” oder ließ das Buch Designing Machine Learning Systems, um mehr über diese Themen zu erfahren und beauftrage eine:n Machine Learning oder Data Engineer, um die erforderliche Infrastruktur im Unternehmen einzurichten.