Information Retrieval (Similarity Search)
The goal of information retrieval is to identify similar items given some query:
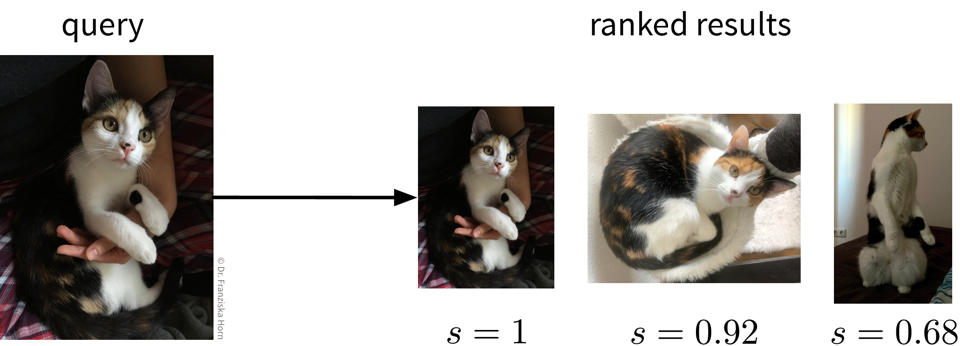
This can be accomplished by building a nearest neighbors search tree (i.e., just like for the k-nearest neighbors algorithm, only that here we return the neighbors directly instead of using them to predict the label for the new data point).
from sklearn.neighbors import NearestNeighborsBut of course, the success of this approach is again highly dependent on being able to compute meaningful similarities between the data points. For text datasets, information retrieval often works quite well by using simple TF-IDF feature vectors together with a cosine similarity, however, for images, for example, out-of-the-box similarity measures that operate directly on the original input features (i.e., pixel values) are only able to identify images with similar colors, not necessarily similar content (e.g., an image showing a black cat would be more similar to an image showing a black dog than a white cat). To get around this problem, we could use neural networks to obtain a more informative feature representation, with which it is then easier to compute meaningful semantic similarities.