ML for Data Scientists Workshop
This course is aimed at practitioners, who want to analyze data with machine learning algorithms.
The four-week workshop follows a "flipped classroom" format, where the participants study the theory and solve the exercises at their own speed and the results are then discussed in the group sessions.
Learning Outcomes
- Understand the fundamentals of machine learning.
- Overview of the most important machine learning algorithms and what needs to be considered when using them.
- First practical experience in the application of machine learning algorithms by solving a variety of exercises.
- Basic knowledge of the central tools of the Python data science ecosystem (numpy, scipy, matplotlib, pandas, scikit-learn, pytorch/keras).
Prerequisites
- Good command of the English language (all materials are in English)
- Math skills at university entrance level (especially linear algebra: matrices & vectors, functions)
- Good programming skills (ideally using Python)
- Intrinsically motivated to learn new things
- Desirable: First practical experience analyzing data
- Technical requirements: Python installation on your own computer or access to a cloud environment, where you can run Jupyter notebooks (e.g., Google Colab)
- Complete the Preparation part before the first group session (about 20min; see below)
Agenda
The course consists of six group sessions, where we discuss questions and results, and a self-study part before each group session, where you read through the chapters of the book, take notes in the workbook, test yourself with short quizzes, and work through the programming exercises. Your answers to the questions in the workbook are the basis for the group discussions.
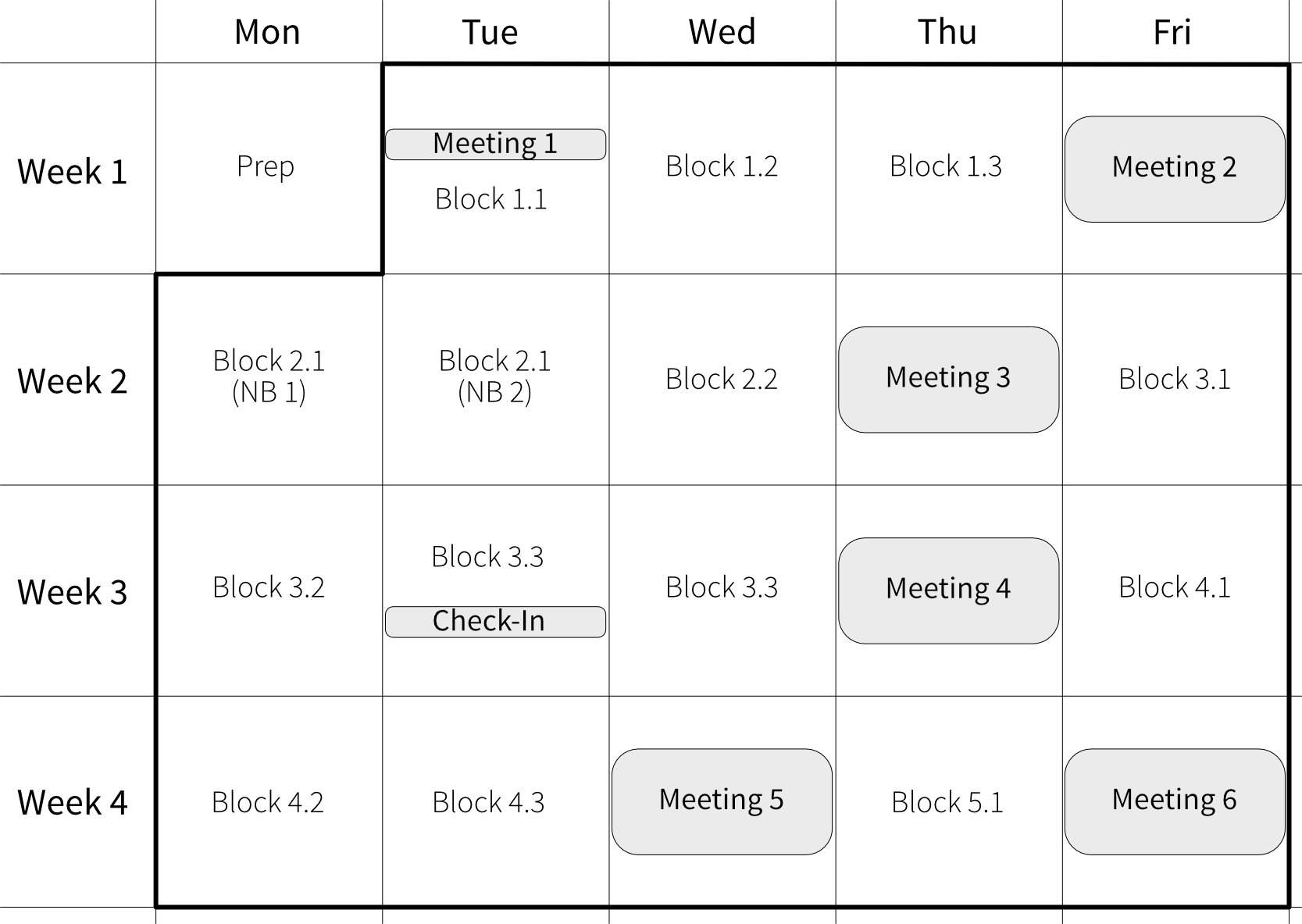
Important: While this course is meant to be taken in parallel to your normal job, you should block at least three hours in your calendar each day for the self-study blocks to make sure you have enough time to work through all of the materials and come prepared to the group discussions. Please complete the Preparation part before the first group session!
The group sessions take place remotely via Microsoft Teams, Google Meet, Zoom, Slack, or similar. Please join the calls with your camera turned on so the sessions feel a bit more personal.
How to get the most out of this course
Think of the questions in the workbook as questions an interested colleague might ask you after the course. Following the Feynman Technique, try to explain what you've learned in your own words, which is the easiest way to identify any gaps in your knowledge.
Don't try to memorize any facts, but instead connect them with what you already know and make sure you understand the "why" behind the answers.
And if anything seems confusing, please make a note of it and ask in the next meeting!
Preparation before the course (~20min)
- Read the first chapter of the book: "Introduction"
- Answer the first questions in the workbook [docx]
1st Group Session (~1h):
- Introduction
- Discuss the first workbook questions from the preparation part
- Distribution of topics for the ML use cases spotlight presentations
Self-Study Part 1: What is ML?
Block 1.1:
- Read the chapter: "The Basics"
- Again, don't forget to take notes in the workbook [docx]
- Answer Quiz 1 (also available as a pdf in case you can't access Google Forms)
- Answer Quiz 2 [pdf]
Block 1.2:
- Read the chapter: "ML with Python"
- Complete the Python tutorial
Block 1.3:
- Answer Quiz 3 [pdf]
- Prepare a 90-second Spotlight presentation [de] for one of the given ML use cases
- Read the chapter: "Data Analysis & Preprocessing"
2nd Group Session (~3h):
- Discuss workbook questions
- Spotlight presentations
Self-Study Part 2: Your first algorithms
Block 2.1:
- Read the chapter: "Unsupervised Learning"
- Work through Notebook 1: visualize text (after the section on dimensionality reduction)
- Work through Notebook 2: image quantization (after the section on clustering)
Block 2.2:
- Read the chapter: "Supervised Learning Basics"
- Answer Quiz 4 [pdf]
3rd Group Session (~3h):
- Discuss workbook questions & notebooks
Self-Study Part 3: Avoiding common pitfalls
Block 3.1:
- Read the chapter: "Supervised Learning Models"
- In parallel, work through the respective sections of Notebook 3: supervised comparison
Block 3.2:
- Read the chapter: "Avoiding Common Pitfalls"
- Work through Notebook 4: analyze toy dataset
Block 3.3:
- Case Study! Work through Notebook 5: quality prediction. Plan at least 4 hours for this! And feel free to work in pairs, especially if you're still new to Python.
- Schedule at least 1 check-in session with me to discuss your progress and make sure you're on the right track (after working about 1-2 hours on the case study)
- You might also want to have a look at the cheat sheet, which includes a summary of the most important steps when developing a machine learning solution, incl. code snippets
4th Group Session (~3h):
- Discuss workbook questions
- 2-3 people present their case study results
Self-Study Part 4: Advanced topics
Block 4.1:
- Start reading the chapter "Advanced Topics" up to and including the section: "Deep Learning"
- Work through Notebook 6: MNIST with torch (recommended) or MNIST with keras (in case others in your organization are working with TensorFlow)
Block 4.2:
- Read the sections: "Information Retrieval (Similarity Search)" and "Recommender Systems (Pairwise Data)" and refresh your memory on TF-IDF feature vectors and the cosine similarity (see: Data Preprocessing: Working with Text Data)
- Work through Notebook 7: information retrieval
Block 4.3:
- Read the last sections of the chapter "Advanced Topics": "Time Series Forecasting" and "Reinforcement Learning"
- Work through Notebook 8: RL gridmove
5th Group Session (~3h):
- Discuss workbook questions & exercise from notebook 6
Self-Study Part 5: Conclusion
Block 5.1:
- Answer Quiz 5 [pdf]
- Read the chapter: "Conclusion"
- Complete the exercise: "Your next ML Project" [de] (aim for a 5 minute presentation)
- Please fill out the Feedback Survey to help me further improve this course! :-)
6th Group Session (~3h):
- Discuss workbook questions
- ML project idea presentations