Solving problems with ML
Solving “input → output” problems with ML requires three main steps:
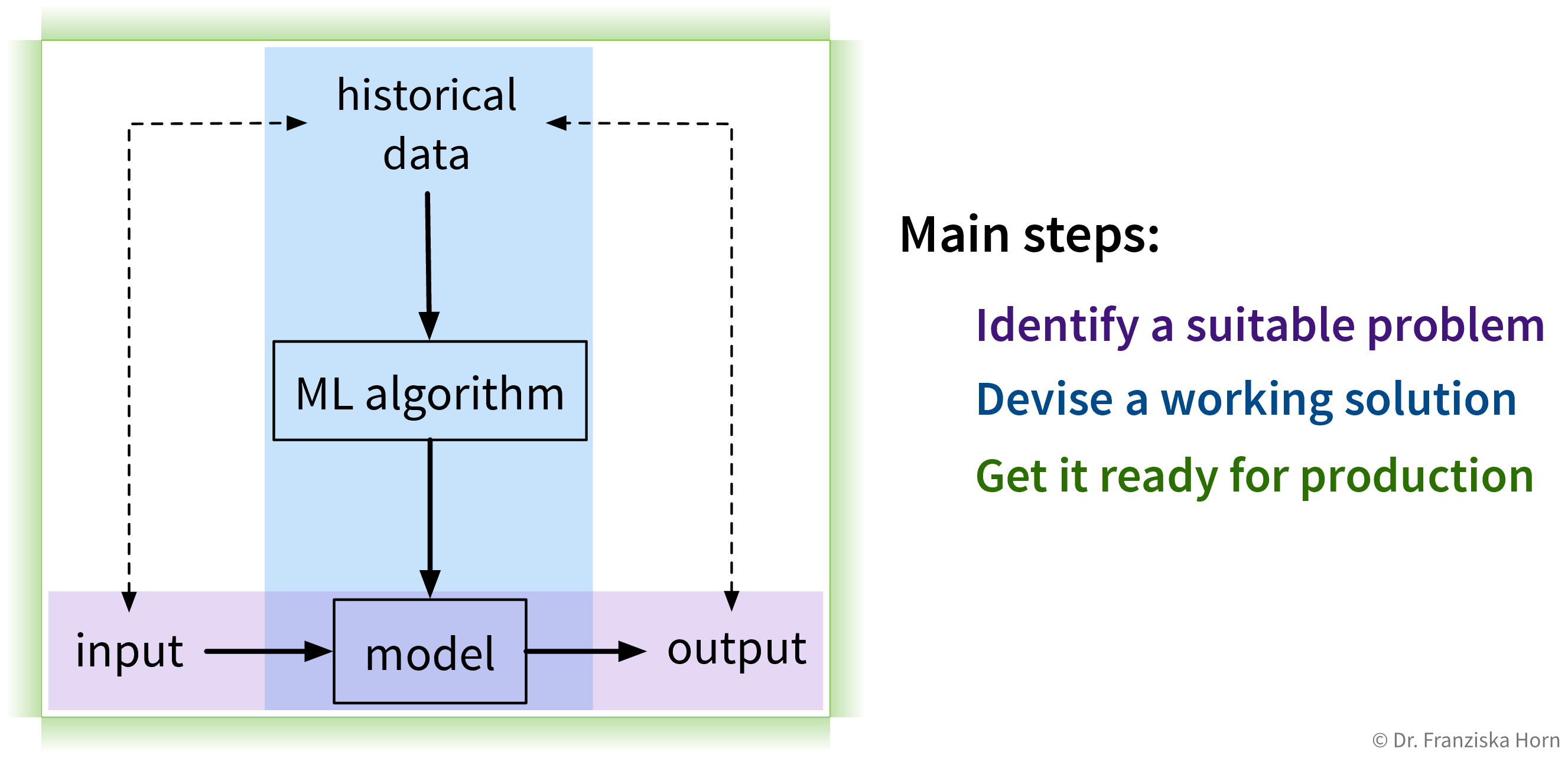
1. Identify a suitable problem
The first (and arguably most important) step is to identify where machine learning can (and should) be used in the first place.
ML project checklist
Motivation
-
What problem do you want to solve?
Machine learning can help you in various ways by generating insights from large amounts of (possibly unstructured) data, improving decision making and planning processes by providing predictions about future events, or automating tedious tasks otherwise requiring human experts.
Where do you see a lot of inefficiencies around you that could be mitigated by a better use of data? For example, you could look for opportunities to decrease wasted resources / time / costs or increase revenue / customer satisfaction / etc.
To systematically identify problems or opportunities, it can be helpful to create a process map or customer journey map. -
In what way(s) would this generate value for your organization?
How could your organization make money on this or reduce costs?-
Could this improve an internal process (e.g., maybe a process can be run more efficiently with the insights from an analysis or a tedious task that would otherwise require a human worker can be automated using an ML model)?
-
Could the ML model be integrated as a new feature within an existing product and thereby, e.g., make this product more appealing to customers?
-
Could the ML solution be sold as an entirely new product or service, e.g., offered as a Software-as-a-Service (SaaS) solution?
Please note that how the ML solution will be used in the end might also be a strategic decision that can be different for every organization. For example, an ML solution that recognizes scratches in produced products might be used by one company to improve their internal production process, while another company that produces the machines that make the products could integrate this as a new feature in their machines, and a third company might offer this as a SaaS solution compatible with different production lines.
-
-
How much value could this project generate?
Think of the impact in terms of-
Magnitude: Small improvement or revolution? Will the solution result in a strategic advantage?
-
Scale: How often will this be used? How many users/customers/employees will benefit?
For example:
-
Small process optimization, but since this process is used everyday in the whole organization it saves countless hours
-
New feature that revolutionizes the product and sets you apart from the competition, but the market for it is tiny
-
-
Would this have any valuable side effects? What will be different? Any additional opportunities that could arise from this? Can you create synergies between departments that work with similar data?
-
-
How do you know you’ve accomplished your goal?
What would success look like, i.e., what’s your definition of ‘done’?-
Can you quantify the progress towards your goal with a KPI?
-
What is the status quo, i.e., how far are you from your goal right now? What is your target?
-
Which metrics should not change (i.e., get worse) due to this project?
-
Solution Outline
-
What is your vision for the future with ML?
-
What does your existing process / system look like and how will it be different after you integrate the ML solution?
-
Who are the users and how will they be affected by this change, e.g., will they require additional training to use the new system?
-
-
What are the deliverables?
Does the solution consist of a piece of software that is deployed somewhere to continuously make predictions for new data points, or are you more interested in the insights gained from an one-off analysis of historical data? -
In case of a software solution, how will the ML model be integrated with the existing setup?
-
What does one interaction with the system look like (= 1 data point / sample / observation), e.g., a user making a request or a produced product passing a quality checkpoint?
-
Where are the inputs for the ML model coming from? What happens to the outputs of the ML model?
-
Do you need an additional user interface (UI) or API to interact with the ML model?
-
Does the ML model need to make predictions instantly as new data comes in or can it process data asynchronously in batches? What is the expected traffic (i.e., number of data points that need to be processed per second)?
-
How should the ML model be deployed (e.g., cloud, on-premise, or edge device)? Does this require any additional infrastructure or special hardware (e.g., GPUs)?
-
Model maintenance: What are the plans w.r.t. pipelines for future data collection, model monitoring, and automated retraining?
-
-
What is the input data? What should the outputs look like?
-
What kind of inputs does the ML model receive (e.g., image / text / sensor measurements / etc.)?
-
What kind of outputs should the ML model produce, i.e., which category of ML algorithms solves this kind of problem?
-
Do you already have access to an initial dataset to train the model?
-
-
How will you evaluate the performance of the ML model?
-
What evaluation metric is appropriate for the type of ML use case (e.g., accuracy)?
-
How does this evaluation metric relate to the business KPI this solution is supposed to improve?
-
How can the performance of the model be monitored during operation? Is new labeled data continuously collected for this purpose?
-
-
Is there a simpler solution, i.e., without using ML?
Use ML to learn unknown, complex rules from data.-
Even if ML is the right choice here, could you build a minimal viable product without ML to already validate the solution as a whole before investing in ML?
-
Challenges & Risks
-
Is there enough high-quality data available to train and evaluate the model?
-
Quality: Do you have the right inputs and unambiguous labels?
→ Ask a subject matter expert whether she thinks all the relevant input data is available to compute the desired output. This is usually easy to determine for unstructured data such as images — if a human can see the object in the image, ML should too. But for structured data, such as a spreadsheet with hundreds of columns of sensor measurements, this might be impossible to tell before doing any analysis on the data. -
Quantity: How much data was already collected (including rare events and labels)? How long would it take to collect more data? Could additional data be bought from a vendor and if yes, how much would this cost?
-
How difficult is it to get access to all of the data and combine it neatly in one place? Who would you talk to, to set up / improve the data infrastructure?
-
How much preprocessing is necessary (e.g., outlier removal, fixing missing values, feature engineering, i.e., computing new variables from the existing measurements, etc.)? What should be the next steps to systematically improve data quality and quantity and decrease preprocessing requirements in the future?
-
-
Can the problem be solved with an existing ML algorithm?
Ask an ML expert whether a similar problem has already been solved before.-
For known solutions: How complex is it to get the model working (e.g., linear regression vs. deep neural network)?
-
For unknown solutions: Instead of spending years on research to come up with a novel algorithm, is it possible to break the input-output problem down into simpler subproblems with known solutions?
-
-
What would be the worst case scenario when the model is wrong?
Your ML system (like humans) will make mistakes. Do not use ML if you always need 100% correct results!-
What level of performance do you need at least for the ML solution to be valuable? E.g., what false positive or false negative rates are you willing to tolerate? Is the desired performance realistic with the given data? What would be the worst case scenario when the model produces wrong predictions and how much risk are you willing to take?
-
What is the chance of the input data changing over time, e.g., because of changing user demographics or black swan events like a pandemic (e.g., COVID-19)? How often would you need to retrain the model to compensate for these drifts and do you collect new (labeled) data quickly enough to do this?
-
Do users have an incentive to intentionally deceive the system (e.g., spammers who come up with more sophisticated messages if their original ones are caught by the spam filter; adversarial attacks)?
-
Instead of going all in with ML from day 1, is there a way your system can be monitored in the beginning while still providing added value (i.e., human-in-the-loop solution)?
-
-
Are there any potential legal issues or ethical concerns?
-
Is the use of ML prohibited for this kind of application by some regulation, e.g., the EU AI Act?
-
Are there any concerns w.r.t. data privacy, e.g., because you are relying on personally identifiable information (PII)?
-
Do the decisions of the ML model need to be transparent and explainable, e.g., if someone is denied credit because of an algorithmically generated credit score?
-
Is there a risk of model discrimination, e.g., because the model is potentially trained on systematically biased data?
-
-
What else could go wrong?
-
Why might users get frustrated with the solution? For example, when might they prefer to interact with a real human instead of a chatbot?
-

Build or Buy?
-
Core vs. generic domain: Does this create a strategic advantage?
Will the solution be a key part of your business, e.g., a new feature that makes your product more attractive, and/or does it require unique subject matter expertise only available at your organization, e.g., because you’re analyzing data generated by your own specific processes/machines? Or is this a common (but complex) problem, for which a solution already exists (e.g., offered as a Software-as-a-Service (SaaS) product), that you could buy off the shelf?
For example, extracting the relevant information from scanned invoices to automate bookkeeping processes is a relatively complex task for which many good solutions already exist, so unless you are working in a company building bookkeeping software and plan to sell a better alternative to these existing solutions, it probably doesn’t make sense to implement this yourself. -
Do you have the required technical and domain know-how to build this yourself?
-
How difficult would it be to implement the ML solution yourself? For example, what kind of open source libraries already exist that could be used to solve such a task?
-
Do you have the necessary ML talent? If not, you could also consider a hybrid approach where you partner with an academic institution or external consultants.
-
-
What is the return on investment (ROI) for an off-the-shelf solution?
-
How reliable is the off-the-shelf ML solution? Are there any benchmarks available and/or can you test it with some common examples and edge cases yourself?
-
How much effort would be required in terms of preprocessing your data before you could use the off-the-shelf ML solution?
-
How difficult would it be to integrate the output from the off-the-shelf ML solution into your general workflow? Does it do exactly what you need or would additional post-processing steps be required?
-
Can the off-the-shelf ML solution be deployed in-house or does it run on an external server and would this bring with it any data privacy issues?
-
How high are the on-going licensing fees and what is included in terms of maintenance (e.g., how frequently are the models retrained)?
Unless the ML solution will be an integral part of your business, in the end it will probably come down to comparing costs for developing, implementing, running, and maintaining the system yourself vs. costs for integrating the off-the-shelf solution into your existing workflow (incl. necessary data preprocessing) and on-going licensing fees.
-
For more details check out this blog article.
2. Devise a working solution
Once a suitable “input → output” problem as been identified, historical data needs to be gathered and the right ML algorithm needs to be selected and applied to obtain a working solution. This is what the next chapters are all about.
To solve a concrete problem using ML, we follow a workflow like this:
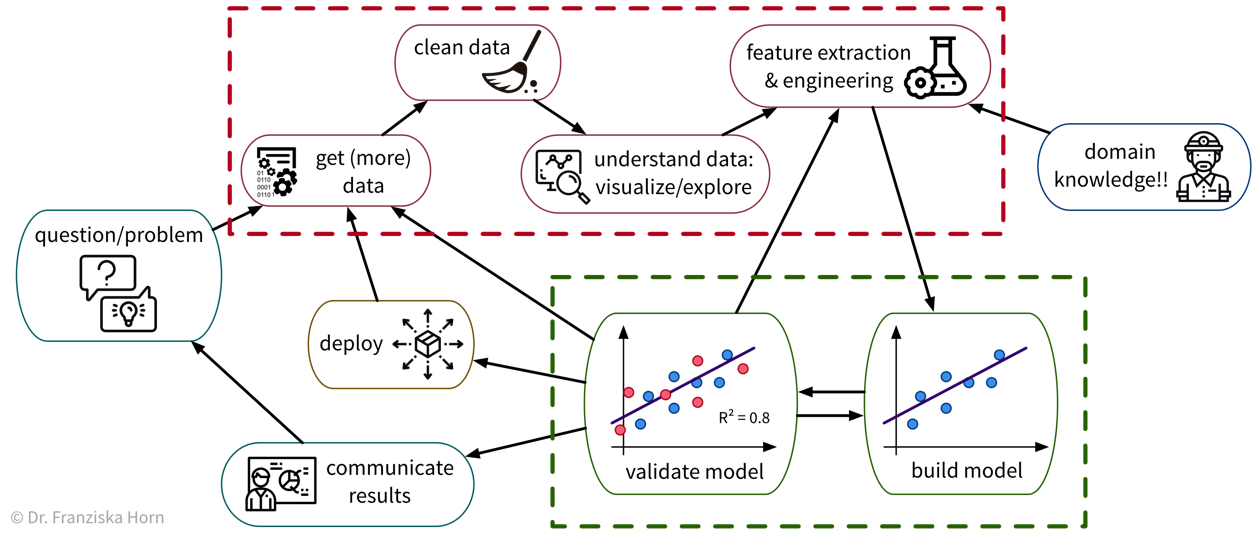
Unfortunately, due to a lack of standardized data infrastructure in many companies, the sad truth is that usually (at least) about 90% of a Data Scientist’s time is spent collecting, cleaning, and otherwise preprocessing the data to get it into a format where the ML algorithms can be applied:
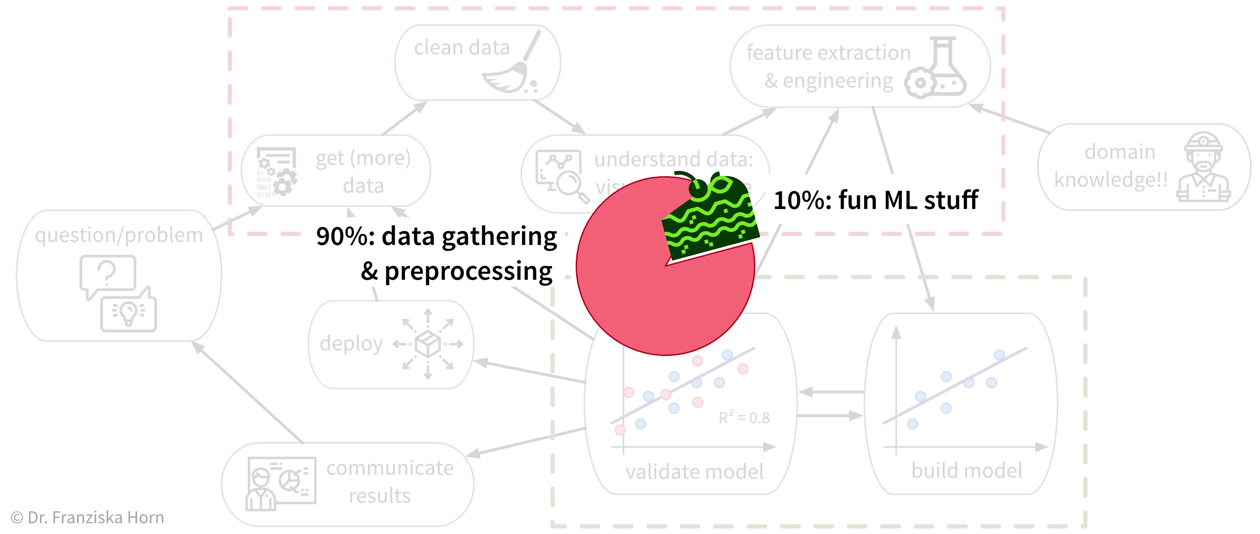
While sometimes frustrating, the time spent cleaning and preprocessing the data is never wasted, as only with a solid data foundation the ML algorithms can achieve decent results.
3. Get it ready for production
When the prototypical solution has been implemented and meets the required performance level, this solution then has to be deployed, i.e., integrated into the general workflow and infrastructure so that it can actually be used to improve the respective process in practice (as a piece of software that continuously makes predictions for new data points). This might also require building some additional software around the ML model such as an API to programmatically query the model or a dedicated user interface to interact with the system. Finally, there are generally two strategies for how to run the finished solution:
-
The ML model runs on an “edge” device, i.e., on each individual machine (e.g., mobile phone) where the respective data is generated and the output of the model is used in subsequent process steps. This is often the best strategy when results need to be computed in real time and / or a continuous Internet connection can not be guaranteed, e.g., in self-driving cars. However, the downside of this is that, depending on the type of ML model, comparatively expensive computing equipment needs to be installed in each machine, e.g., GPUs for neural network models.
-
The ML model runs in the “cloud”, i.e., on a central server (either on-premise or provisioned from a cloud provider such as AWS), e.g., in the form of a web application that receives data from individual users, processes it, and sends back the results. This is often the more efficient solution, if a response within a few seconds is sufficient for the use case. However, processing personal information in the cloud also raises privacy concerns. One of the major benefits of this solution is that it is easier to update the ML model, for example, when more historical data becomes available or if the process changes and the model now has to deal with slightly different inputs (we’ll discuss this further in later chapters).
→ As these decisions heavily depend on your specific use case, they go beyond the scope of this book. Search online for “MLOps” or read the book Designing Machine Learning Systems to find out more about these topics and hire a machine learning or data engineer to set up the required infrastructure in your company.